Agent Experience (AX): 當 AI Agent 成為用戶,產品該怎麼設計? 以設計 CLI 為例
UX 做了三十年,DX 做了十五年,現在又來一個新的: AX — Agent Experience。
這不是又一個行銷縮寫。過去這幾個月,小編看到越來越多具體的東西冒出來: Salesforce 宣布 Headless 360 把整個平台暴露成 API、MCP 和命令列工具;Notion 的 MCP 伺服器會主動餵格式規格給 agent;Ramp 的 MCP 週活用戶三個月內成長了十倍。Agent 已經是你產品的真實用戶了,問題只是你有沒有在為它設計。
這個詞最早是 Netlify 執行長 Mathias Biilmann 在 2025 年 1 月提出的,定義是:
AX 是「AI agent 作為產品或平台的使用者時,所經歷的整體體驗」
他的觀察很直接: 對 agent 來說難用的工具,會需要更多人工介入,越用越笨重;對 agent 友善的工具,會變得越來越強大、越來越受歡迎。DX 當年怎麼成為開發者工具的競爭護城河,AX 現在就在走同一條路。
Jeff Bailey 在 Fundamentals of Agent Accessibility 裡用了一個小編覺得很精準的類比: Agent 碰到你的 API 時面臨的挑戰,和螢幕閱讀器碰到網頁時一模一樣 — 兩者都需要結構、語義和可預測性才能運作。 過去我們花了二十年推動網頁無障礙設計,現在同樣的思維要延伸到 agent 身上。
這篇小編把最近讀到的幾篇重要文章整理成一個完整框架,從概念、旅程地圖、到實作設計原則,並以 CLI 設計為主要範例來說明。
AX、DX 和 UX: 三個不同的設計對象
Leonie Monigatti 在她的 Agent Journey Map 文章中把三者的差異拆得很清楚:
| UX | DX | AX | |
|---|---|---|---|
| 目標受眾 | 終端用戶 | 開發者 | AI Agent |
| 核心問題 | 怎麼使用產品 | 怎麼用產品來開發 | Agent 怎麼操作和建構 |
