資料科學家的逆襲: 談 AI 工程為何更需要資料科學

作者 Hamel Husain 是 20 多年經驗的資深 ML 工程師,過去在 GitHub 主導過 CodeSearchNet (Copilot 前身)、也在 Airbnb 做過 ML,現在是 Parlance Labs 獨立顧問,專注在 LLM 應用的 evals。他跟 Shreya Shankar 合開的 AI Evals for Engineers and PMs 課程,ihower 也是學員之一。
他最近這篇 The Revenge of the Data Scientist (資料科學家的逆襲) 非常讚,把「LLM 時代資料科學家是不是要失業了」這個老問題重新拆解了一遍,小編覺得每個正在做 LLM 應用的人都該讀一次。
文章開場就直接打臉一個常見誤解: 大家以為資料科學家的工作就是「訓練模型」,所以基礎模型 API 這麼好用之後就沒戲唱了。Hamel 反過來說: 訓練模型從來就不是資料科學的主軸,這群人真正在做的是「設計實驗、測試 AI 在沒看過的資料上能不能泛化、debug 隨機系統、設計好的指標」這些事——而這些工作在 LLM 時代不但沒消失,反而更重要了。
🔧 要做好 Harness 就是在做 Data Science
Harness 指的是 AI agent 的「執行環境」。文章引用 OpenAI 在 Codex harness 上的工程實踐: 把日誌、指標、追蹤資料 (traces) 全部暴露給 agent,讓 agent 自己判斷有沒有走偏。Karpathy 最近的 auto-research 也是同樣概念——靠驗證指標自動判斷每個改動有沒有變好。
Hamel 把要做好 harness 拆成 6 個面向,括號裡寫的都是傳統 Data Science 訓練裡的核心技能:
- 錯誤分析: 讀模型輸出、找 pattern → 對應「資料探索 (EDA)」
