核心問題很根本: 你怎麼知道自己用 AI Agent 寫程式的能力有在進步? 影片開宗明義就說「If you don’t measure it, you will not be able to improve it」— 如果不衡量,就無法進步。很多人用 Agent 還停留在「開一個終端機跑一個 prompt」的階段,但其實已經可以開始思考怎麼規模化了。像 Claude Code 的作者 Boris Cherny,預設就開 5 個 Agent 並行跑。
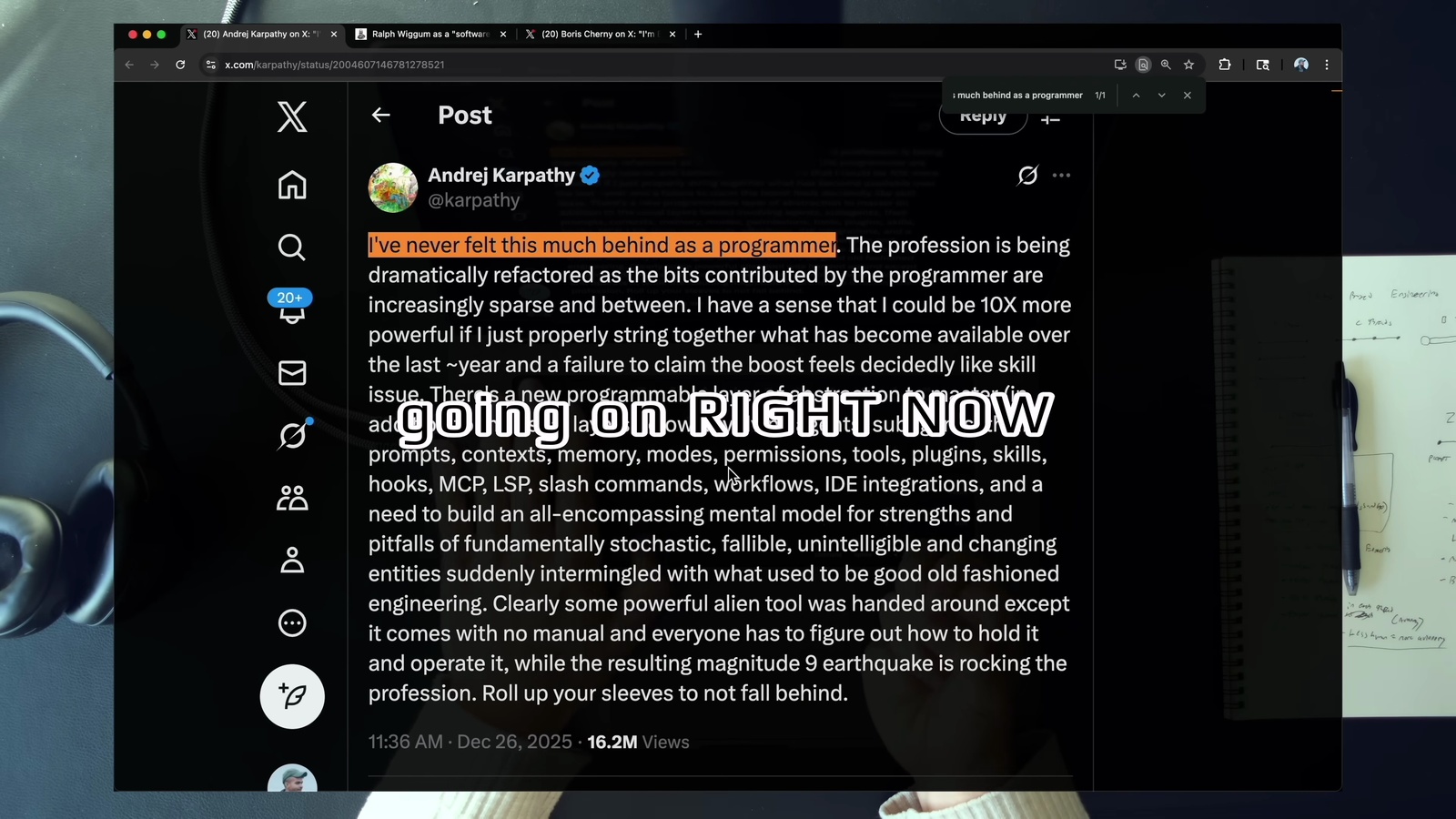
連 Andrej Karpathy 都發文說「I’ve never felt this much behind as a programmer」。影片也點出一個正在擴大的鴻溝: 有在用 Agent 的工程師和還沒跟上的工程師之間,差距越拉越開。用 Agent 做工程確實是一個全新技能,需要新的框架來衡量進展。
以下是重點整理:
1. 什麼是 Thread?
一個「Thread」就是一個工作單元,由你和你的 Agent 共同驅動。結構很單純:
提示 → Agent 工作 (工具呼叫) → 審查
你在開頭下指令或做規劃,中間 Agent 透過一連串工具呼叫執行工作,最後你審查驗證結果。每次你在終端機按下 Enter 開始跑一個 prompt,就是啟動了一條 thread。
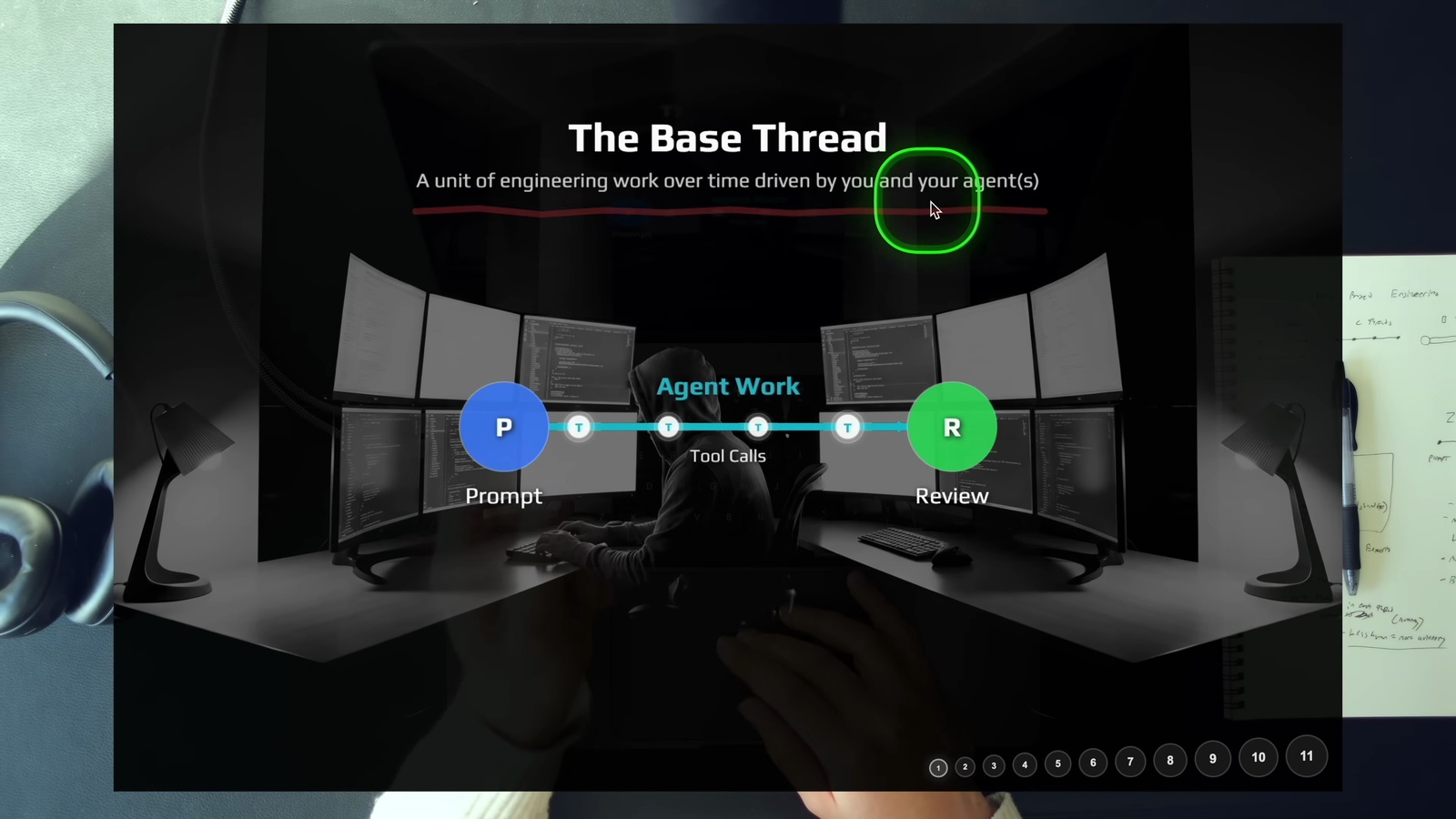
核心洞見是: Agent 的價值可以用「工具呼叫次數」來衡量。在 2023 年以前,我們自己就是那些工具呼叫 — 自己讀程式碼、自己寫程式碼、自己查資料。現在工程師的角色轉變了,我們出現在 thread 的頭和尾: 下指令和做審查。
2. P-Thread: 平行執行
有了一條 thread 之後,下一步就是 — 開更多條。
P-Thread (平行 Thread) 就是同時跑多條 thread。你可以在多個終端機視窗、git worktree 或雲端沙盒中同時啟動不同的 Agent 工作。