| 關鍵指標 | 滿意度、推薦意願、任務完成率 | 首次呼叫 API 的時間、開發速度 | 被 agent 選中率、token 消耗量、回饋循環次數 |
最根本的差異是: UX 和 DX 要考慮情感曲線(挫折 → 困惑 → 滿意);AX 沒有情感,取而代之的是失敗模式和可靠性曲線 — agent 在每個階段有多大機率成功完成任務。
Justin Poehnelt(Google)在他的這篇文章裡用一句話切到重點:
人類導向的 DX 優化的是可發現性和容錯;Agent 導向的 DX 優化的是可預測性和縱深防禦。這兩者差異大到,把一個人類優先的 CLI 改裝給 agent 用,是注定失敗的。
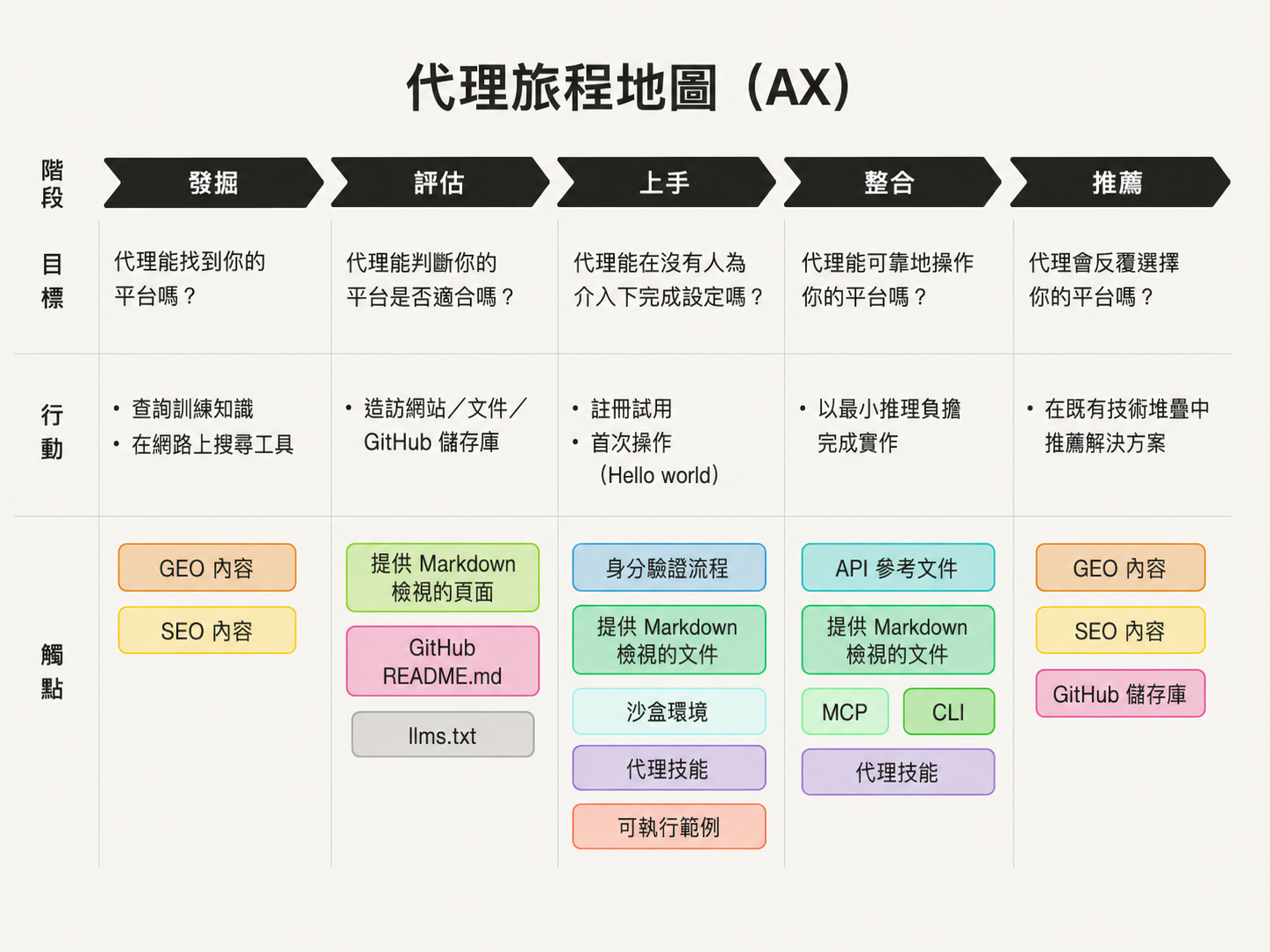
Agent 旅程地圖: 五個階段
Leonie Monigatti 提出了一個很實用的框架,借用 UX 和 DX 的「旅程地圖」概念,把 agent 與你產品的互動路徑分成五個階段:
1. 發現: Agent 能不能知道你的產品存在?
這是最值錢也最沒有明確答案的階段。Agent 怎麼「發現」一個工具? 大概有幾個管道:
- 訓練資料裡的提及量和情感: 你的產品在 LLM 訓練語料中被提到多少次、正面還是負面
- 網路搜尋: Agent 用搜尋工具研究時,你能不能被找到
- 生成式搜尋優化: SEO 的 LLM 版本(有人叫 GEO、LLMO 或 AEO),很多代理商在推,但目前沒有證實有效的方法
編按: 最近 Amplifying.ai 做了一份大規模研究 What Claude Code Actually Chooses,用 2,430 個開放式提示測試 Claude Code 到底會選什麼工具,結論是它確實會強烈偏好特定產品(例如前端 React 85%、CI/CD 用 GitHub Actions 94%)。更有趣的是,在 12 個類別中,Claude Code 最常見的「選擇」是自己從頭寫,而不是推薦任何第三方工具。但為什麼會這樣偏好? 訓練資料? 搜尋排名? GitHub 使用量? 目前還是黑箱。
2. 評估: Agent 能不能判斷你的產品是否適合?
