Multi-Agent 架構再探: 三省六部反模式和業界收斂共識
去年六月 ihower 寫過一篇 AI Agent 架構比較: Multi-Agent 或 Single-Agent,當時的結論是「預設先用 Single-agent,特定場景才上 Multi-agent」。一年過去了,業界對 Multi-Agent 的理解更成熟了——但踩的坑也更多了。
這篇算是今年的觀察更新。前半段聊 Multi-Agent 的常見 anti-pattern,後半段整理目前主流推薦的架構設計。
先搞清楚哪些做法是 Anti-Pattern
1. 「更多 Agent 就更好」
這大概是最常見的迷思。Google Research 今年初的研究直接打臉了這個假設: 他們測了 180 種配置,發現 multi-agent 的效果完全取決於任務類型——在可並行的金融任務上提升 81%,但在需要順序推理的規劃任務上反而下降 70%。結論很明確: 架構與任務的匹配度,比 agent 數量重要得多。
更直接的證據來自 Stanford 今年四月的論文 Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets。他們用資訊理論的「數據處理不等式」(Data Processing Inequality) 論證: 在固定推理 token 預算下,單一 agent 的資訊效率更高。實驗跑了三個模型家族 (Qwen3、DeepSeek-R1、Gemini 2.5),結果一致——控制 token 用量後,single-agent 持平或優於 multi-agent。換句話說,很多 multi-agent 聲稱的效能提升,其實只是因為「花了更多 token」,不是因為「架構更好」。
編按: Arize AI 創辦人 Aparna Dhinakaran 也點出: multi-agent 架構產生的通訊開銷,使其在不易並行化的任務上不如單一、順序 agent 有效。Evals 不只要評估單一 agent,也要評估 multi-agent 架構本身。
2. 「三省六部幻覺」: 別把 Agent 當公司部門
這是 2026 年討論度最高的 anti-pattern 之一。@sujingshen 寫了一篇很火的長文「三省六部幻覺: 為什麼『虛擬公司』式多 Agent 架構在工程上不成立」,拿到了 1600+ 讚和 2400+ 收藏。