Claude Code 的創造者 Boris Cherny 就是這樣操作的。他在 X 上分享了自己的設定: 在終端機裡跑 5 個 Claude Code (分頁編號 1 到 5),加上在 Claude Code 網頁介面再跑 5-10 個背景 session。等於他隨時有 10-15 條 thread 在運作。
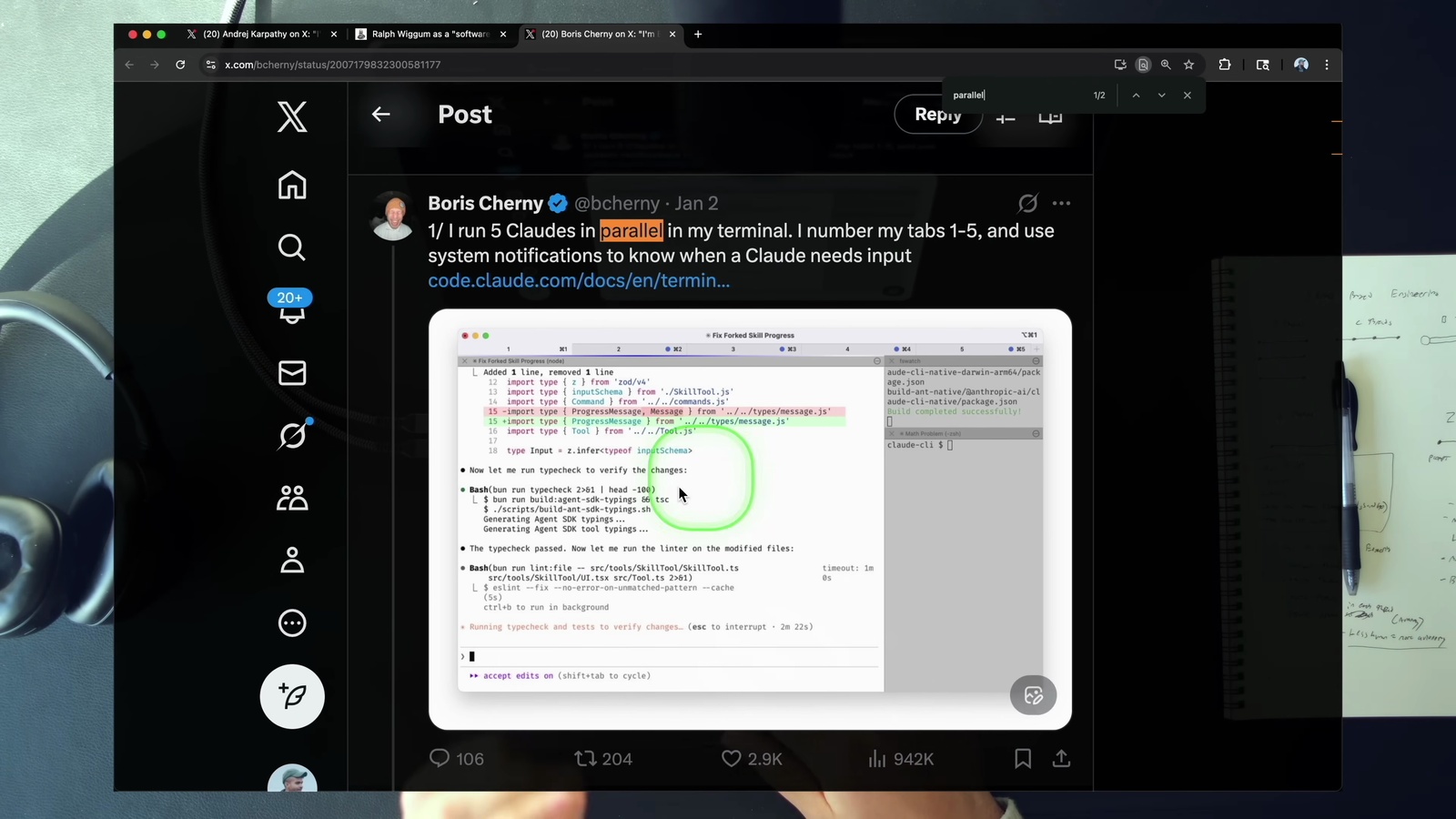
道理很直覺: 同時跑五個 Agent 的工程師,產出就是比只跑一個的多。如果你現在還在一次只盯一個 Agent,那可能是時候多開幾個視窗了。不過影片也提醒: 如果你連一個 Agent 都要一直盯著看,那先別急著開更多,先把單一 thread 的品質穩定下來再說。
P-Thread 除了讓不同 Agent 做不同任務,也可以讓多個 Agent 跑同一個 prompt 來提高信心 — 這其實就是通往下面 F-Thread 的橋樑。
3. C-Thread: 鏈式分段執行
如果有一個很大的任務,比如資料庫遷移或高風險的正式環境部署呢? C-Thread (鏈式 Thread) 就是把工作切成多個階段,每完成一段就停下來審查,確認沒問題再繼續下一段。
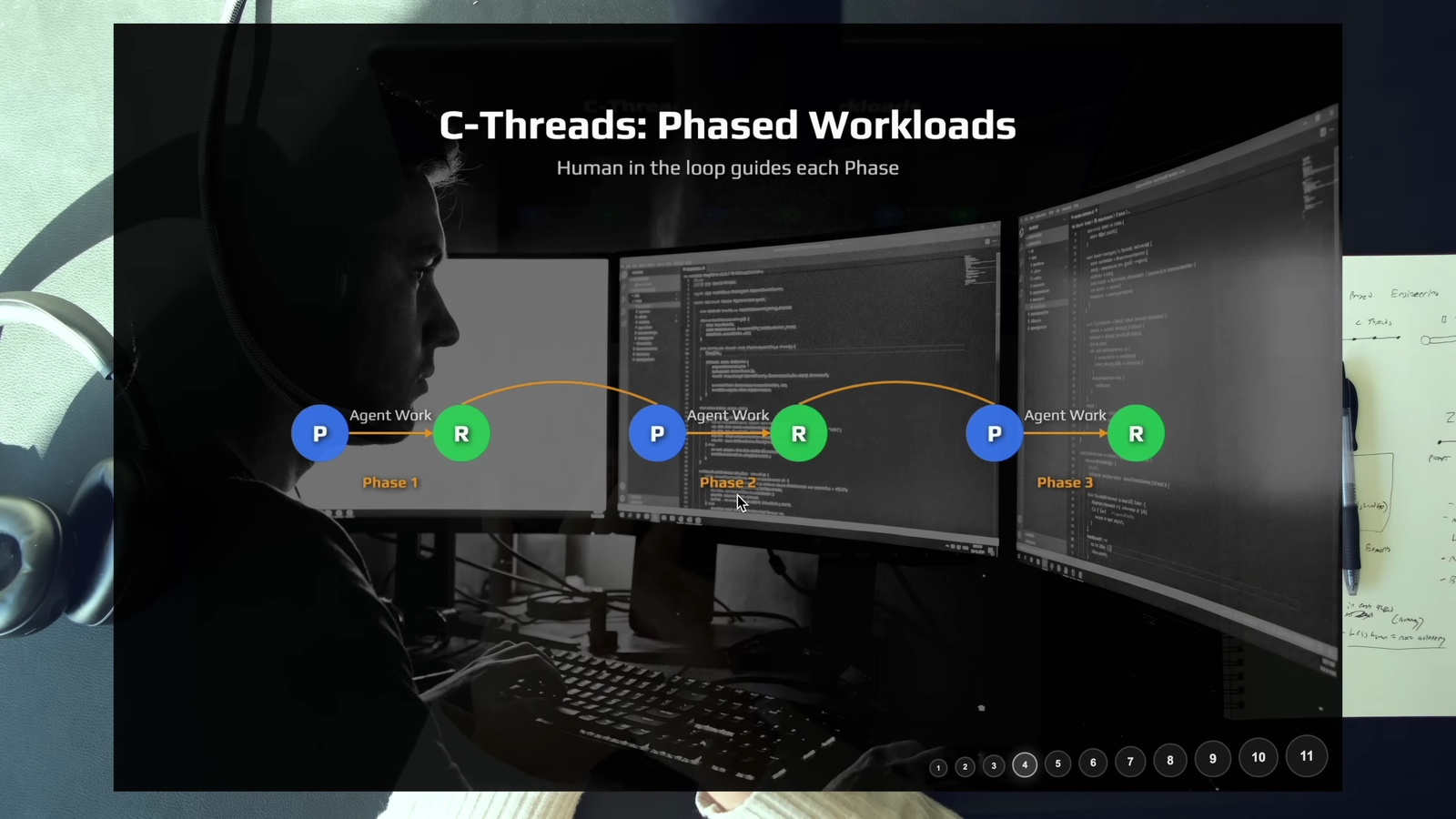
影片特別強調: 這些中途檢查點不是因為 Agent 搞砸了才要停下來看 — 那叫做「bad agentic coding」。C-Thread 是刻意把工作分段,適用兩個場景:
- 工作量超過單一 Agent 的上下文視窗
- 高風險的正式環境操作,需要每一步都確認正確
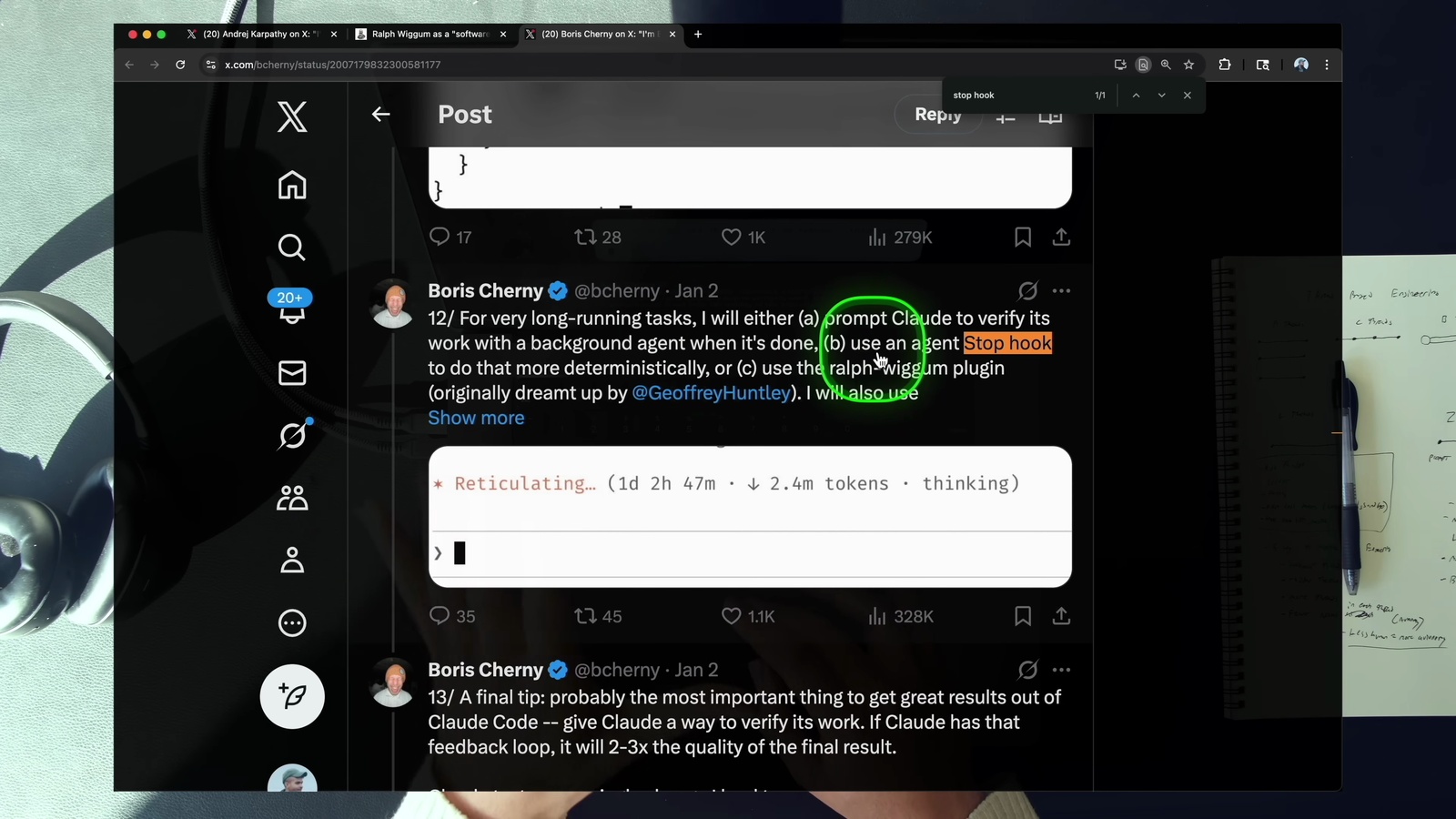
Claude Code 裡有「詢問使用者」工具讓 Agent 在工作中途停下來問你問題,加上系統通知,可以很自然地實現 C-Thread。Boris 也提到他會用系統通知來知道 Agent 什麼時候需要輸入。影片作者自己甚至寫了一個 text-to-speech hook,讓 Agent 完成一段工作後用語音通知他,這樣就可以隨時跳回來繼續下一段。