對應到 UX 和 DX 裡「逛官網、讀文件」的階段。AX 的新考量是讓網站內容對 agent 更友好:
- llms.txt: Answer.AI 在 2024 年 9 月提出的標準化格式,讓 LLM 更容易理解你的網站。但 Drupal 創辦人 Dries Buytaert 的數據顯示:「設計給機器人用的 llms.txt,機器人反而不太看」
- 文件的 Markdown 版本: Gemini API 文件、Elastic 文件等已經提供「檢視 Markdown」選項。Dries 的數據顯示 Markdown 確實比 llms.txt 有更多機器人流量,但還是不如一般 HTML
- GitHub README: 這反而是 agent 最常碰到的入口之一
3. 上手: Agent 能不能不靠人就開始使用?
關鍵問題是「從零到 Hello World」在 AX 裡能壓到多快。幾個常見卡點:
- 認證: OAuth 流程是為人設計的,agent 做不了瀏覽器跳轉。解法是 API 金鑰、服務帳戶、環境變數注入
- Agent Skills: 給 agent 一份結構化的「快速上手指南」,比讓它自己啃文件快得多
- 沙盒環境: 讓 agent 可以安全地試錯,不用擔心搞壞正式環境
4. 整合: Agent 能不能穩定操作你的平台?
這是最核心的階段,下面會用大量篇幅展開。
5. 推薦: Agent 會不會持續選擇你的產品?
Agent 怎麼選技術棧? 怎麼決定推薦哪個工具? 這個階段本質上又繞回「發現」— 形成一個循環而不是漏斗。你的產品在 agent 生態系裡的口碑,會直接影響下一輪被選中的機率。
整合層的四條路: CLI、API、MCP、Skills
回到旅程地圖第四階段「整合」。Anthropic 在四月發了一篇 Building agents that reach production systems with MCP,把 agent 連接外部系統的方式整理得蠻清楚的 — 目前主要有四條路,各有不同的適用場景和取捨:
CLI(命令列工具) 是目前 agent 最容易上手的介面,因為 LLM 的訓練資料裡充滿了 shell 指令。Agent 看到 --help 就知道怎麼探索,用管道就能組合工作流,上下文成本幾乎為零。但 Anthropic 也指出它的侷限: CLI 最適合本地開發環境和沙盒容器,到了行動裝置、瀏覽器或雲端託管的環境就不適用了。
直接呼叫 API 是最成熟的整合方式。關鍵是要有清楚的、機器可讀的結構描述(例如 OpenAPI 規格),以及能讓 agent 自我修正的錯誤回應。但 Anthropic 點出了一個核心挑戰: 直接呼叫 API 會造成 M×N 的整合問題 — 每一對 agent 和服務之間都是獨立的客製整合,認證處理和工具描述各做各的,隨著 agent 數量增加完全沒法擴展。
MCP(模型上下文協定) 正是為了解決這個 M×N 問題而生的。MCP 建立了一個共通的協議層,agent 連上一個 MCP 伺服器,就能透過標準化的工具定義來操作你的系統 — 認證、發現、語義描述都有統一標準。一個遠端伺服器就能服務所有相容的用戶端(Claude、ChatGPT、Cursor、VS Code),跨平台、跨裝置。代價是需要更多前期投入,而且每一層抽象都有保真度的損失。
Agent Skills 則是結構化的 Markdown 指引,告訴 agent 在特定情境下該怎麼操作你的產品。Anthropic 把 Skills 定位為「程序性知識」— MCP 給 agent 工具,Skills 教 agent 怎麼用這些工具來完成真正的工作。Skills 是按需載入的,agent 不需要的時候不佔上下文,而且可以編碼那些從 --help 或工具描述看不出來的隱性知識。
這四條路不是互斥的。Anthropic 說得很直接: 成熟的整合通常會多管齊下 — API 是基礎,CLI 服務本地環境,MCP 服務雲端 agent,而 Skills 橫跨所有介面把它們串起來。
