做 LLM 評估應該要知道的統計觀念
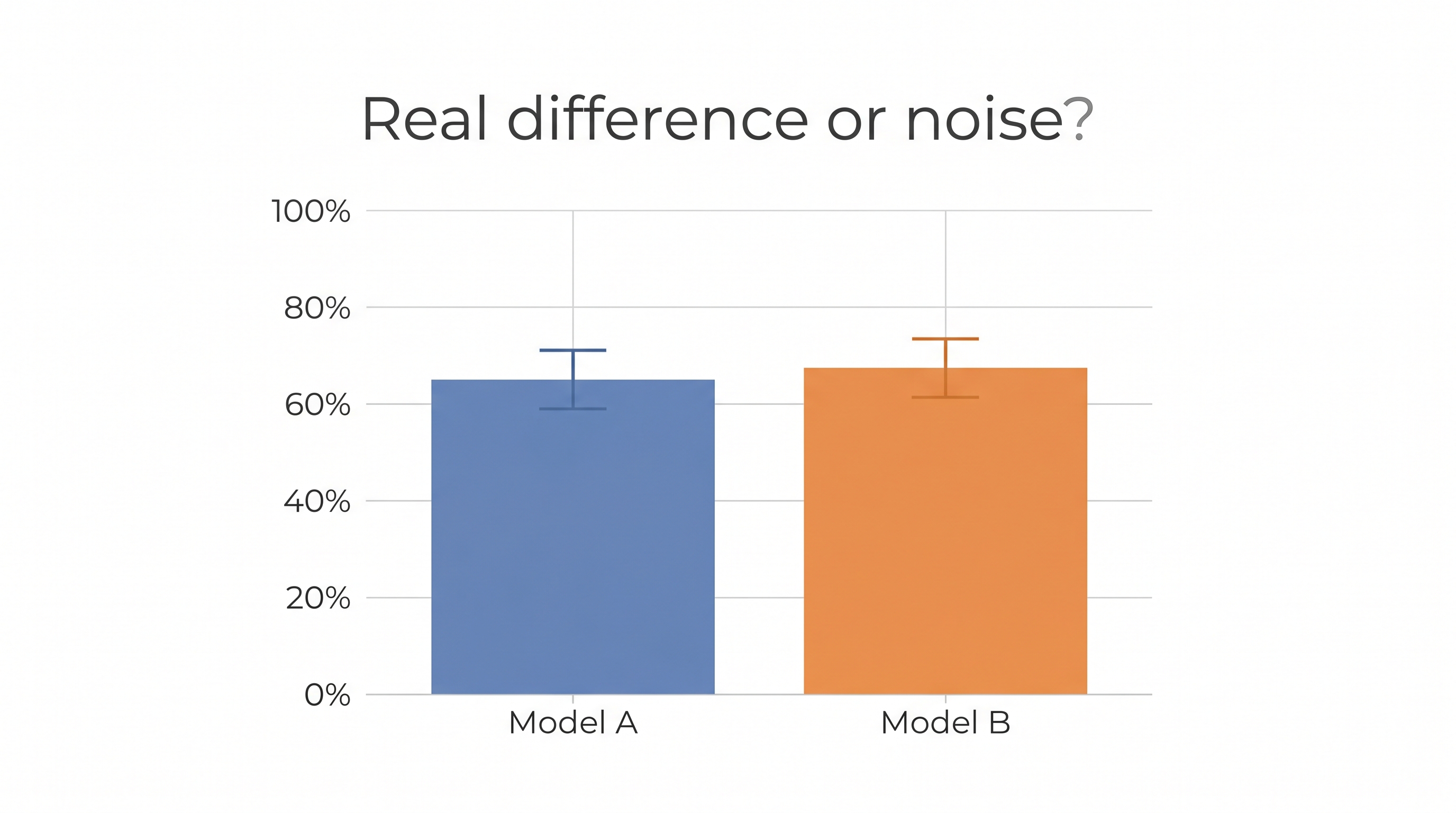
模型 A 在 MMLU 上拿 67.5%、模型 B 拿 65.2%,A 比較強嗎?
