LangChain Agent Builder 的記憶系統是怎麼做的
LangChain 這週推出了 LangSmith Agent Builder,一個 no-code 的 agent 建構工具。同時發了這篇 How we built Agent Builder’s memory,講他們怎麼設計 agent 的記憶系統。
我覺得這篇蠻值得看的,因為它不是在講理論,而是實際踩過坑之後的經驗分享。以下結合原文做比較完整的整理。
為什麼記憶對這類 Agent 特別重要
一般的 ChatGPT 或 Claude 是通用型助手,你可能上午問食譜下午問程式,session 之間的關聯性低,記憶不記憶影響沒那麼大。Simon Willison 也寫過,即便 ChatGPT 加了記憶功能,目前也還沒真正 transform 產品體驗。
但 Agent Builder 做的是「特定任務的 agent」— 一個幫你整理 email 的助手、一個寫會議紀錄的助手、一個 LinkedIn 招募助手。這種 agent 反覆做同樣的事,上一次 session 學到的東西,下一次幾乎一定用得到。如果每次都要重新教它偏好,體驗會很差。
所以他們一開始就把記憶當核心功能來做,不是事後加的。這個優先級判斷我覺得很正確 — 對 task-specific agent 來說,記憶不是 nice-to-have,是基本需求。
記憶的理論框架: COALA 論文
在設計記憶系統之前,他們先參考了 COALA 論文 的分類框架,把 agent 記憶分成三種:
- Procedural memory(程序記憶): 驅動 agent 行為的規則集,決定 agent「怎麼做事」
- Semantic memory(語意記憶): 關於世界的事實知識
- Episodic memory(情節記憶): agent 過去行為的序列,「之前做過什麼」
這個框架幫他們決定了要先做什麼、後做什麼。目前 Agent Builder 實作了 procedural 和 semantic memory,episodic memory 列在未來計畫中。
核心設計: Memory = Filesystem
這是整篇最有趣的設計選擇。他們的核心理念是 Memory = Filesystem — 把 agent 的所有記憶直接對應到檔案系統的結構。
下面這張圖清楚呈現了 COALA 三種記憶類型如何映射到具體的檔案:
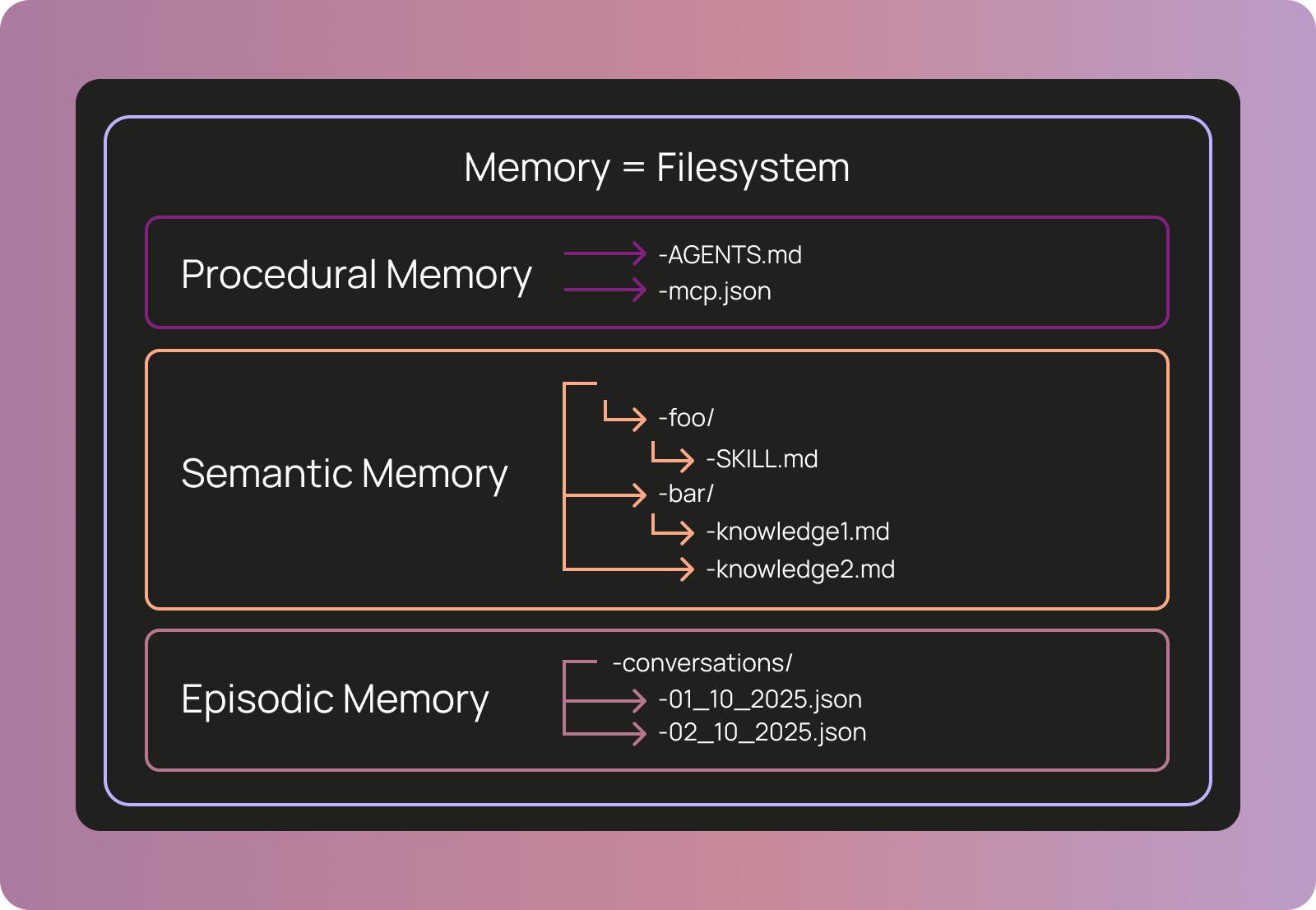 Memory = Filesystem: 三種記憶類型與檔案系統的對應關係(圖片來源: LangChain)