不過 C-Thread 有個取捨: 你花的時間和精力。不是所有工作都需要分段,如果不需要,用基本的 Base Thread 就好。
4. F-Thread: 融合取最佳
這是影片作者最愛的一種 thread — 融合 Thread。
概念很簡單: 把同樣的 prompt 丟給多個 Agent,然後比較結果,挑最好的或融合起來。用影片的話說就是「just take more shots at the problem」— 多試幾次,成功率自然上去。這就是「Best of N」模式的完整版 — 不只是比較單一回答,而是比較多條完整的 Agent 工作鏈結果。而且不一定要選「最好的一個」,有時候從多個結果中各取所長 (cherry-pick) 再組合,效果更好。
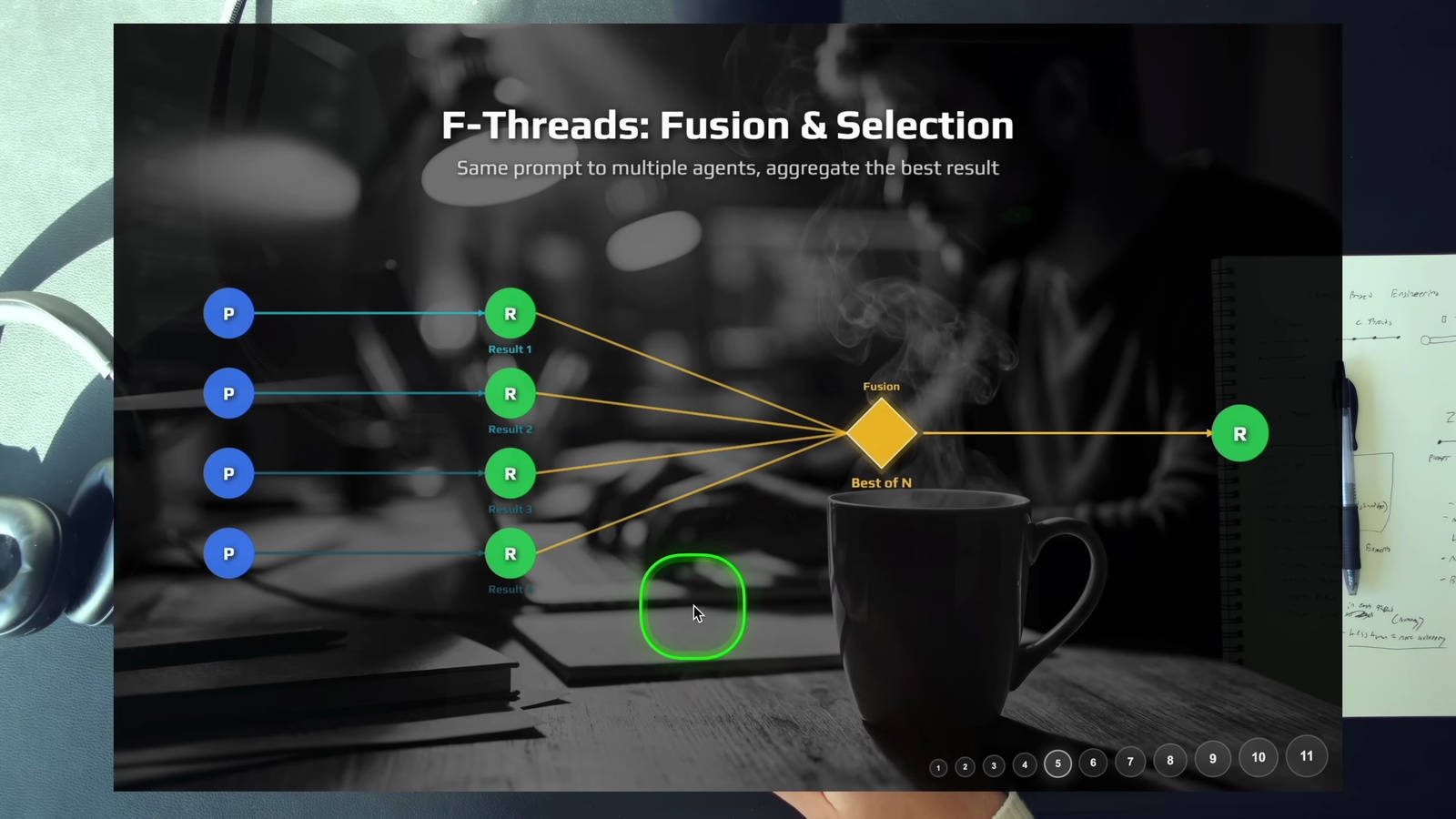
實際操作: 同時啟動 9 個 Agent (比如 3 個 Claude Code、3 個 Gemini、3 個 Codex),讓它們各自跑同一個任務,再從中挑選或合併最佳方案。
背後的邏輯是: 投入更多算力來換取更高的信心。問一個 Agent 一個問題,它給你一個答案。問五個 Agent 同一個問題,如果四個給了一樣的答案,你就能更有把握。其實 Research Agent (像 Deep Research 類的產品) 就是融合 Thread 的典型應用 — 用多個子代理做多路搜尋,最後彙整結果。
影片作者甚至斷言: 未來的快速原型開發都會用融合 Thread 來做。小編覺得蠻合理的,尤其是做原型設計時,多版本比較再融合,確實比單線迭代更有效率。
5. B-Thread: 巢狀結構
B-Thread (大型 Thread) 是一個後設結構 — 你的 Agent 會去啟動其他 Agent。關鍵本質是: 你有一個 Agent 在幫你寫 prompt。