直覺會說「A 贏了 2.3 個百分點」。但 Anthropic 研究員 Evan Miller 在 2024 年發了一篇蠻重要的 paper Adding Error Bars to Evals: A Statistical Approach to Language Model Evaluations,配上一篇好讀的 部落格版本,告訴大家: 這個差異很可能根本是雜訊,你看到的「贏」只是運氣。
Cameron R. Wolfe 後來寫了一篇很棒的導讀 A Statistical Approach to LLM Evaluations,把 paper 裡的統計觀念整理得更完整好懂,也補充了 power analysis、小樣本陷阱等實務面向。
這篇綜合這兩份資料,整理一份「做 LLM 評估時你應該知道的統計觀念」,不教數學公式,聚焦在實務上跑 eval、比較 prompt 和 Agent 時能直接用的判斷原則。
為什麼小數差就是雜訊
先講一個讓人冒冷汗的事實: 主流 benchmark 換個 prompt 就能讓分數跳動好幾個百分點。但業界拿來比較模型強弱的差距通常只有 1 個百分點左右。
量測本身的雜訊,比模型的真實差異還大。也就是說,你看到「模型 A 比 B 強 1%」這件事,很可能完全是雜訊。
但研究界、產品界天天在做這種「排行榜思維」的判斷:
- 看到新模型 benchmark 高 0.5% 就說 SOTA
- 改一版 prompt 跑 100 題好了 3% 就上線
- A/B 兩個檢索方法跑 50 題差 5% 就決定改架構
這些都是沒做統計檢定就下結論。Evan Miller 的核心訴求很簡單: eval 就是科學實驗,請用做實驗的態度來分析。
換個視角: eval 不是排行榜,是抽樣
paper 裡有個關鍵的視角轉換:
我們在 eval 上看到的分數,不是模型的真實能力,而是從一個「題目宇宙」中抽出 n 題後得到的「樣本平均」。
這個視角一旦建立,世界就不一樣了。MMLU 那 1.4 萬題不是「全部能考的題目」,只是某個假想題目分布裡的一個樣本。換另外 1.4 萬題,模型分數一定會不一樣。
問題是: 不一樣多少?
這個「不一樣多少」就是「誤差線」。報告分數時要連同誤差線一起報,不然就是在誤導人。
下面整理 paper 的幾個核心觀念。
建議 1: 永遠回報誤差線
最基本的觀念。一個分數沒有誤差線,就像「今天溫度 25 度」沒告訴你是「±1 度」還是「±10 度」一樣,沒辦法判斷意義。
直觀理解: 題目越多,誤差線越小。具體感受一下 (假設模型答對率 70% 左右):
| 題目數 | 95% 信賴區間 | 真實能力可能落在 |
|---|---|---|
| 100 題 | ±9% | 61% ~ 79% |
| 500 題 | ±4% | 66% ~ 74% |
| 1000 題 | ±3% | 67% ~ 73% |
| 10000 題 | ±0.9% | 69.1% ~ 70.9% |
看到了嗎?一個模型 100 題拿 70%,另一個 100 題拿 73%,根本分不出高下,兩個信賴區間完全重疊。
而且誤差不是線性遞減: 題目從 100 加到 200,誤差只從 ±9% 縮到 ±6.4%。想把誤差砍一半,題目要翻 4 倍。
第一條紀律: 看到 eval 分數沒附誤差線,就不要拿小數點差距下強結論。
編按: 統計上這個叫「中央極限定理」。不用懂公式,記口訣就好: 誤差要減 3 倍,題目要加 10 倍。
建議 2: 題目不獨立時,誤差比你以為的大
這個是最容易踩雷的點。
很多 eval 的題目其實不是獨立的:
- DROP、SQuAD 這類閱讀測驗: 同一段文章會出 5-10 題
- MGSM: 同一道數學題翻成 11 種語言
- HumanEval: 一個 problem 配多個 test case,但通過與否要算 problem-level
為什麼有差?因為「會不會某段文章」會決定那 5-10 題全對全錯。真正獨立的資訊量遠少於題目總數。假裝它們獨立,會嚴重低估誤差線 — 修正後的誤差可以是天真版本的 3 倍以上。