Memory = Filesystem: 三種記憶類型與檔案系統的對應關係(圖片來源: LangChain)
- Procedural memory(程序記憶) 對應 AGENTS.md 和 mcp.json — 定義 agent「怎麼做事」和「有哪些工具」
- Semantic memory(語意記憶) 對應 skills/ 目錄下的 SKILL.md 和各種知識檔案 — agent「知道什麼」
- Episodic memory(情節記憶) 對應 conversations/ 目錄下按日期排列的對話紀錄 — agent「經歷過什麼」(這部分目前還沒實作,列在未來計畫中)
具體來說,agent 的檔案結構包含:
- AGENTS.md: 定義 agent 的核心指令
- tools.json: MCP server 設定(用自訂格式而不是標準 mcp.json,因為需要讓用戶只暴露部分工具給 agent,避免 context overflow)
- skills/: 特定任務的專門指令
- subagents/: 子 agent 定義,格式參考了 Claude Code
- 其他檔案: agent 工作中自己寫的筆記和知識
為什麼用檔案? 因為 LLM 本來就很擅長操作檔案系統,不需要給它特殊的記憶管理工具,直接讓它讀寫檔案就好。而且盡量用業界標準格式 — AGENTS.md、MCP、agent skills — 這樣 agent 的設定可以移植到其他 harness。
有趣的是,實際上這些「檔案」存在 Postgres 裡,只是以檔案系統的形態暴露給 agent。這個 virtual filesystem 是 DeepAgents 原生支援的,底層可以換成 S3、MySQL 等任何 storage。對 LLM 來說它在操作檔案,對基礎設施來說它在操作資料庫 — 兩邊都拿到最適合的抽象層。
一個真實案例: LinkedIn 招募 agent
原文展示了他們內部實際在用的一個 LinkedIn 招募 agent,檔案結構長這樣:
- AGENTS.md: 定義核心招募指令
- subagents/linkedin_search_worker: 主 agent 校準搜尋條件後,會啟動這個子 agent 去搜集約 50 個候選人
- tools.json: 設定一個有 LinkedIn 搜尋工具的 MCP server
- 3 個 JD 檔案: 在使用過程中,agent 自己建立和維護的職缺描述
記憶是怎麼演化的: 會議紀錄 agent 的例子
文章舉了一個會議紀錄 agent 的例子來說明記憶如何隨時間「長出來」:
起點 — AGENTS.md 只有一行: Summarize meeting notes.