核心論點: 很多團隊把多個 Agent 分別命名為「產品經理」、「架構師」、「測試工程師」,讓它們像公司部門一樣傳遞文檔、協作完成任務。這個模式看起來很直覺,但有根本性的缺陷:
🔹 人類需要分工是因為注意力有限、有專業壁壘;但 LLM 沒有這些限制。同一個模型既能寫 PRD 又能寫程式碼,給它貼「測試工程師」的標籤不會讓它更專業,只會讓它拒絕越界。最有價值的推理往往發生在邊界上,而角色扮演在系統層面封死了這個可能性。
🔹 資訊在流轉中死亡。Agent A 產出文件傳給 Agent B,傳遞的是結論不是推理過程。每次傳遞都在累積誤差,工作流越長,最終輸出越「局部正確但整體漂移」——就像傳話遊戲一樣。
🔹 Anthropic、OpenAI、Google 三家自己建 Agent 系統時,沒有一家採用這個模式。他們用的是 orchestrator-worker 架構搭配外部狀態文件,不是角色扮演式的流水線。
Dify 的後端工程師 Yeuoly (周宇) 也寫了一篇長文分享實戰血淚。他們不到五人的小團隊嘗試給不同 Agent 分配 iOS 上架、UI 設計、工程開發等職責,結果他說「我的注意力爆炸了」——按工作職能拆出一堆 Agent,每個都要人去檢查和協調,人反而成了 Agent 之間的傳話筒。最後發現「好像去咸魚找個人會更快更好,自己還沒那麼累」。
3. 預設固定工作流的脆弱性
@aneeshpappu 的研究 “Multi-Agent Teams Hold Experts Back” 指出另一個問題: 大多數 multi-agent 系統使用預先指定的工作流程、固定角色和聚合規則。當任務複雜到無法提前規劃最佳工作流時,這些系統就會崩潰。@dair_ai 介紹的 OneManCompany 論文則提出,應該把 agent 當成可動態招募的人才市場,而不是固定的組織架構圖。
4. 生產環境的隱藏成本
一旦進入 production,multi-agent 的問題就會集體浮現:
🔹 成本非線性爆炸: Anthropic 自己的數據顯示,multi-agent 通常用 3-10 倍的 token,他們的 Research 系統更用了約 15 倍。Augment Code 的分析更直接: 「為什麼 3 個 Agent 要花 10 倍成本」——因為 context 複製、協調訊息、驗證層、重試迴圈加在一起是乘法效應。