- 指標設計: 把評估對齊到真正重要的目標
- 驗證: 證明 evaluator 跟人類判斷一致 → 對應「模型評估」
- 測試資料: 產生多樣的輸入 → 對應「實驗設計」
- 監控: 偵測資料漂移 → 對應「線上 ML」
- 迭代: 衡量、改進、實驗 → 對應「科學方法」
「名字變了,工作沒變」——小編覺得這個切角蠻準的。
⚠️ 五個團隊最常踩的坑
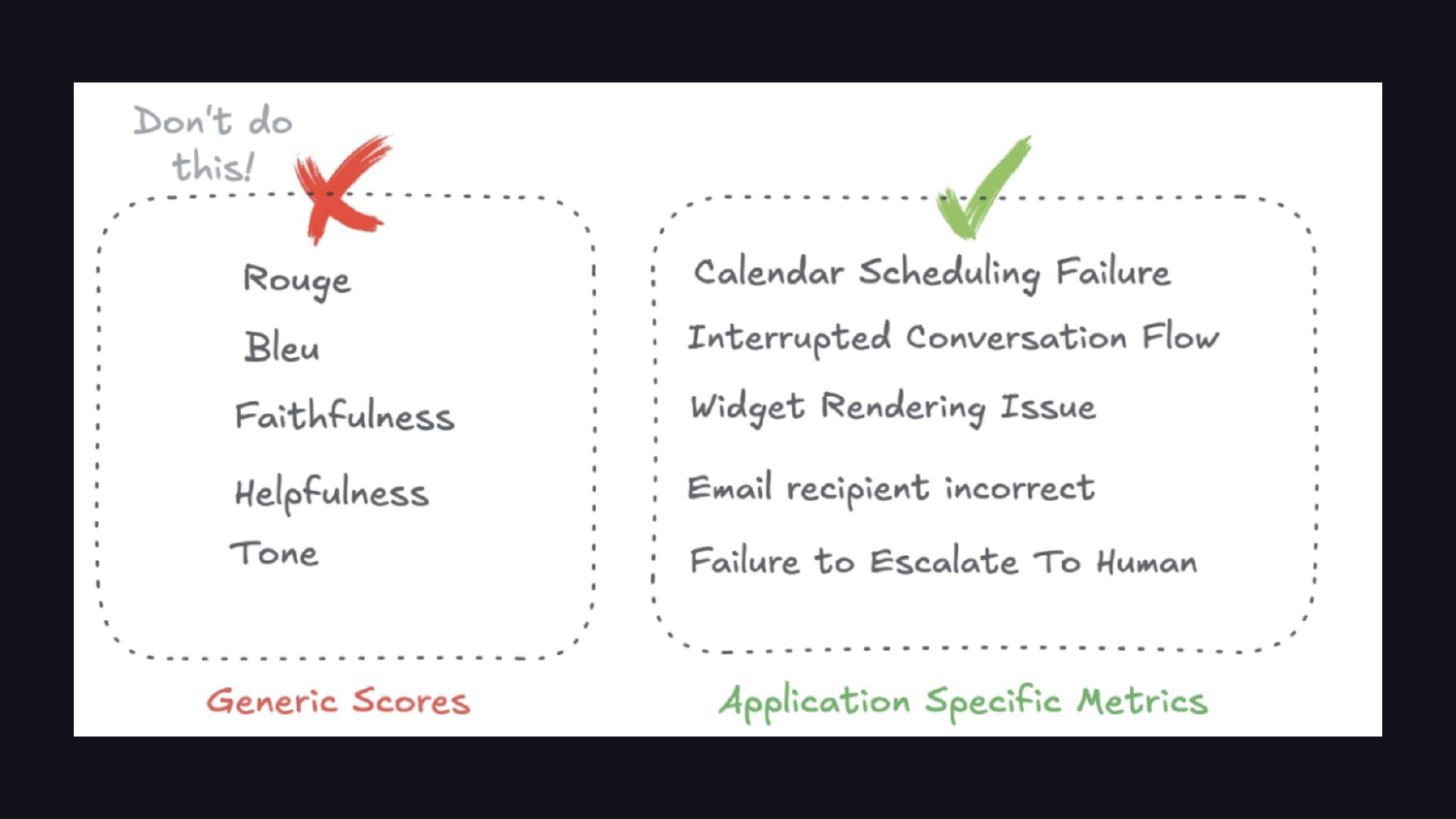
1. 通用指標不能用
很多團隊抓一個評估框架就套,根本沒搞清楚自己的應用會怎麼壞。Hamel 的建議是: 自己寫一個 trace 檢視器,把追蹤資料拉出來一筆一筆看,做錯誤分析,找出真正屬於你應用的失敗模式。
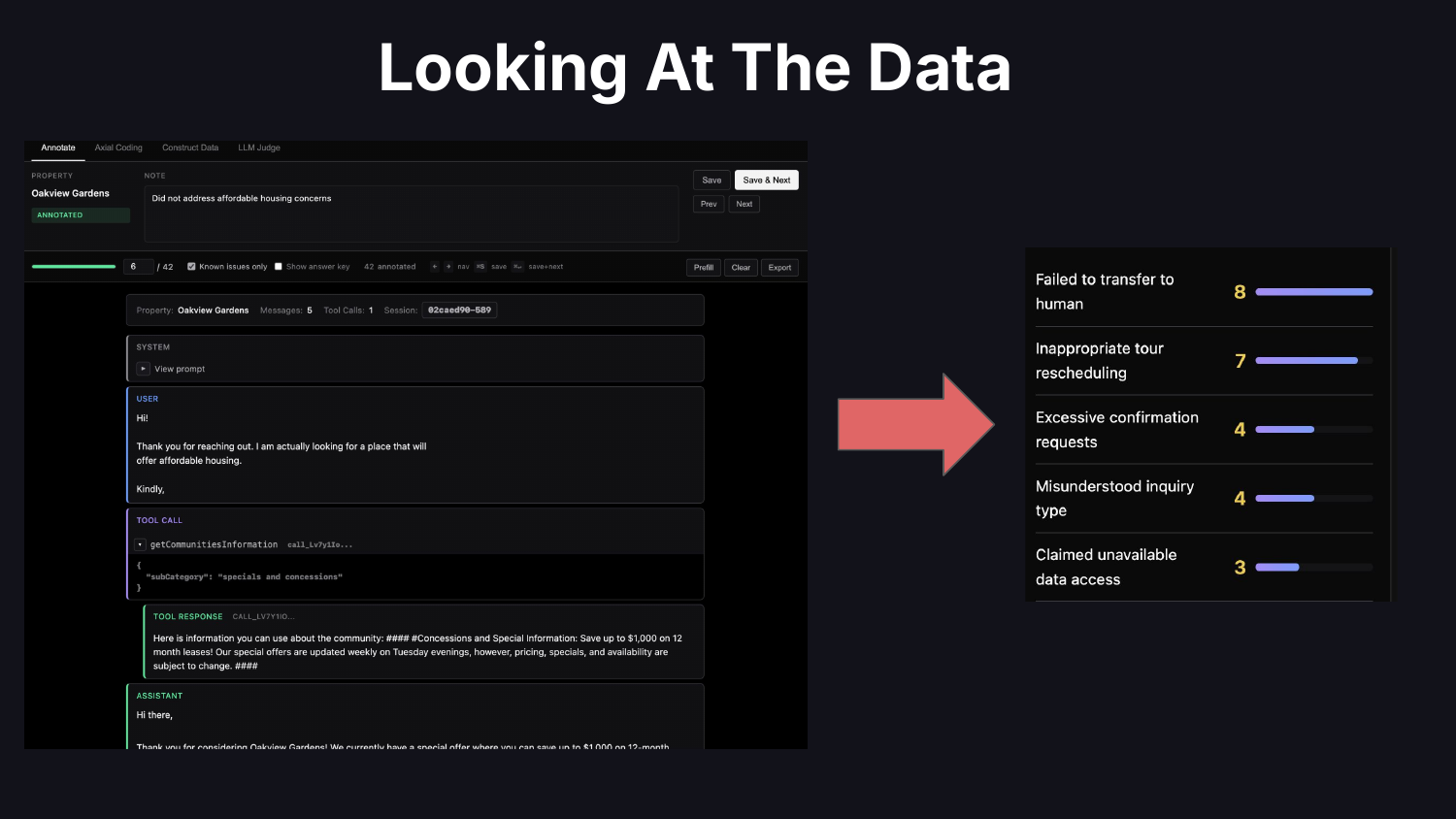
不要再用 ROUGE、BLEU、Faithfulness、Helpfulness、Tone 這種泛泛的指標,要的是像「Calendar Scheduling Failure」「Failure to Escalate To Human」這種具體、可以動作的描述。
2. 沒驗證過的 LLM Judge
絕大多數團隊在用 LLM-as-judge,但從來沒驗證過 judge 本身準不準。Hamel 的方法是把 judge 當成一個分類器來看: 拿人工標註當標準答案,切出訓練/開發/測試三個資料集,量 precision (精準率) 跟 recall (召回率)。
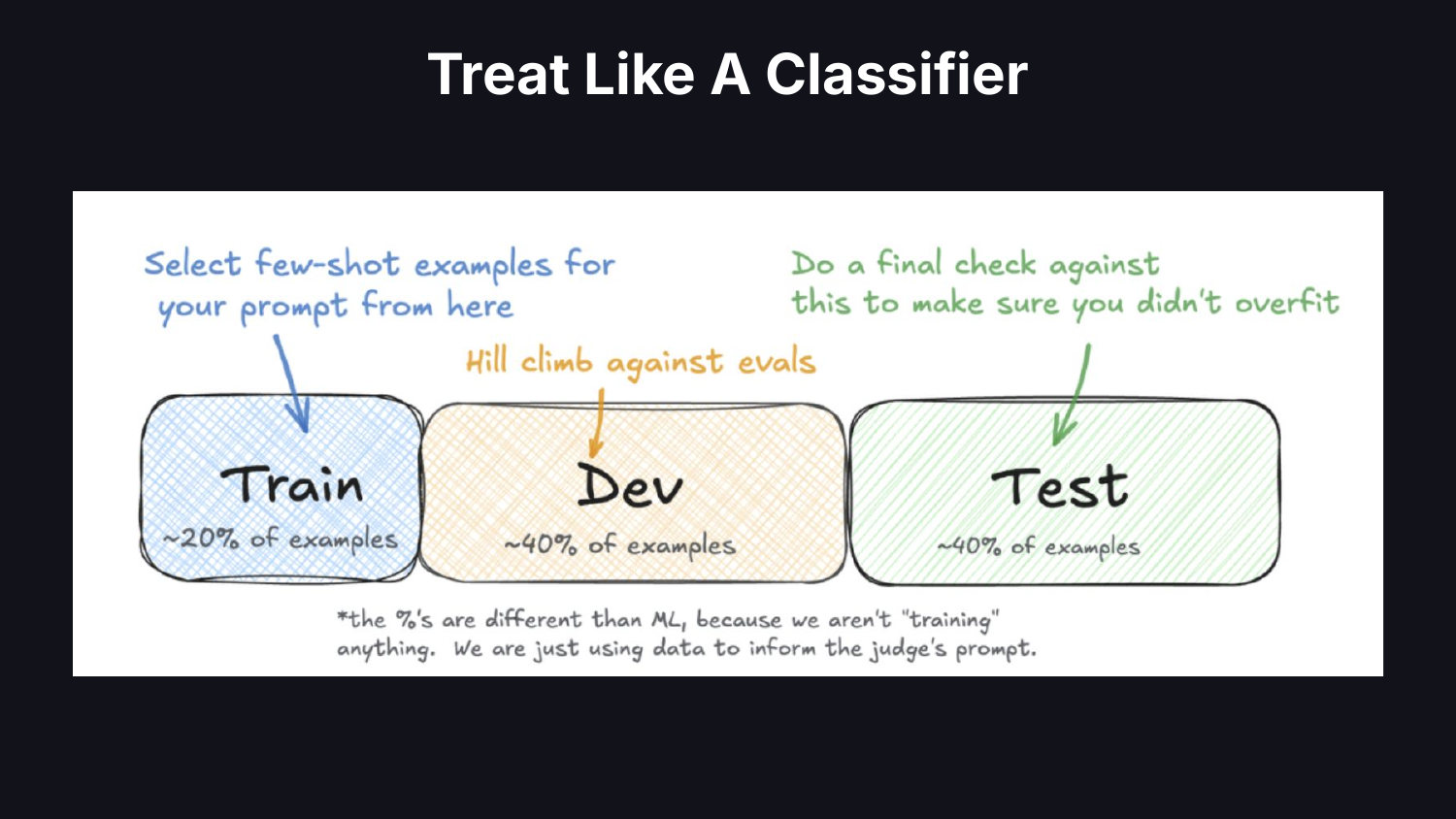
特別重要的一點: 不要報準確率。當失敗情境屬於少數時,「judge 準確率 95%」可能只是因為 judge 永遠回 pass 而已,根本沒抓到問題。要看 precision 跟 recall 才看得到真實情況。