最常見的例子就是子代理: 你下一個 prompt,主 Agent 拆解任務後分派給多個子代理去執行。或者更進一步,有個協調者 Agent 負責指揮一整個團隊: 規劃 → 偵查 → 建置 → 審查 → 預備部署,最後你才進來做最終審查。
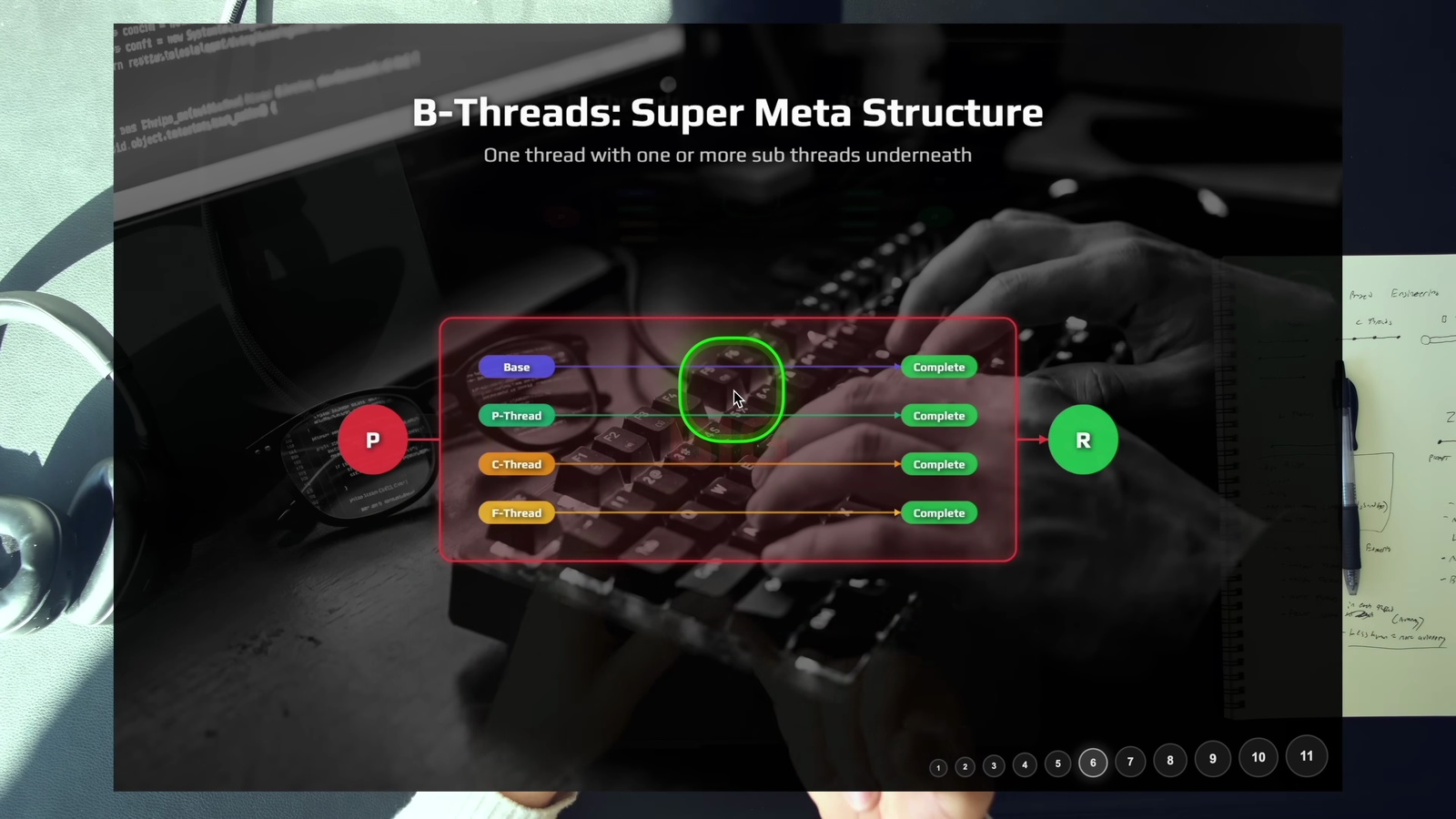
從你的角度看,B-Thread 跟 Base Thread 長一樣 — 提示開頭、審查結尾。差別在於中間「厚度」不同,裡面塞了一堆嵌套的 thread 在跑。
B-Thread 之所以重要,是因為它把你推向「程式碼 + Agent」的組合,而這個組合的回報遠大於純 Agent。這也呼應了最近很紅的 Ralph Wiggum 模式: Agent + 確定性程式碼的組合,比純 Agent 更強。透過 stop hook,Agent 在嘗試結束時會被攔截,跑一段驗證程式碼,不通過就繼續迭代。這讓 Agent 能持續運作直到真正完成任務。
6. L-Thread: 超長自主運行
L-Thread (長程 Thread) 就是讓 Agent 跑很長很長的時間,高自主、不中斷。Boris Cherny 就秀過一個跑了 1 天 2 小時的 session,2.4M token。
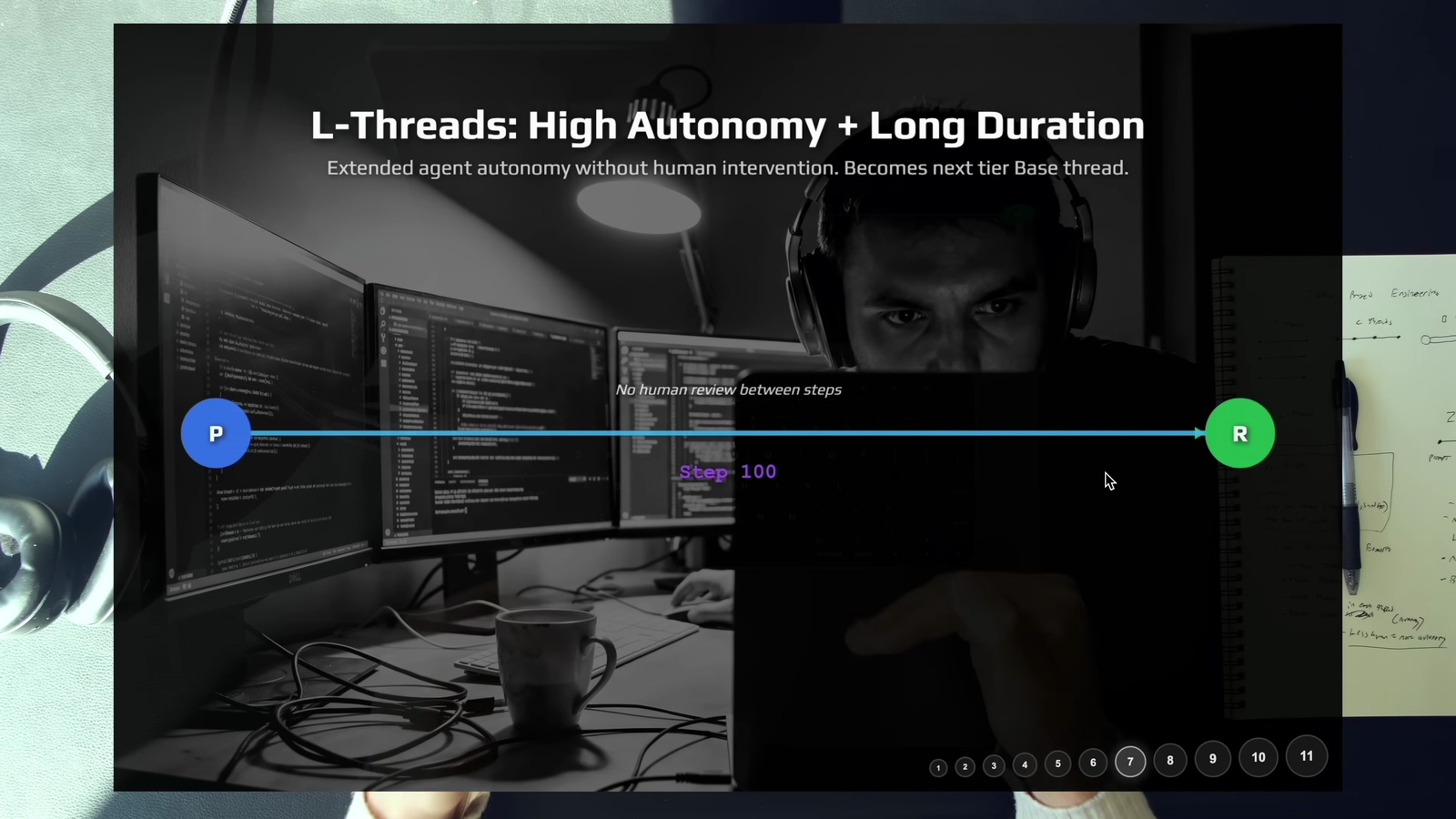
L-Thread 其實就是 Base Thread 的進化版 — 形狀一樣,只是更長、更多工具呼叫、更多自主權。能跑更長的 thread 意味著你在影片所說的「核心四要素」— 上下文、模型、提示、工具 — 這四個基本面都在進步。更好的提示工程、更好的上下文管理、更強的模型,才能撐住更長的自主運行。影片點出一個很棒的洞見: 「great planning is great prompting」— 好的規劃本身就是好的提示工程,這是能讓 Agent 長時間自主運行的關鍵。