🔹 錯誤放大效應: 如果每個 agent 有 90% 準確率,串三個就變 72.9%。根據 Google/MIT 的 agent 系統擴展研究,獨立 agent 的錯誤放大倍數高達 17.2 倍,即使加上中央協調也有 4.4 倍。
🔹 除錯地獄: 一篇 MAST 失敗分類學研究分析了 1600+ 個失敗案例,發現 7 個 SOTA 開源 multi-agent 系統的失敗率在 41% 到 86.7% 之間。很多失敗來自系統設計問題而非 LLM 能力不足,修改 prompt 是不夠的,需要結構性的重新設計。
🔹 生產級的十二個坑: Antigravity Lab 整理了 12 個常見陷阱,包括重試迴圈、token 失控、context 污染、級聯故障、可觀察性缺失等,每一個都是 prototype 階段看不到但 production 一定會遇到的。
那什麼時候該用?怎麼用才對?
聊完 anti-pattern,來看業界目前收斂出來的共識。
核心原則: 從簡單開始,必要時才加複雜度
這點是跨廠商的共識。Anthropic 說:「我們見過團隊花了好幾個月建構精緻的 multi-agent 架構,結果發現改進單一 agent 的 prompt 就能達到等效結果。」LangChain 也說:「先從單一 agent 和好的 prompt engineering 開始。先加工具,再加 agent。」OpenAI 的 Building Effective Agents 一文的開頭也是類似的建議。
Anthropic 的三個適用場景 (2026/1)
Anthropic 在一月發表的 Building Multi-Agent Systems 明確列出 multi-agent 比 single-agent 好的三種情境:
1️⃣ Context 隔離: 當子任務產生大量但無關的 context (如查訂單歷史 2000+ token),會「污染」主 agent 的推理品質。用 subagent 查完後只回傳 50-100 token 的摘要,保持主 agent context 乾淨。
2️⃣ 並行化: 需要同時探索多個獨立方向時 (如 Research 功能)。重點是「覆蓋面更廣」而非「速度更快」——平行 agent 其實常常比 single-agent 花更久,但搜尋空間大得多。