3. 糟糕的實驗設計
兩個面向: 測試集跟指標。
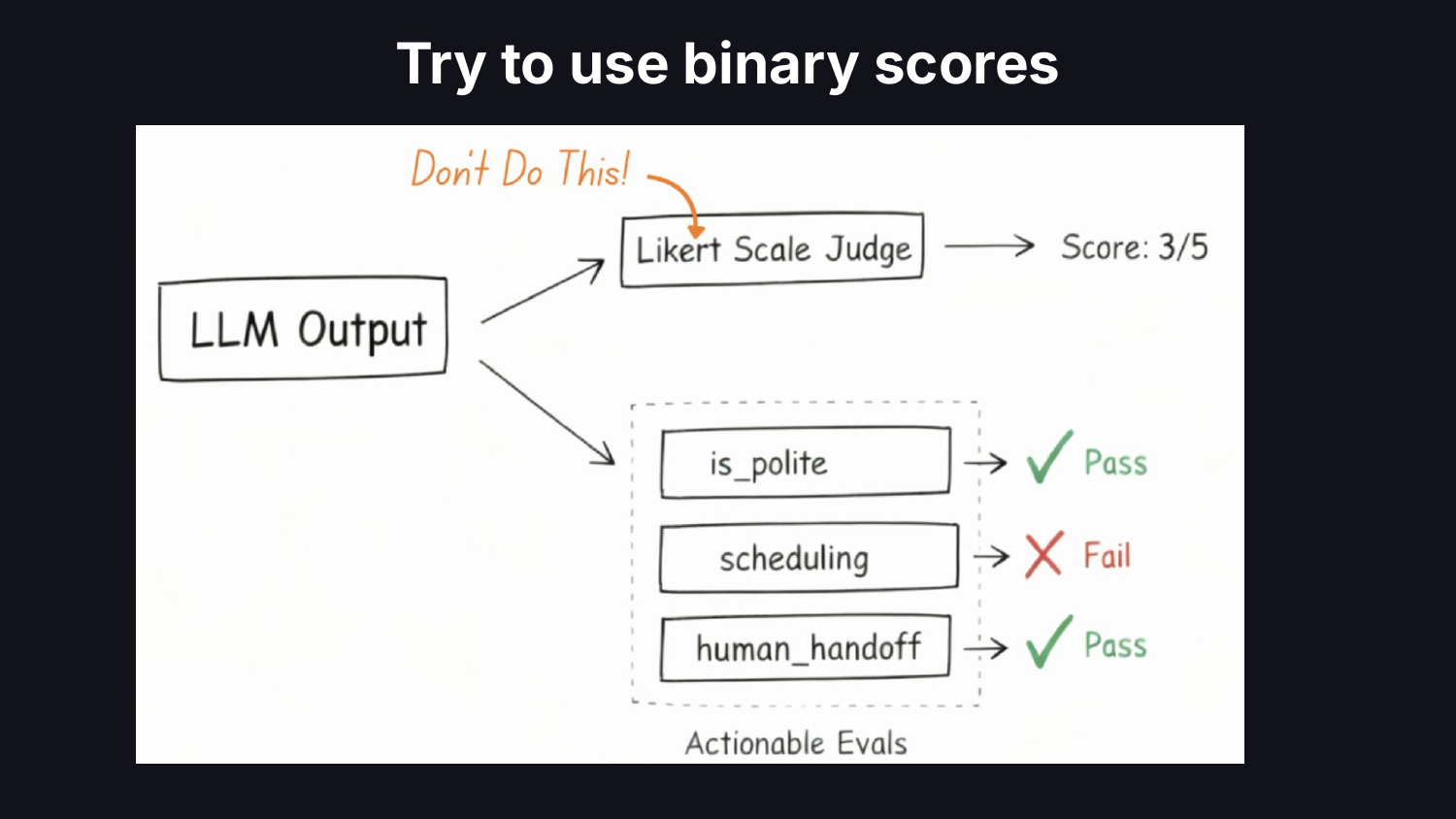
測試集不要用憑空生出來的合成資料,要紮根在真實的線上 log 上,再去注入邊界案例。指標不要用 1-5 分的 Likert 量表 (太主觀,問題會被分數平均掉),改成二元的 pass/fail,每一條對應到具體的業務結果。
4. 爛的資料跟標註
Hamel 講了一句蠻嗆的話:
資料科學家不相信資料、不相信標註、不相信任何東西。他們的訓練讓他們天生多疑。
這段他引用了 Shreya Shankar 等人關於「criteria drift (評估標準漂移)」的研究: 使用者其實是在標註的過程中,才會逐漸發現自己真正的評估標準是什麼。所以標註這件事不能外包出去,必須讓領域專家親自看原始資料。產品團隊要拿到的是原始資料,不是彙總分數。
編按: criteria drift 出自 Shankar et al. 2024 的論文。重點是評估標準不是事先就能完整定義的,而是看到 LLM 實際輸出之後才會浮現出來——這跟傳統 ML 假設「評估標準可以事先定義好」是矛盾的。
5. 過度自動化
LLM 可以幫你寫樣板程式碼、處理管線雜事,但不能幫你看資料:
你在看到輸出之前,根本不知道自己要什麼。
這條跟前面的評估標準漂移是一致的——「看資料」這件事無法被外包或自動化,因為人是在看的過程中才會校準自己的判斷標準。
🪤 還有這些坑,他來不及細講
文章最後 Hamel 用一張投影片快速帶過另外 9 個常見坑,沒有展開講,但每一條都值得對著清單檢查一下:
- 誤用相似度分數 (例如用 cosine similarity 來判斷答案對不對)
- 問 judge 太空泛的問題,像「這個答案有幫助嗎?」
- 讓標註人員直接讀原始 JSON
- 報分數沒附信賴區間
- 忽略資料漂移跟評估標準漂移