Boris 在長時間任務中的做法是: (a) 完成後用背景 Agent 驗證結果 (其實就是 C-Thread),(b) 用 stop hook 做確定性驗證,或 (c) 使用 Ralph Wiggum 插件。核心就是給 Agent 一個自我驗證的回饋迴路。
Stop hook 的運作流程值得說明一下: Agent 嘗試結束工作 → stop hook 攔截 → 跑一段你寫的決策程式碼 (例如檢查進度檔、執行驗證指令) → 如果沒過就讓 Agent 繼續跑,過了才真正結束。這就是「確定性程式碼 + Agent」的威力所在。
7. 四個衡量進步的維度
知道了六種 thread 之後,怎麼判斷自己有沒有在進步? 影片給出四個具體方向:
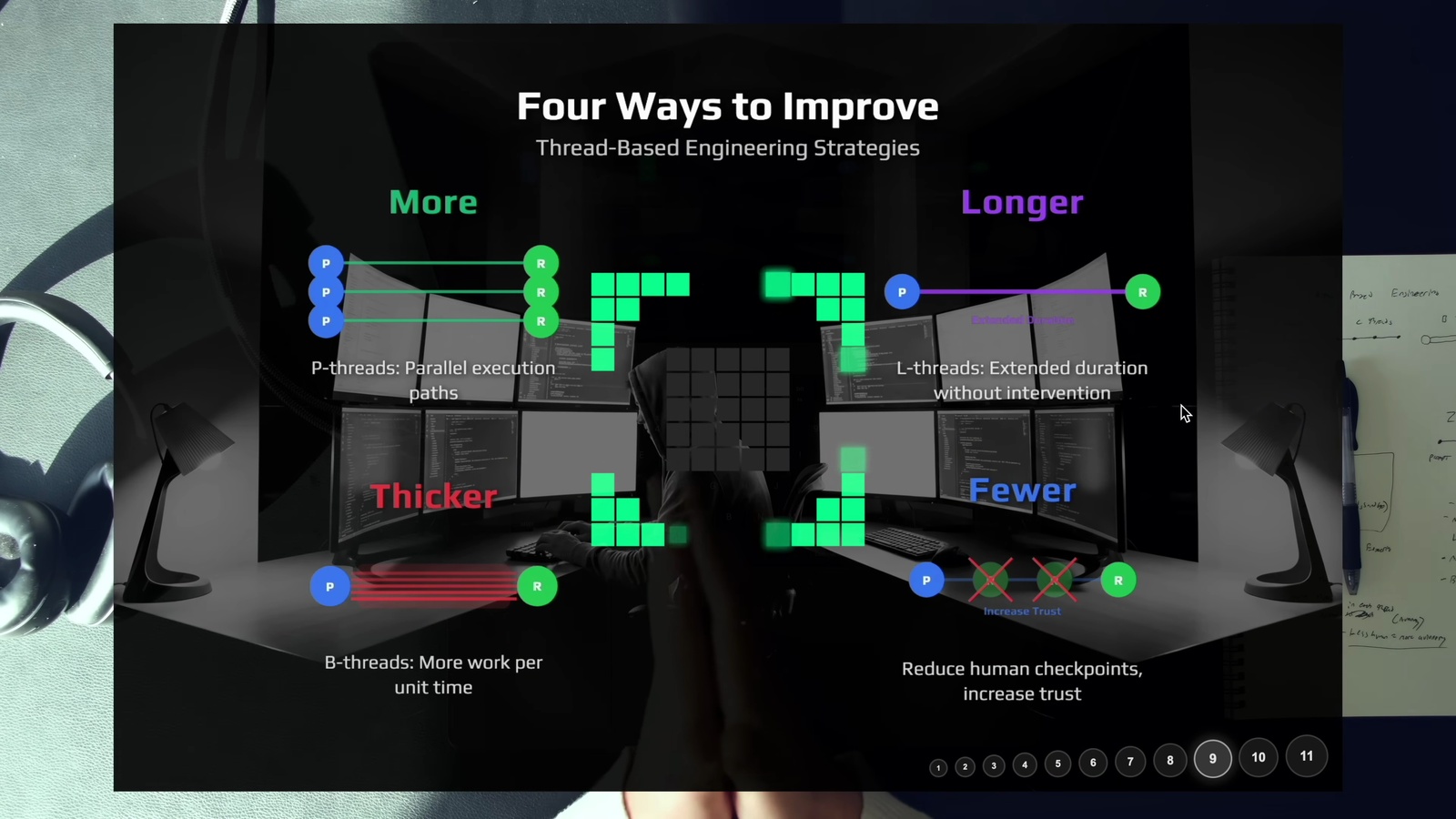
- 更多: 從一次跑一個 Agent,到同時跑 5 個、10 個 — 平行化你的工作
- 更長: 讓 Agent 自主運行更長時間,執行更多工具呼叫
- 更厚: 用嵌套的子代理、協調者讓單一 thread 裡面塞更多工作
- 更少介入: 建立更高的信任度,減少人工審查的次數
Boris 的設定就是這四個維度的最佳示範: 5 個終端機 + 5-10 個網頁 session 就是「更多」,長時間運行就是「更長」,他最後一條建議「give Claude a way to verify its work」就是在推進「更少介入」。他也區分了「in-loop」(終端機裡即時互動) 和「out-of-loop」(網頁介面,可以走開讓它跑) 兩種使用模式,兩者搭配才能最大化產出。
其他值得注意的 Boris 設定細節: 他一律使用 Opus 模型、不用 dangerously skip permissions 而是設定具體的權限規則、會維護 CLAUDE.md 但不讓它太大。影片也提到一個進階觀點: 對於你的正式產品程式碼庫,值得投入時間打造專屬的 Agent 層 — 讓專門的 Agent 操作專門的程式碼庫,解決特定的問題。
8. 終極目標: Z-Thread