第一週 — agent 寫段落式摘要,你糾正說「用 bullet points」。agent 自動更新 AGENTS.md,加上格式偏好。
第二週 — 它自動用 bullet points(不用提醒),你再補充「把 action items 獨立列出來」。記憶繼續累積。
第四週 — 兩個偏好都自動套用,你繼續在新的邊界案例出現時給回饋。
第三個月 — AGENTS.md 已經演化成一份詳細的規格書,包含:
- 不同文件類型的格式偏好
- 領域術語定義
- action items、decisions、discussion points 的區分規則
- 常見參與者的角色(例如 Sarah Chen 是 Engineering Lead,關注技術細節; Mike Rodriguez 是 PM,關注業務影響)
- 不同會議類型的處理方式(engineering vs. planning vs. customer vs. 短會議)
- 各種邊界案例的修正
關鍵在於: 這個 AGENTS.md 是「長出來」的,不是一開始就寫好的。透過持續使用和糾正,agent 的指令集自然演化。這其實就是一種很自然的 prompt engineering 方式 — 讓使用者用自然語言回饋,agent 自己把回饋結構化成指令。
不需要 no-code builder 的 DSL,也不需要用戶懂 prompt engineering,就是正常使用然後說哪裡不對,agent 自己學。
踩過的坑
這段是我覺得最有價值的部分,都是實戰經驗:
🔹 最難的是 prompting: 幾乎所有記憶行為的問題都是靠改 prompt 解決的 — agent 該記的沒記、不該記的亂記、寫到錯的檔案(例如把 skill 的東西寫到 AGENTS.md)、格式不對等等。他們有一個人全職在做記憶相關的 prompting,佔了團隊很大比例。這點蠻驚人的,也印證了 context engineering / prompt engineering 在實際產品開發中的重要性。
🔹 檔案格式驗證很重要: agent 有時候會生成不合格式的 tools.json 或 skills 檔案(缺少必要的 frontmatter、MCP server 設定不合法等)。解法是加一層 schema validation,失敗就把錯誤訊息丟回給 LLM 重寫,而不是直接 commit 壞掉的檔案。
🔹 Agent 會加東西但不會壓縮: 這個很經典。例如 email 助手開始一個一個列出要忽略的供應商名字(Vendor A、Vendor B、Vendor C…),而不是歸納成「忽略所有 cold outreach」。Agent 很擅長累積具體案例,但不擅長從具體案例中抽象出通則。這跟人類其實蠻像的 — 看到具體的容易記,抽象歸納需要刻意的反思。
🔹 有時還是需要人工提示 agent 整理記憶: 即使 agent 能在工作中自動更新記憶,他們發現在某些情況下,作為使用者手動提示 agent 管理記憶還是很有效。例如在對話結束後叫 agent「反思這次對話並更新記憶」,或者叫它「壓縮過於冗長的記憶」。這兩個操作都能明顯改善記憶品質。
🔹 Human-in-the-loop 記憶更新: 所有記憶修改都需要人類批准才會生效,主要是為了防 prompt injection — 如果惡意內容能直接改 agent 的記憶,後果不堪設想。不過他們也提供了「yolo mode」讓信任度高的場景可以關掉這個保護。
這個設計帶來的好處