- Judge 過擬合到開發集
- 採樣方式不對
- 儀表板訊號量很低,看了等於沒看
- 把 trace 紀錄當成評估 (「我們有在記 log,所以我們有 evals 了」——這個誤解小編覺得最普遍)
每一條拆開都可以是另一篇文章。Hamel 之所以放在最後快速帶過,大概也是因為前面 5 個坑都掌握了,這些才會看得進去。
🎯 名字變了,工作沒變
Hamel 把每個地雷都對應回經典的資料科學領域:
- 通用指標 → 資料探索 (EDA)
- 沒驗證的 judge → 模型評估
- 糟糕的實驗設計 → 實驗設計
- 爛的標註 → 資料蒐集
- 沒監控 → 線上 ML
整篇文章最大的洞見: 大家以為 LLM 把 ML 民主化、讓資料科學變得不必要,但實務上反而是把資料科學思維推到了第一線。沒有資料科學思維的團隊,做出來的 AI 應用就是靠感覺在跑——測試靠感覺、指標靠感覺、judge 對不對也靠感覺,最後產品壞掉了還不知道為什麼。
🐍 為什麼推薦用 Python
這場演講是在 Python 大會上講的,所以 Hamel 用一句話打結:
這是一場 Python 大會,所以: Python 仍然是看資料、處理資料最好的工具組。
這句話不只是場合需要,背後還是 harness 那條主軸——你的評估工具鏈跑在哪些工具上,決定了你能多快把資料拉出來看。Python 之所以還沒被取代,原因跟 10 年前一樣: pandas、Notebook、繪圖工具加起來,仍然是讓人坐下來把追蹤資料一筆一筆看完最順手的環境。
Hamel 同時釋出了一個 evals-skills 開源工具,這是一個 Coding Agent 的技能,對著你的評估流程跑,它會幫你檢查哪些坑踩到了 (precision/recall 沒報、judge 沒驗證、指標太通用等等)。Hamel 自己的描述是: 「告訴你哪裡做錯了,至少它會盡力告訴你。」