最後影片提到一個終極目標: Z-Thread (零接觸 Thread) — 完全不需要審查。
影片特別強調: 這不是 vibe coding。Vibe coding 是不看程式碼、不在乎品質。Z-Thread 恰好相反 — 不是不看程式碼,而是你知道不需要看,因為你已經建立了足夠的信任機制。這是用 Agent 做工程的最終形態,最大化信任。
影片描繪了一條清晰的進化路徑: 一開始你只會在一個終端機裡跑一條短短的 thread → 然後像 Boris 一樣開 5 個終端機加 5-10 個背景 session → 接著讓 thread 變得更厚 (嵌套子代理) → 再讓它們跑得更長 → 最終推向 Z-Thread。
這聽起來可能有點激進,但方向是對的: 我們一直在朝著「建立系統化的信任機制」前進。從手動審查每一行程式碼,到信任有完整測試覆蓋的 CI pipeline,到信任有自我驗證迴路的 Agent — 這條路一直在走。
延伸閱讀: Simon Willison 的多 Agent 並行實戰心得
講完理論框架,也推薦 Simon Willison 這篇 Embracing the parallel coding agent lifestyle,他從一個原本對多 Agent 並行持懷疑態度的人,分享了自己實際跑起來之後的心得。幾個蠻有啟發的觀點:
瓶頸是審查,不是生成。 Simon 說得很直白: 「I can only focus on reviewing and landing one significant change at a time.」Agent 生成速度超快,但你審查的頻寬是有限的。所以並行的重點不是讓 10 個 Agent 同時寫程式碼,而是在你專心審查一個的時候,讓其他幾個在背景跑著準備好。
什麼任務適合丟出去並行? 他分了四類:
- 研究 / 概念驗證: 純研究,不改正式程式碼。例如「Yjs 能不能搭 Python backend 做協作編輯?」Agent 可以直接 checkout 那些 repo 讀原始碼來研究