編按: 小編之前寫過一篇後 MCP 時代: Skills 取代 MCP 嗎?,深入比較了兩者的差異和分工。簡單來說: 在 coding agent 場景下(像 Claude Code、Codex CLI),Skills 配上 shell 幾乎可以取代大部分 MCP 的用途;但在需要標準化認證流程或跨廠商整合的場景,MCP 作為協議標準仍有它的定位。
接下來,小編用 CLI 設計為主要範例,來具體說明「為 agent 設計」到底意味著什麼。這些原則 — 漸進式揭露、可執行的錯誤訊息、冪等操作 — 同樣適用於 API 和 MCP 工具的設計。
以 CLI 為例: 為 Agent 設計的基本原則
大多數命令列工具是為人設計的,直接讓 agent 用會撞牆。Eric Zakariasson 在一篇廣為流傳的推文裡總結了幾個關鍵原則,Cursor 也把這些原則整理成一份 CLI for Agents skill,給 coding agent 在開發或審查 CLI 工具時參考:
非互動式優先
如果你的工具在執行途中跳出互動式選單,agent 就卡死了。它不會按方向鍵,也不會在對的時機打「y」。所有輸入都要能透過旗標傳入,互動式介面只作為旗標缺失時的 fallback:
# 這會卡住 agent
$ mycli deploy
? Which environment? (use arrow keys)
# 這才行
$ mycli deploy --env staging
漸進式揭露,不要一次傾倒
Agent 跑 mycli,看到子命令列表,選一個,跑 mycli deploy --help,拿到需要的資訊。不要一次把所有文件塞給它。
每個 --help 都要附範例。Agent 從 mycli deploy --env staging --tag v1.2.3 這種範例學得比讀描述文字快得多。
支援 stdin 和管道組合
Agent 天生擅長組合指令。CLI 應該在合理的地方支援 stdin 輸入和管道串接,讓 agent 把多個指令組合成工作流:
# 從 stdin 匯入設定
cat config.json | mycli config import --stdin
# 用管道串接: 上一步的輸出直接變下一步的輸入
mycli deploy --env staging --tag $(mycli build --output tag-only)
避免奇怪的位置參數順序,也不要在值缺失時退回互動式提示 — 直接用有意義的錯誤訊息告訴 agent 該補什麼旗標。
可預測的命令結構
如果 agent 學會了 mycli service list,它應該能猜到 mycli deploy list 和 mycli config list。統一用「資源 + 動作」的模式,讓 agent 可以舉一反三。
失敗要快,錯誤訊息要給下一步
# 不要這樣
Error: missing required flag
# 要這樣
Error: No image tag specified.
mycli deploy --env staging --tag <image-tag>
Available tags: mycli build list --output tags
Agent 不能上網搜錯誤訊息。每個錯誤都要同時回答「出了什麼問題」和「該怎麼做」。
冪等操作加上預覽模式
Agent 會不斷重試。同一個部署跑兩次應該回傳「已部署,無需動作」,而不是建立重複。破壞性操作一律加 --dry-run,讓 agent 先預覽再執行;同時提供 --yes 或 --force 旗標讓 agent 跳過確認提示,人類預設還是安全的互動式確認:
$ mycli deploy --env production --tag v1.2.3 --dry-run
Would deploy v1.2.3 to production
- Stop 3 running instances
- Pull image registry.io/app:v1.2.3
- Start 3 new instances
No changes made.