安裝方式 (在 Claude Code 裡輸入):
/plugin marketplace add hamelsmu/evals-skills
/plugin install evals-skills@hamelsmu-evals-skills
小編覺得這個工具的方向蠻聰明的: 把這 5 個坑的檢查寫成 skill,丟給 coding agent 自動掃自己的程式碼庫。等於是把 Hamel 在課程裡會手動幫你檢查的事情,做成可重用的外掛。
🌐 社群也在呼應這個觀點
小編順手用 Exa 查了一下,發現「資料科學家在 LLM 時代不但沒死、反而更重要」這個論點在這一年多裡被許多人反覆論述,Hamel 這篇算是更系統化的整理。挑幾個有意思的:
🎙️ Hamel 自己 2025 年 9 月就在 Vanishing Gradients podcast 講過 “revenge of the data scientists”,當時談的是評估。所以這篇文章可以說是他講了大半年、終於落成文字的版本。那一集標題是「我討厭 AI 評估的 10 件事」(10 Things I Hate About AI Evals),主軸也是同一條: 多數團隊用錯了做法,要的是以資料為核心的路線。
📝 Eric J. Ma 2025 年 8 月的 Data Scientists Aren’t Becoming Obsolete in the LLM Era (資料科學家在 LLM 時代沒有變得多餘) 跟 Hamel 的調性幾乎一致。他寫:
在「看 Claude/ChatGPT 寫 Python、建模、debug」的焦慮背後,真正在發生的事情是: LLM 沒有取代資料科學家,而是在重新定義資料科學家是什麼。衡量跟評估的能力比過去更值錢了。
這跟 Hamel 講的 harness 就是資料科學工作完全是同一件事,只是切角不同。