- 理解現有系統: 讓 Agent 追蹤整個程式碼庫回答問題,例如「我們的 signed cookies 在哪設定和讀取的?」這些筆記存起來還能當未來 prompt 的上下文
- 小型維護: 測試跑出 deprecation warning? 丟給一個 Agent 去修,你繼續做你的事
- 有明確規格的實作: 先想清楚怎麼做,寫好詳細規格再丟給 Agent。他強調: 確認程式碼是否符合你寫好的規格,比審查一份你事先沒規劃、Agent 自由發揮的程式碼快得多
偵察 Agent: 用算力換情報。 這是 Josh Bleecher Snyder 提出的「Send out a scout」做法,Simon 實測後大力推薦。面對困難任務,先派一個 Agent 去嘗試,但你根本不打算用它寫的程式碼。你要看的是: 它改了哪些檔案 (知道問題涉及哪些模組)、它怎麼處理問題 (了解可能的解法方向)、它在哪裡卡住 (知道難點在哪)。拿到偵查結果後再寫一個更精確的 prompt 正式開工,成功率高很多。小編覺得這個做法跟上面 F-Thread 的精神很像 — 都是用算力換取更好的結果。
工具組合。 他目前混用 Claude Code、Codex CLI、Codex Cloud (可從手機啟動非同步任務),不同工具負責不同類型的工作。隔離方式也很簡單: 直接在 /tmp 開一個全新的 checkout。
以上,小編覺得「Thread-Based Engineering」這個框架蠻實用的,把模糊的「用 Agent 用得好不好」具體化成可衡量的維度。
如 Ming Cheng Ho 說的: 「未來的時代,對概念的理解然後轉化成可穩定規模化執行的能力會是下一個世代工作者的挑戰。穩定,然後可規模化。」這個框架正好提供了一個從穩定 (Base Thread) 到規模化的具體路徑。核心概念蠻簡單: 一切都回歸到上下文、模型、提示、工具這四個基本元素。你能跑更多 thread、更長的 thread、更厚的 thread、更少的人工介入,就代表你在這四個面向都在進步。