實務上的修正叫 clustered standard errors,主流統計套件都有現成函式。
第二條紀律: 題目有「群組結構」(同主題、同來源、同模板) 時,預設你看到的誤差線太小,差異很可能根本不顯著。
建議 3: 同一題多跑幾次
模型對同一題的回答其實有兩層隨機:
- 題目本身的隨機: 題目是抽樣來的,這個改不了
- 生成的隨機: 同一題模型每次答案可能不同,這個可以改
第二層隨機的解法很直覺: 同一題跑幾次取平均。雜訊會明顯下降,但邊際效益遞減,通常 5-6 次就夠了。如果是選擇題,更乾淨的做法是直接看模型給「正確答案 token」的機率,根本不用採樣。
具體例子: 你在跑一個 Agent eval,100 題。Agent 有隨機性,同一題可能這次成功率 60%、下次 80%。只跑一次,誤差會包含很多「這次 Agent 心情不好」的雜訊。改成每題跑 5 次取平均,雜訊就被抹平掉一大半。
⚠️ 一個常見迷思: 「我把 temperature 調成 0 應該就沒有方差了吧?」
paper 對這個直覺很保留。重點不是 temperature=0 一定變糟,而是為了降 variance 不該動 temperature — 這會改變你正在量測的模型行為,搞不好還引入偏誤。要降雜訊,重採樣就好。
第三條紀律: Agent / RAG 這類有隨機性的任務,每題重採樣幾次取平均,比執著於 temperature 調 0 有效得多。
建議 4: 比較兩個模型: 用配對分析 + 想清楚要多少題
這是小編覺得 paper 裡最有立即實用性的建議。
比較模型 A 和 B 的正確做法是:
讓 A、B 跑同一批題目,看每一題上「A 跟 B 的分差」,再對這些分差求平均、算誤差線。
不要分別算 A、B 各自的分數然後相減。後者會浪費掉很多資訊。這個做法在統計上叫配對分析 (paired difference analysis)。
直覺解釋: 兩個模型通常都覺得簡單題簡單、難題困難。那些「兩個都對」或「兩個都錯」的題目對判斷誰強沒幫助,真正有資訊量的是「一個對一個錯」的題目。配對分析直接抓住這個差異 — paper 實測,同樣題目數,誤差線大約可以縮到原本的 6-8 成 (依兩個模型的相關性而定)。
那要多少題才夠?這取決於你想偵測多大的差異。統計上有個方法叫 power analysis,但不用管名詞,記住一個關鍵: 題目數和可偵測的差異之間是平方關係。舉例來說,200 題大約能偵測 7% 的差異,如果你想偵測更細的 3.5% 差異,不是加倍到 400 題就好,而是要翻到 4 倍、也就是 800 題。
下面這張表可以直接查 (二元評分、配對分析、答對率約 70%):
| 題目數 | 大約能可靠偵測到的最小差異 |
|---|---|
| 50 題 | ~14% |
| 100 題 | ~10% |
| 200 題 | ~7% |
| 500 題 | ~4.5% |
| 1000 題 | ~3% |
所以 50 題的 Agent eval 跑出 A 版 75%、B 版 70%,那 5% 的差距其實偵測不到 — 測試集對這個級別的差異沒有區分力,跑了也是白跑。
實務上的建議: 跑之前先決定你在乎多大的差異。如果兩版 prompt 差不到 5% 對業務沒影響,那 100 題就夠了。如果 3% 的改善就有意義 (例如生產環境的客服準確率),就需要拉到 500-1000 題。先算帳再跑,不要跑完才發現白做工。
第四條紀律: 比較兩個方案,請跑同一批題目並逐題比對。跑之前先想清楚你在乎多大的差異,題目數不夠就別拿小差異做決策。
建議 5: 小樣本 eval 的信賴區間可能是假的
前面講的信賴區間都依賴中央極限定理 (CLT),而 CLT 有個前提: n 要夠大。
研究發現,當 n < 100 時,CLT 算出來的信賴區間會系統性偏窄 — 你以為是 95% 信賴區間,實際覆蓋率可能只有 85-90%。翻譯成白話: 你比實際上更有信心,而那個信心是虛的。
什麼情況下特別嚴重?