成功輸出要回傳機器可用的資料
錯誤訊息設計大家都注意到了,但成功輸出也很重要。Agent 需要的是可以直接使用的結構化資料 — ID、URL、耗時 — 而不是裝飾性的文字:
$ mycli deploy --env staging --tag v1.2.3
deployed v1.2.3 to staging
url: https://staging.myapp.com
deploy_id: dep_abc123
duration: 34s
Agent 拿到 deploy_id 可以直接用在下一步操作,拿到 url 可以馬上做驗證。純文字就好,不需要花俏的表格或顏色,關鍵是資訊完整且容易解析。
進階: Agent 優先的 CLI 設計
上面是基本功。Justin Poehnelt 在 Google Workspace CLI(gws)的實作經驗,把設計推到了更深的層次:
原始 JSON 優於一堆參數
人類討厭在終端打 JSON,但 agent 偏好它。十個扁平的參數沒辦法表達巢狀結構,一個 --json 接完整的 API 酬載就可以:
gws sheets spreadsheets create --json '{
"properties": {"title": "Q1 Budget", "locale": "en_US"},
"sheets": [{"properties": {"title": "January", "sheetType": "GRID",
"gridProperties": {"frozenRowCount": 1, "columnCount": 10}}}]
}'
JSON 直接映射到 API 結構,LLM 生成時零損失。務實的做法是: 同一個工具裡同時支援兩種路徑,人類用便利參數,agent 用原始酬載,兩者共存。
結構自省取代靜態文件
Agent 沒辦法上網查文件。把文件塞進系統提示詞又貴又容易過期。更好的做法是讓工具自己就是文件,可以在執行期間即時查詢:
gws schema drive.files.list
gws schema sheets.spreadsheets.create
每個 schema 呼叫吐出完整的方法簽名 — 參數、請求內容、回應型別、需要的授權範圍 — 全部是機器可讀的格式。Agent 需要的時候自己查,不用預先載入。
管好上下文視窗
API 回傳的資料可以很龐大。人類不在乎,人類會捲動。Agent 每個 token 都要付錢,而且無關的欄位會消耗推理能力。
兩個機制: 用欄位遮罩限制回傳範圍,讓 agent 只拿需要的;用串流分頁讓 agent 可以逐批處理,不用把整包資料塞進上下文。
輸入驗證: 對抗幻覺
這是最被低估的一環。人類會打錯字,agent 會幻覺,失敗模式完全不同:
- 人類幾乎不會打出
../../.ssh— 但 agent 可能幻覺出路徑穿越 - Agent 可能在資源 ID 裡嵌入查詢參數:
fileId?fields=name - Agent 經常預先做 URL 編碼,導致重複編碼
Anthropic 在 SWE-bench 的研究中也發現了一個相關的教訓: 當他們的 agent 使用相對路徑時,換了目錄就會出錯;改成強制使用絕對路徑後,這整類錯誤直接消失了。這就是「讓錯誤在結構上不可能發生」的設計理念 — 與其靠 agent 自律,不如在介面層就擋掉。
Justin 的總結:「Agent 不是可信任的操作者。你不會寫一個盲目信任用戶輸入的網頁後端 — 也不要寫一個盲目信任 agent 輸入的命令列工具。」
提供 Agent Skills
人類透過 --help、文件網站、Stack Overflow 來學一個工具。Agent 透過對話開始時注入的上下文來學。Justin 的 gws 隨附了超過一百個 SKILL.md 檔案,每個 API 操作面向一份,編碼那些 --help 看不出來的隱性知識: 「對寫入操作一律先用 --dry-run」、「每次列表呼叫都要加欄位遮罩」。
這些規則之所以必要,是因為 agent 沒有直覺 — 它需要明確寫下的不變量。一份好的 Skills 檔案比一次幻覺便宜多了。
同樣原則也適用: API 設計
命令列之外,API 是 agent 存取外部系統的主要管道。上面提到的原則 — 可預測的結構、可執行的錯誤訊息、冪等操作 — 在 API 設計上同樣適用,甚至更重要。
LemonData 在重新設計他們的 API 時,歸納出一個核心原則: 不要試圖幫 agent 自動修正,要給它足夠資訊讓它自己決定。
傳統做法可能會在 agent 打錯模型名稱時偷偷導向相似的模型。他們的做法剛好相反 — 立刻失敗,但把所有需要的資訊一次給齊:
{
"error": "model_not_found",