Boris Cherny 的分享也很有參考價值 — 他的設定說白了就是原版 Claude Code,沒太多花俏的自訂。最關鍵的一句話: 「give Claude a way to verify its work — it will 2-3x the quality of the final result」。讓 Agent 有辦法自我驗證,結果品質直接翻倍,這才是最值得投入的方向。
影片最後的收尾也很有力: 「If you want to scale your impact, you must scale your compute.」想要放大你的影響力,就必須放大你的算力。
]]>





































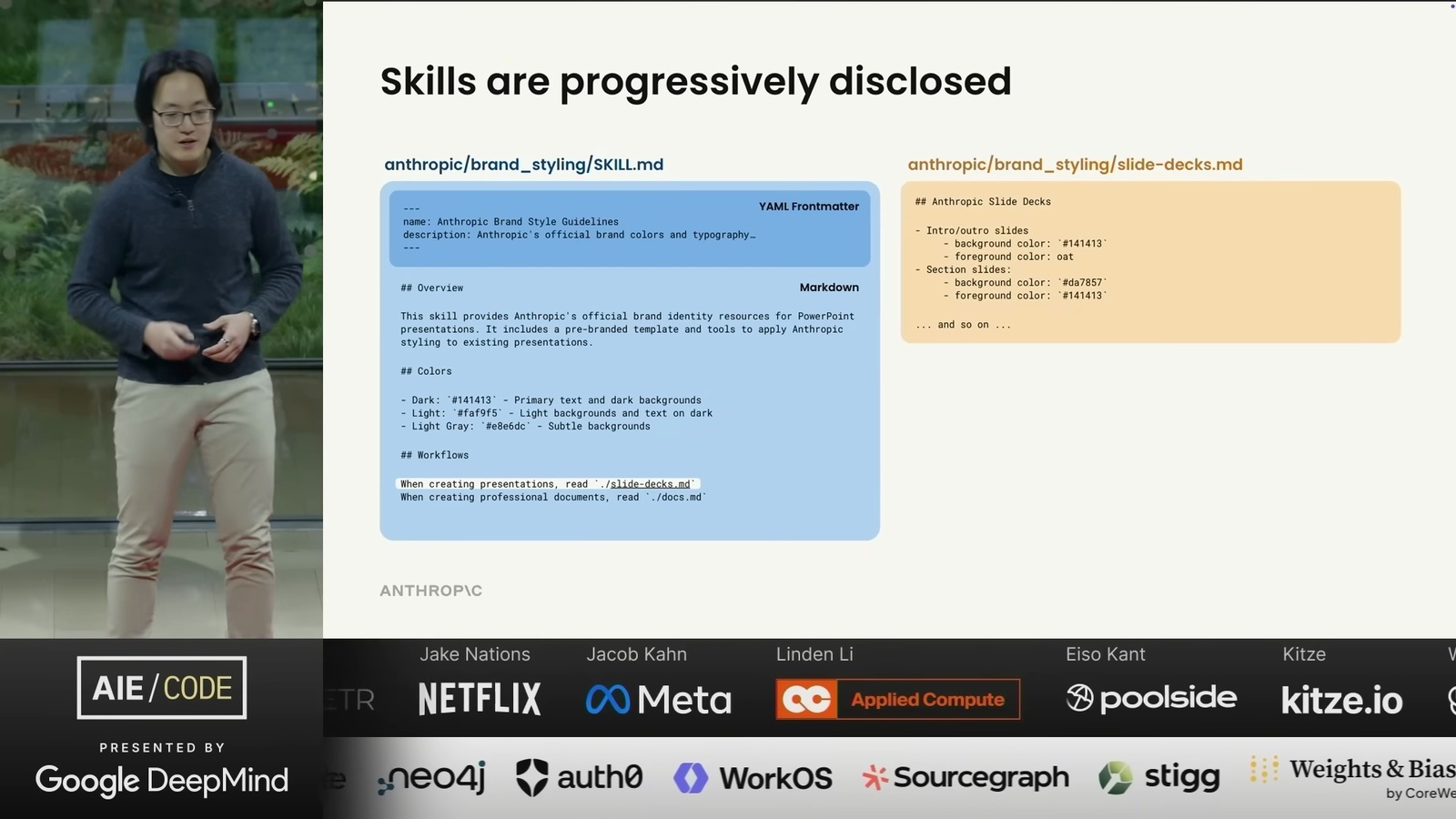



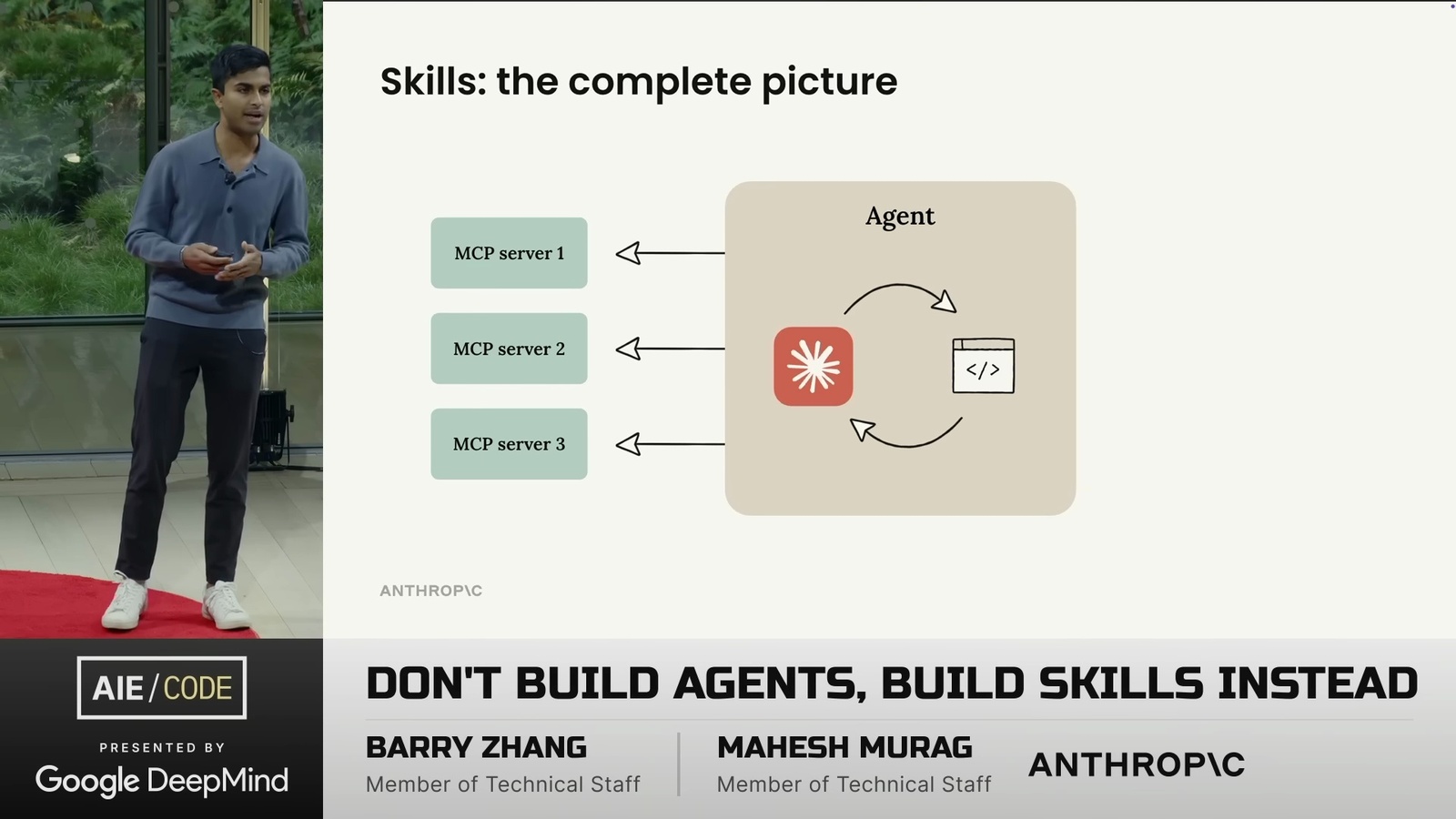
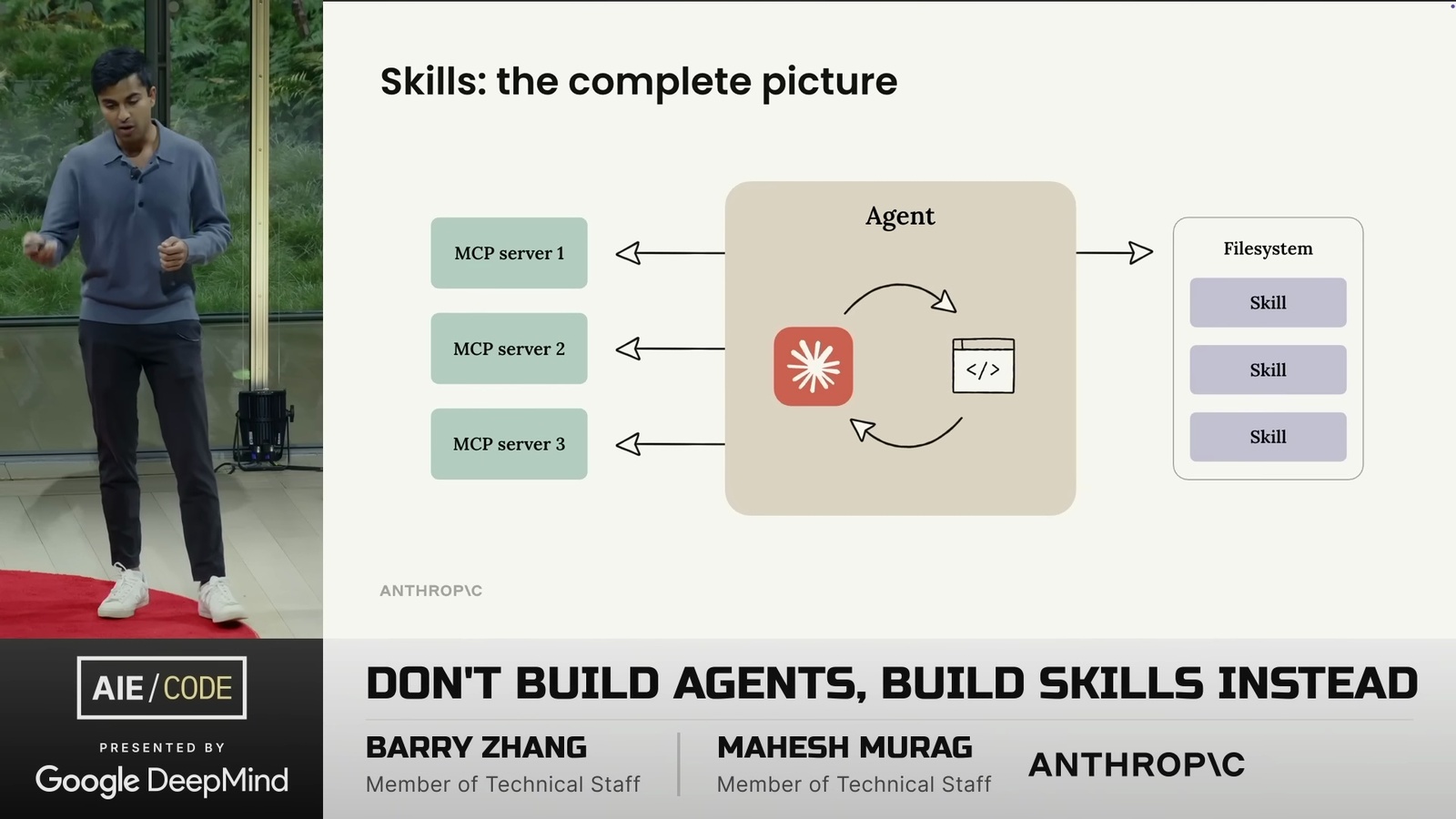


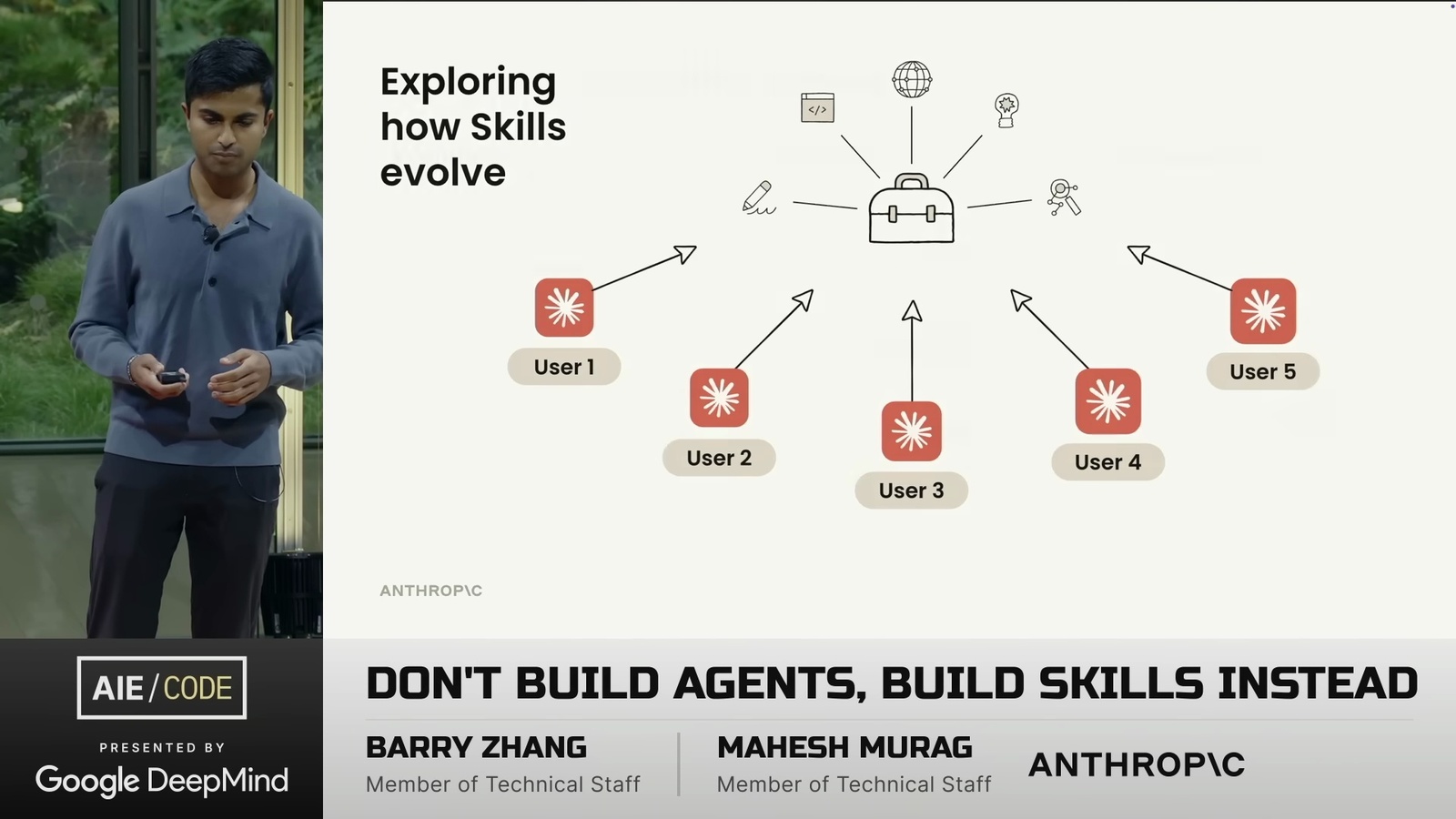

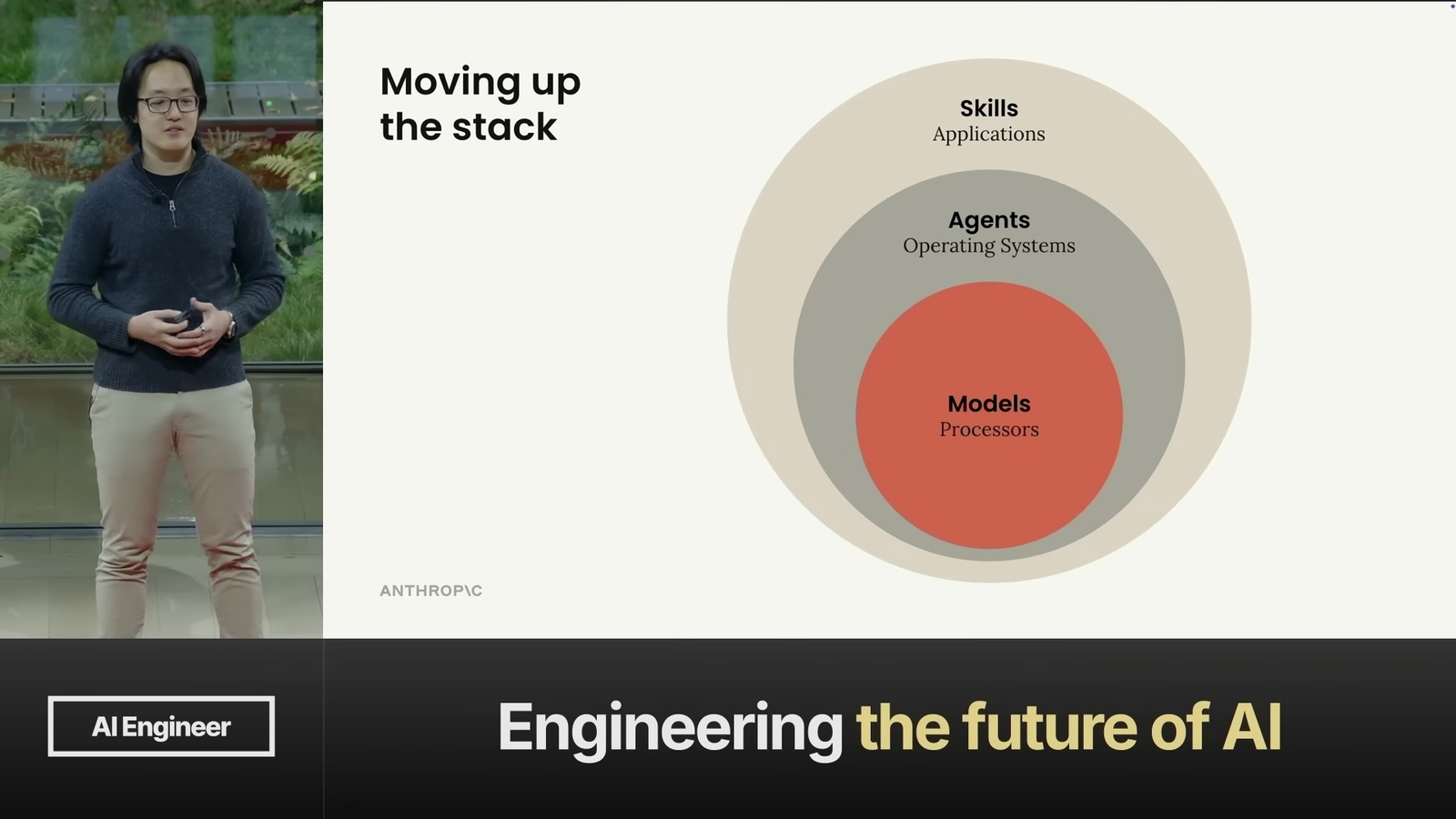

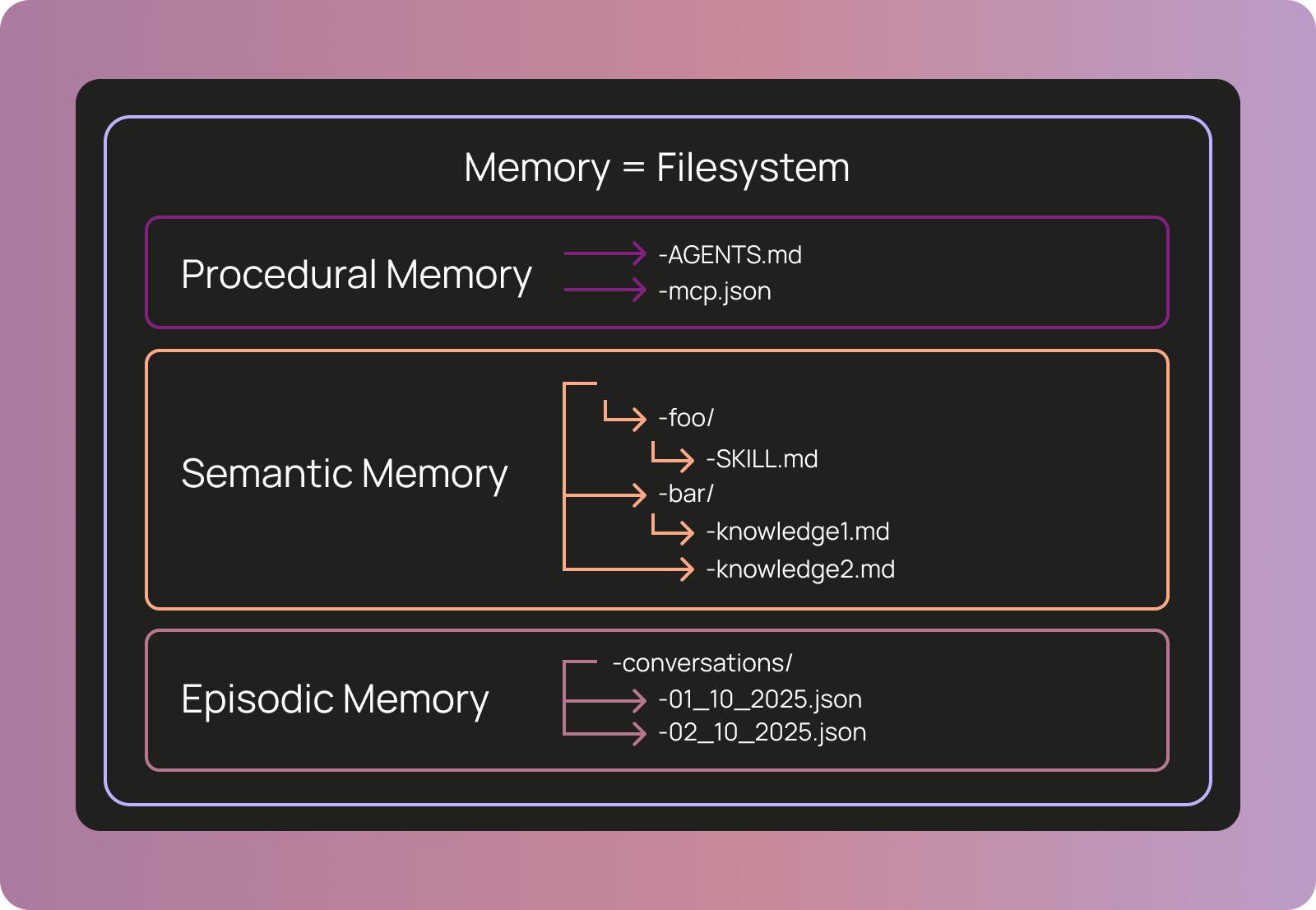 Memory = Filesystem: 三種記憶類型與檔案系統的對應關係(圖片來源: LangChain)
Memory = Filesystem: 三種記憶類型與檔案系統的對應關係(圖片來源: LangChain)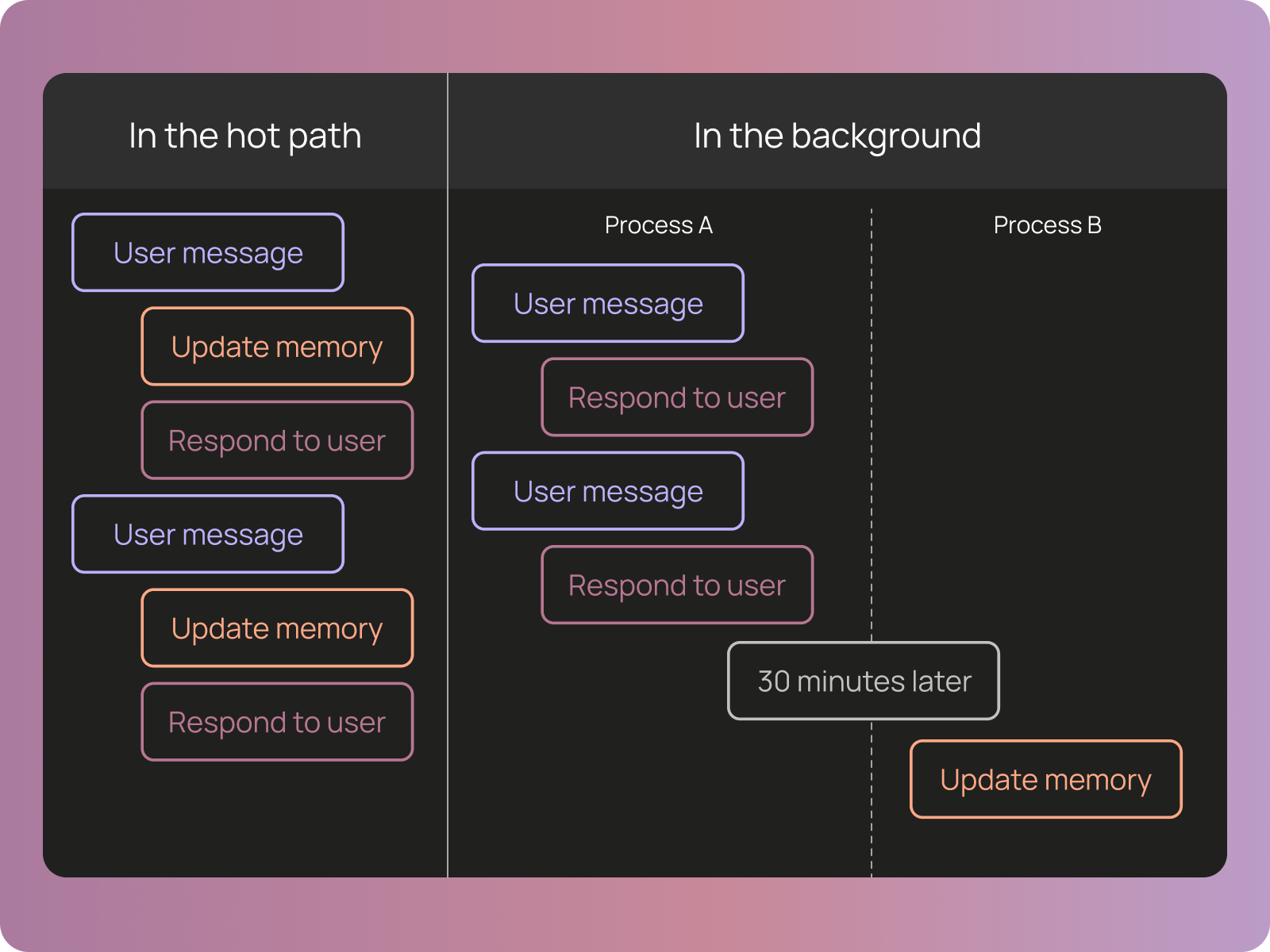 記憶更新的兩種模式: In the Hot Path(左)vs In the Background(右)(圖片來源: LangChain)
記憶更新的兩種模式: In the Hot Path(左)vs In the Background(右)(圖片來源: LangChain)