🎯 Tianpan 2026 年 2 月的 Why Your LLM Evaluators Are Miscalibrated (你的 LLM 評估為什麼校準失準) 則直接呼應 Hamel 講的評估標準漂移:
多數團隊建 LLM evaluator 的順序是反的: 他們先寫評估標準,再去看資料。這個順序顛倒,就是 evaluator 校準失準幾乎普遍存在的根本原因。
「先寫評分標準、再看資料」聽起來很「嚴謹」,實際上是把 LLM 評估變成一種自我感覺良好的儀式——這跟 Shankar 那篇評估標準漂移論文的結論完全一致。
📊 Medium 上 Nisarg Bhatt 2026 年 3 月的 Is the Data Scientist Role Dying? (資料科學家這個職位在凋零嗎?) 觀點是: 這個職位沒死,被淘汰的是「掛資料科學家頭銜但只做機械式工作」的那類人。對「能嚴謹思考資料問題」的人來說,企業的需求只增不減。
把這幾篇放在一起看,Hamel 這篇的價值不只是新觀點,而是把「為什麼 LLM 時代更需要資料科學思維」拆成 5 個具體可檢驗的失敗 pattern——對正在 debug 自己 LLM 應用的工程師來說,這比泛泛說「資料科學還是很重要」實用太多。
✍️ 小結
Hamel 在文章結尾不斷強調的那句「Always look at the data (永遠去看資料)」,看起來簡單,但真正做的人少之又少。
整篇文章其實一直在講同一件事: LLM 沒有讓「做評估」變簡單,反而把過去資料科學家累積的那套訓練重新搬到了第一線。框架、judge、自動化都救不了你——能救你的,只有真的把追蹤資料拉出來、一筆一筆看完,然後在這個過程裡校準出屬於你應用的失敗模式跟評估標準。
「資料科學家的逆襲」並不是說這個職位要回來搶飯碗,而是這套思維方式正在被每個做 LLM 應用的工程師重新學一次。