"detail": "Model 'gpt-5-turbo' not found",
"did_you_mean": ["gpt-5", "gpt-5-mini"],
"suggestions": [
{"model": "gpt-5", "reason": "most_used_by_account"}
]
}
他們報告這個做法讓用戶浪費的 token 降低了超過六成。
幾個跨越不同文章反覆出現的 API 設計原則:
- 錯誤訊息要可以被執行: 不只說「日期範圍無效」,要說「start_date 必須早於 end_date;收到的是 start: 2026-06-01, end: 2026-05-01」— agent 收到這個就能直接修正
- 用列舉值取代自由文字: 如果一個欄位只有有限的合法值,在結構定義裡列出來。
["pending", "processing", "shipped"]比「填入標準訂單狀態」清楚一百倍 - 一致的回應結構: 所有成功回應用同一個格式,所有錯誤回應也用同一個格式。Agent 會根據你的 API 建立內部模型,格式不一致會直接打破它的預測
- 冪等操作加上重試金鑰: Agent 可能因為網路逾時而重送請求,提供冪等機制讓同一個請求重送不會產生重複
- 速率限制要透明: 不要只在被限速時才告知,每個回應都帶上剩餘額度和重設時間,讓 agent 主動調節節奏
編按: 小編很認同一個觀點 — 對 agent 友善的 API,對人類開發者也更好用。差別只在人類可以「繞過」不完整的規格,agent 不行。它會照字面執行,規格不完整就直接失敗。所以為 agent 設計,其實是逼你把 API 做到真正該有的水準。
MCP 的抽象代價
Justin Poehnelt 在另一篇 The MCP Abstraction Tax 裡提出了一個有趣的觀點: 每多一層抽象,就要繳一次稅。
Agent 意圖 → MCP 工具 → REST API → 資料
↑ ↑
抽象稅 抽象稅
面對大型企業 API(那種幾百個端點的 CRM),MCP 伺服器設計面臨兩難:
- 精簡路線: 幾個高階操作,容易上手但表達力有損 — 沒辦法覆蓋複雜的批次操作
- 完整映射: 保真度高但上下文視窗會爆 — agent 理論上什麼都能做,實際上推理不動
Justin 歸納了一個保真度光譜:
| 方式 | 保真度 | 易用性 | 代價 |
|---|---|---|---|
| MCP(精簡工具) | 較低 | 高 | 只能表達工具作者預想到的操作 |
| MCP(完整映射) | 理論上高 | 低 | 上下文成本讓它不實用 |
| CLI + Skills | 高 | 中 | 需要 CLI 本身就為此設計 |
| 直接寫程式呼叫 API | 最高 | 最低 | 沒有護欄 |
前面提到的 Anthropic 那篇文章也給出了幾個實戰建議:
- 根據意圖分組,不是根據端點: 一個
create_issue_from_thread比get_thread+parse_messages+create_issue+link_attachment四步好用得多 - 大型 API 用程式碼編排: Cloudflare 的 MCP 伺服器只有兩個工具(搜尋和執行),用不到一千個 token 就涵蓋了約 2,500 個端點
- 工具搜尋延遲載入: 不要在啟動時把所有工具定義塞進上下文。測試顯示按需載入可以減少 85% 以上的工具定義 token,同時維持高準確率
- Skills 搭配 MCP: MCP 給 agent 工具,Skills 教 agent 怎麼用這些工具完成真正的工作。兩者是互補關係
編按: 小編之前寫過一篇後 MCP 時代: Skills 取代 MCP 嗎?深入比較了兩者的差異。簡單來說: 在 coding agent 的場景下(像 Claude Code、Codex CLI),Skills 配上 shell 幾乎可以取代大部分 MCP 的用途;但在需要標準化認證流程或跨廠商整合的場景,MCP 作為協議標準仍有它的定位。兩者不是零和 — 現有的 MCP 可以被包進 Skills 裡執行。
新的互動模式: Agent 對 Agent
Ramp 的 Teddy Riker 在 Designing for Agents 裡描述了一個正在發生的根本性轉變:
過去二十年: 使用者 → 介面 → 資料庫
現在: 使用者 → 使用者的 Agent → 資料庫
接下來: 使用者 → 使用者的 Agent → 軟體的 Agent → 資料庫
介面不再坐在使用者和系統之間了。它坐在使用者的 agent 和你的 agent 之間。
教 agent 怎麼成功