- 準確率接近 0% 或 100%: 例如某個 Agent 在 30 題的 eval 上拿 93%,CLT 會給出很窄的信賴區間,但其實非常不可靠
- 刻意設計的極難 eval: 準確率只有 5-10% 的 benchmark,CLT 同樣撐不住
- Agent eval 天然就題少: 設計一個高品質的端到端 Agent 測試案例很費工,手上常常只有 30-80 個案例,每跑一次還可能花幾分鐘甚至幾十分鐘
遇到小樣本怎麼辦?
- 心裡調寬信賴區間: 如果算出 ±5%,自己當 ±8% 來看
- 不要拿小樣本的小差異下結論: 50 題的 eval 差 5%?先假設是雜訊
- 考慮 Bayesian 方法: 如果對統計工具有一定掌握度,Bayesian 信賴區間在小樣本時比傳統方法穩健得多,特別適合 Agent eval 這種「題目少但每題成本高」的場景
這對做 Agent 評估的人尤其重要。承認「我的樣本不夠大,結論要保守看」比假裝信賴區間很可靠來得誠實。
第五條紀律: eval 題目少於 100 時,對信賴區間和顯著性結論都要打個折扣。
paper 的實例: 表面 2 勝 1 敗,其實是 1 勝 2 平
paper 用兩個虛構模型「Galleon」和「Dreadnought」在三個 benchmark 上對比:
- MATH (5000 題): Galleon 65.5% vs Dreadnought 63.0%,Galleon 顯著領先
- HumanEval (164 題): Galleon 83.6% vs Dreadnought 86.7%,不顯著 (n 太小)
- MGSM (2500 題, 250 個語言群組): Galleon 75.3% vs Dreadnought 78.0%,不顯著 (cluster 修正後)
表面讀法: Dreadnought 在三場裡贏了兩場,整體比較強。
做過統計後: 只有 Galleon 在 MATH 的勝利有統計顯著性,其他兩場差異都在誤差範圍內。真實結論變成 Galleon 一勝二平,方向跟表面剛好相反。
不做統計,你會看到「Dreadnought 較強」的故事;做了統計,你會看到「只有 Galleon 在 MATH 真的贏,其他無從判斷」的故事。結論差很多。
補充: 還有更多雜訊來源
Evan Miller 的 paper 主要處理「題目抽樣」這層雜訊,但 LLM eval 還有更多麻煩來源。2025 年的 Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation 把雜訊拆得更細:
- Prediction noise: 同題不同回答
- Data noise: 從題目分布抽樣的隨機性
- Seed variance: 訓練 seed 不同造成的差異
- Prompt sensitivity: prompt 換一下分數就跳
這篇還有個有意思的發現: 某些 eval 上只用 16 個高訊噪比的子任務反而比跑全部 MMLU 更能區分模型。題目越多不一定越好,訊噪比才是關鍵。
編按: NeurIPS 2024 的 Quantifying Variance in Evaluation Benchmarks 也測了主流 benchmark 的 variance,發現有些 benchmark 連 seed 差異都足以蓋過模型間的差異。
小編的實務 checklist
整理一份開發 LLM 應用、跑 eval 時可以直接套的清單:
1. 先想清楚「獨立觀測單位」是什麼
一道題?一篇文章?一個 coding problem?一個 user session?這是所有統計的起點。SQuAD 的單位是「文章」不是「題目」、HumanEval 是「problem」不是「test case」。搞錯這個,後面所有的誤差線、信賴區間、顯著性檢定全部失準。