No-code 但不需要學 DSL: 很多 no-code builder 的問題是你需要學一套不熟悉的 DSL,而且複雜度一上去就 scale 不了。但 Agent Builder 的 agent 設定就是 markdown + json 檔案,technically-lite 的人也看得懂、改得動。
更好的 agent 建構體驗: Agent building 本質上是非常 iterative 的 — 你不試跑就不知道 agent 會做什麼。記憶讓迭代變得更容易,因為你不用每次手動改設定,用自然語言給回饋就好。
可攜性: 檔案格式可以移植到其他 agent harness。他們盡量用標準格式就是為了這個 — 你在 Agent Builder 做的 agent,可以帶到 Deep Agents CLI、Claude Code、OpenCode 等其他環境跑。
不需要 vendor lock-in,因為 agent 的「大腦」就是一堆 markdown 和 json 檔案。
未來方向
文章最後列了幾個他們想做但還沒時間或信心做好的方向:
1️⃣ Episodic memory: 把歷史對話變成檔案系統中的檔案,讓 agent 可以翻閱自己過去的對話。這是 COALA 框架中目前唯一缺的那塊。
2️⃣ 背景記憶整理: 目前所有記憶更新都是 “in the hot path”(agent 執行任務的當下)。原文用這張圖對比了兩種記憶更新策略:
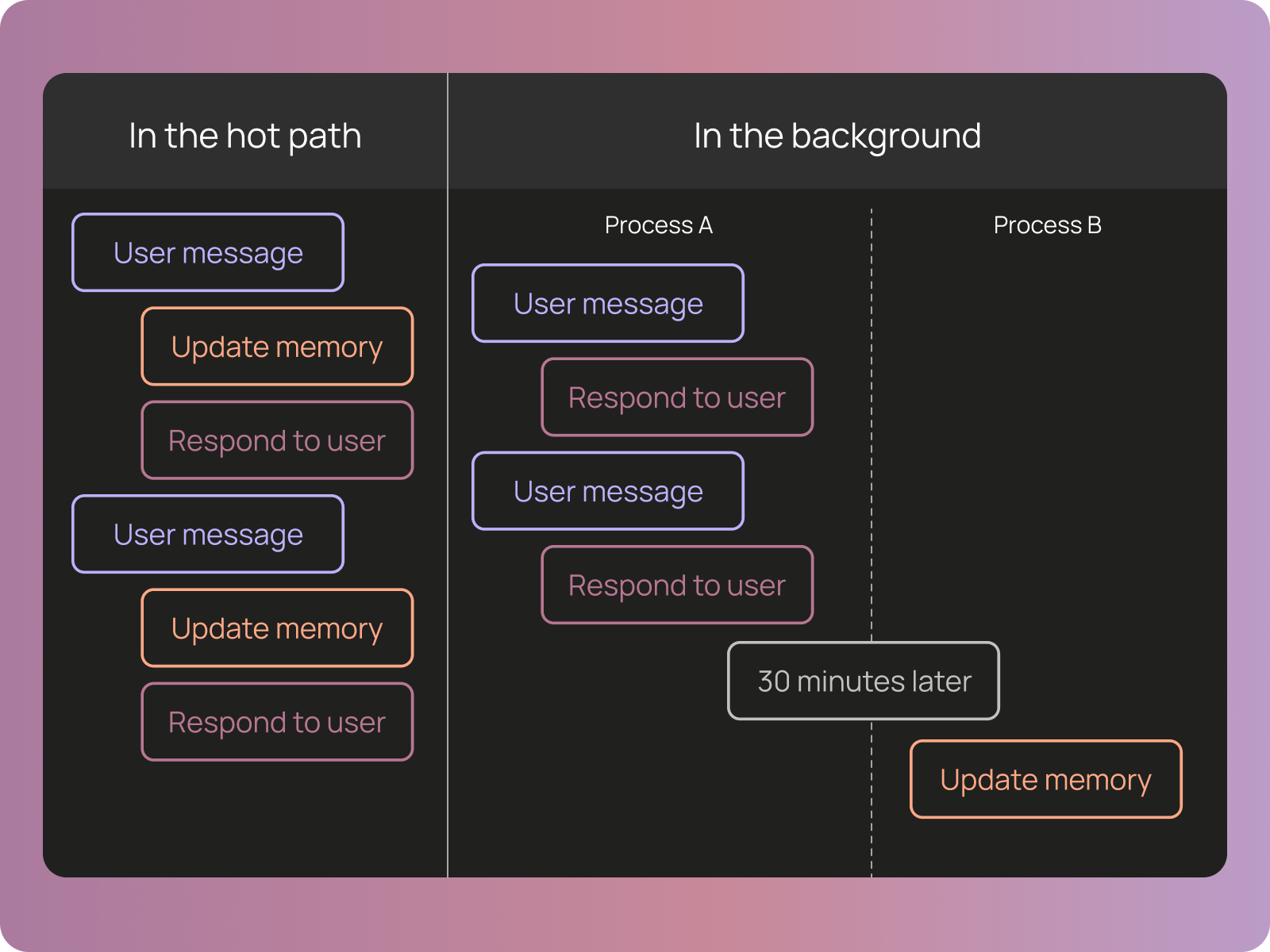 記憶更新的兩種模式: In the Hot Path(左)vs In the Background(右)(圖片來源: LangChain)
記憶更新的兩種模式: In the Hot Path(左)vs In the Background(右)(圖片來源: LangChain)
左邊是目前的做法 — 每次收到用戶訊息,agent 先更新記憶,再回覆用戶。記憶更新是同步的、blocking 的,坐在回應的 critical path 上。好處是記憶永遠是最新的,但代價是每次互動都多了記憶操作的延遲。
右邊是他們想做的 — 收到訊息就直接回覆,記憶更新放到背景程序去做(例如每 30 分鐘或每天跑一次)。使用者體驗更流暢,而且背景程序可以做更深層的反思 — 跨多次對話歸納通則,而不只是就當下對話做記錄。這特別有助於解決前面提到的「agent 不會壓縮記憶」的問題。
3️⃣ /remember 指令: 讓用戶可以主動觸發記憶整理。他們自己用的時候發現偶爾手動叫 agent 反思很有效,所以想把這個變成正式功能。
4️⃣ Semantic search: 目前 agent 用 glob 和 grep 搜尋記憶,之後要加語意搜尋來處理更複雜的查詢場景。
5️⃣ 多層記憶: 目前記憶只有 agent 級別。未來要加 user 級別和 org 級別的記憶,透過暴露不同的目錄給 agent 來實現。例如某些知識是所有 agent 共享的(org 級),某些是特定用戶的偏好(user 級)。
我的觀察
這篇對正在做 AI Agent 產品的人蠻有參考價值的。幾個特別值得注意的點:
「用檔案系統表示記憶」這個設計選擇,簡單但有效。LLM 天生就會操作檔案,何必再造一套記憶管理 API? 而且用標準格式(AGENTS.md、MCP)讓 agent 天然具備可攜性。
「記憶是長出來的,不是設計出來的」這個理念也很好。與其要求用戶一開始就寫好完美的 prompt,不如讓 agent 在使用中自己演化。這降低了 agent 建構的門檻,也更符合人類學習的方式。
最後那些踩坑經驗 — agent 不會壓縮記憶、格式驗證、prompting 是最花時間的工作 — 都是很實際的工程教訓,做 agent 產品的人遲早會碰到。