Teddy 舉了 Notion MCP 的正面案例: Notion 的建立頁面工具描述開頭就寫著「先去載入完整的 Markdown 格式規格,不要猜」。結果每次寫入都格式完美。
反面案例是 Slack MCP: agent 假設標準 Markdown 語法可以通用,結果格式全跑掉,使用者花在修格式的時間比自己寫還多。
結論: Agent 沒有直覺 — 你必須把不變量講清楚,而且要在它需要的時候主動給,不要等它自己去摸索。
建立回饋循環
Ramp 一開始做 MCP 時最大的問題是看不到全貌 — 他們看得到工具呼叫量,但看不到背後的對話脈絡。後來他們想了幾個辦法:
- 每個工具呼叫都要附上「理由」參數: Agent 必須解釋為什麼發起這個請求。他們看不到聊天記錄,但理由欄重建了意圖
- 專門的回饋工具: 當 agent 卡住時,可以呼叫一個工具回報它在嘗試什麼、試了什麼、卡在哪裡
- 工具專屬的上下文參數: 在個別工具上加入目的導向的參數,捕捉只有 agent 端才知道的資訊
編按: Teddy 說了一句小編覺得很精準的話:「Agent 會幻覺,沒錯。但它們在回饋上比大多數人類用戶更具體、更一致。」想想看 — 如果你的理由日誌裡反覆出現「building incident report」這個模式,那就是一個新產品功能的信號。Agent 在告訴你的 agent 該建什麼。
注意上下文鴻溝
在任何 agent 之間的互動中,你的系統有對方 agent 沒有的上下文,反過來也是。Teddy 舉了一個費用報銷的例子:
使用者的 AI 秘書知道: 行事曆(哪些會議)、信箱(飯店和機票確認信)、通訊軟體(那頓跟客戶的晚餐)、收據照片
費用管理系統知道: 交易明細、公司報銷政策、會計科目代碼、歷史歸類模式
設計良好的 agent 互動不會要求會計科目代碼 — 它會問上下文: 這是客戶餐會、團隊聚餐、還是個人差旅? 秘書 agent 從行事曆找到答案,費用系統根據它缺少的上下文套用正確的代碼。
使用者和他的 agent 永遠不需要知道會計科目是什麼,財務團隊得到準確的分類。每一方貢獻自己知道的東西,各取所需。
總結: AX 是新的競爭戰場
拉回來看全局。AX 不是一個單一的技術選擇,而是一個多層面的設計思維:
- 發現、評估、推薦: 確保你的產品在 LLM 的世界裡能被看見、被理解、被選中
- 上手: 降低 agent 的入門門檻 — 認證走環境變數、提供 Skills 和沙盒
- 整合: 根據你的 API 複雜度選擇正確的抽象層級 — 為 agent 設計的命令列工具、根據意圖分組的 MCP 工具、或程式碼編排
- 設計哲學: 非互動式優先、漸進式揭露、可預測的結構、冪等操作、驗證所有輸入、錯誤訊息要可執行
Biilmann 說得好: 太多公司把精力花在「到處加 AI 功能」或「再建一個自己的 agent」。真正的突破是想清楚: 你的客戶最常用的 agent,要怎麼幫他們從你的產品中獲得更多價值?
Teddy Riker 最後那句話小編覺得是最好的收尾:
大多數公司會建一個 MCP 伺服器,打個勾,然後繼續下一件事。他們的使用量會成長幾季,然後停滯。最終,客戶會流向那些在細節上下了功夫的產品,繞過那些沒有的。用對待人類的心力去設計 agent 體驗。未來買單的不是人,是 agent。
參考資料
- Mathias Biilmann, Introducing AX: Why Agent Experience Matters (2025/1)
- Leonie Monigatti, Agent Journey Map: Designing Software for AI Agents (2026/3)
- Justin Poehnelt, You Need to Rewrite Your CLI for AI Agents (2026/3)
- Justin Poehnelt, The MCP Abstraction Tax (2026/3)
- Eric Zakariasson, Building CLIs for agents
- Teddy Riker, Designing for Agents
- Anthropic, Building agents that reach production systems with MCP (2026/4)
- Jeff Bailey, Fundamentals of Agent Accessibility (2026/4)
- LemonData, Agent-First API Design
- Amplifying.ai, What Claude Code Actually Chooses
- Cursor, CLI for Agents Skill
- ihower, 後 MCP 時代: Skills 取代 MCP 嗎? (2026/3)