2. 永遠回報誤差線,不要只貼平均值
一個 70% 的分數沒附誤差線,沒辦法判斷意義。最少附上 95% 信賴區間或標準誤,順手把 n (題目數) 一起寫清楚,讓讀者能自己判斷可信度。「66% ± 3% (n=1000)」比孤零零的「66.3%」有用一百倍。
3. 題目有群組結構就做 cluster 修正
同主題、同來源、同模板的題目不獨立,不能假裝是獨立樣本。常見地雷: 一篇文章配多題的閱讀測驗、同一道題翻成多語言、同一個 prompt 模板生成的多道題。實務上用 clustered standard errors,主流統計套件 (R、Python 的 statsmodels) 都有現成函式,Anthropic 推薦的 Inspect 評估框架也內建處理。
4. 比較兩個模型一定要用配對分析 (paired difference analysis)
讓兩個模型跑同一批題目,逐題比對,回報「分差」的平均和誤差線,不要分開報 A、B 兩個分數讓讀者自己腦補比較。同樣題目數,配對分析的誤差線可以縮到原本的 6-8 成 — 等於白賺出有效樣本數,這是 paper 裡 CP 值最高的建議。
5. 有隨機性的任務每題多跑幾次取平均
Agent、RAG、tool use 這類任務每次跑結果都不太一樣,只跑一次的雜訊會非常大。每題重採樣 5-6 次取平均,邊際效益就遞減了,不需要跑更多。如果是選擇題類型,可以直接讀模型給「正確答案 token」的機率,連採樣都不用。不要為了降 variance 把 temperature 調 0,那會改變你正在量測的模型行為,搞不好還引入偏誤。
6. 跑 eval 前先做 power analysis — 先算帳再跑
不要跑完才想「這個差異有沒有意義」。跑之前先決定你在乎多大的差異,再反推需要多少題。記住: 想偵測一半大的差異,題目要翻 4 倍。50 題的 Agent eval 只適合偵測 15% 以上的大差距;想看 3-5% 的差異至少要 500 題。先算帳再跑,不要跑完才發現白做工。
7. 小樣本 (n < 100) 的信賴區間要打折看
題目少於 100 時,信賴區間的計算會系統性偏樂觀 — 標示 95% 的信賴區間實際上可能只有 85-90% 的覆蓋率。Agent eval 因為每題成本高,常常只有幾十題,這時候不要太相信算出來的信賴區間和顯著性結論,心裡要多打一些折扣。
8. 小於 1-2% 的差異預設當雜訊看待
除非 n 非常大 (像 MMLU 1.4 萬題級) 而且做了配對分析,否則 1% 以內的差距很難說是真的。看到 leaderboard 上「+0.3% 新 SOTA」的宣稱,第一個反應應該是「誤差線多大?」而不是「哇好強」。實務決策上,1% 差距通常不該成為換模型的理由 — 換模型的成本 (測試、迴歸、prompt 微調) 大概率比這 1% 大。
9. 用 leaderboard 排名做判斷時,看「重疊區間」而不是「名次」
很多排行榜模型的差距小於各自的誤差線,意思是換另外一批題目,名次很可能洗牌。看排行榜時養成「畫一條誤差線」的習慣,把信賴區間重疊的模型當成「打成平手」,不要被小數點後的排名騙了。
結尾
引用 paper 結語的一句話:
「統計學是『在有雜訊的情況下做測量』的科學。」
LLM eval 就是有雜訊的測量。當整個產業還在用「最高分就是贏」的思維時,誰先把 eval 當實驗來做、誰先學會看誤差線,誰就有更大的機率做出真正的進步、避開假性的退步。
這不是學術潔癖,是工程紀律。下次看到 leaderboard 上「+0.3% 新 SOTA」的宣稱,第一個問題應該是: 誤差線多大?