3️⃣ 專業化: 當工具數量超過 15-20 個,或不同任務需要衝突的 system prompt (例如客服要有同理心、code review 要嚴格挑錯),拆成專門的 agent 可以提升可靠性。
最關鍵的設計原則是「以 context 為中心拆分」,不是以問題類型拆分。寫功能的 agent 也應該寫它的測試,因為它已經擁有完整的 context。只有在 context 真的可以完全隔離時才拆開。
五種協調模式 (2026/4)
四月的 Multi-Agent Coordination Patterns 更進一步整理了五種模式 (宝玉有翻譯全文),以下用原文插圖快速過一遍:
1. Generator-Verifier (生成-驗證)
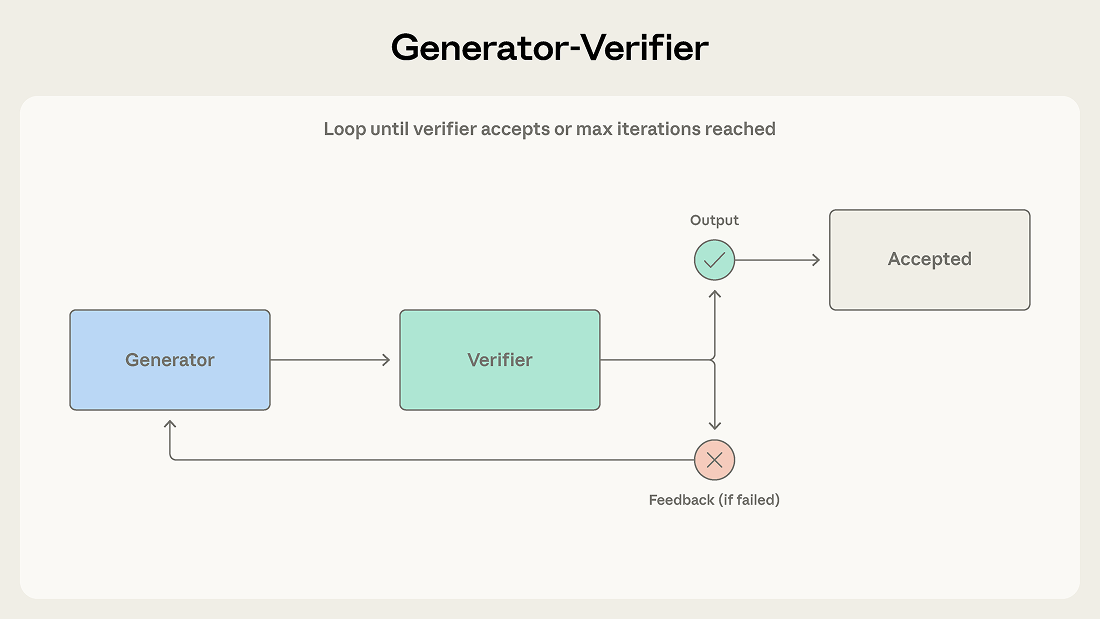
最簡單也最實用的模式。一個 agent 產出結果,另一個專門挑錯,不通過就打回去重做,直到通過或達到上限。適合程式碼生成 (一個寫、一個跑測試)、事實核查、合規檢查等看重品質的場景。關鍵是驗證標準要具體明確,否則驗證者就只是橡皮圖章。Cognition/Devin 的實戰經驗還發現,驗證 agent 不共享產出 agent 的 context 反而效果更好——乾淨的 context 讓它能更深入推理,不會被前面累積的雜訊干擾 (詳見下方 Cognition 段落)。
2. Orchestrator-Subagent (調度-子代理)
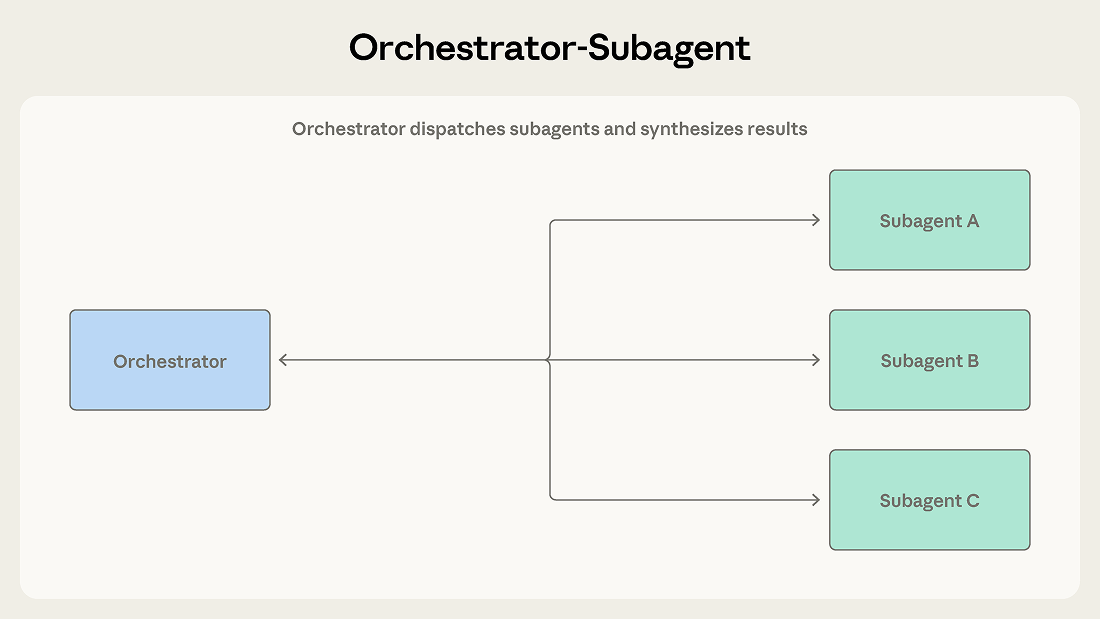
一個主 agent 負責規劃和分派,子代理各自處理子任務後回報結果。Claude Code 就是用這個模式——主代理自己寫程式碼,需要搜尋大型 codebase 時才派子代理出去。大多數情況建議從這個模式開始,它能處理最廣泛的問題且協調開銷最小。
3. Agent Teams (代理團隊)
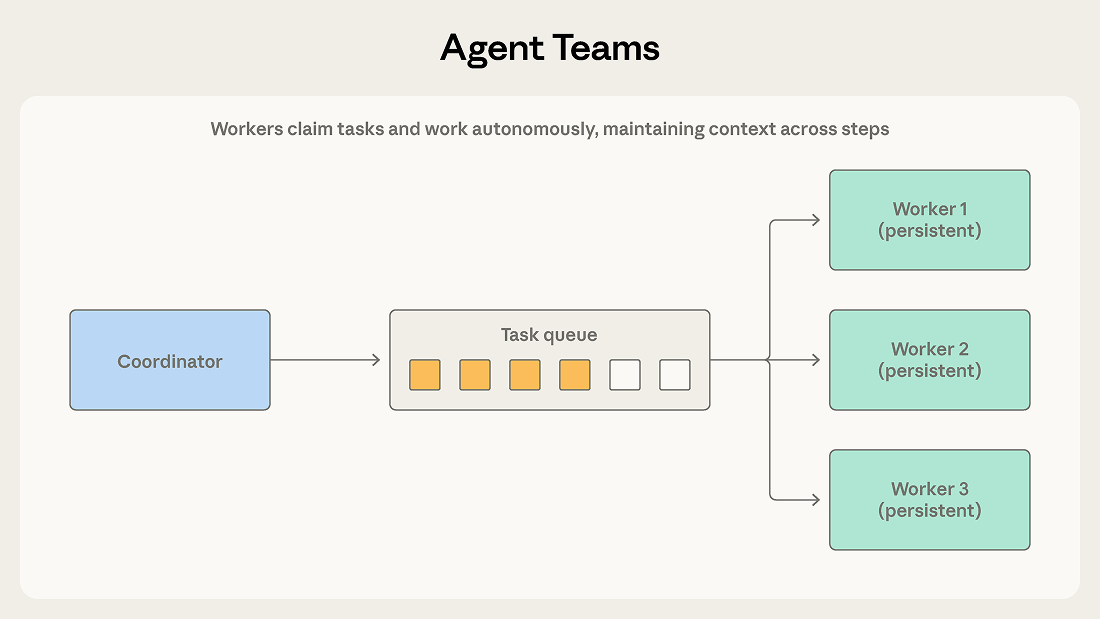
跟 orchestrator-subagent 的差別是 worker 會持續存活、累積 context,不是做完一個任務就消失。適合大型 codebase 遷移這類需要長時間、多步驟獨立工作的場景。但前提是子任務之間真的互相獨立,否則容易出現衝突。
4. Message Bus (訊息匯流排)
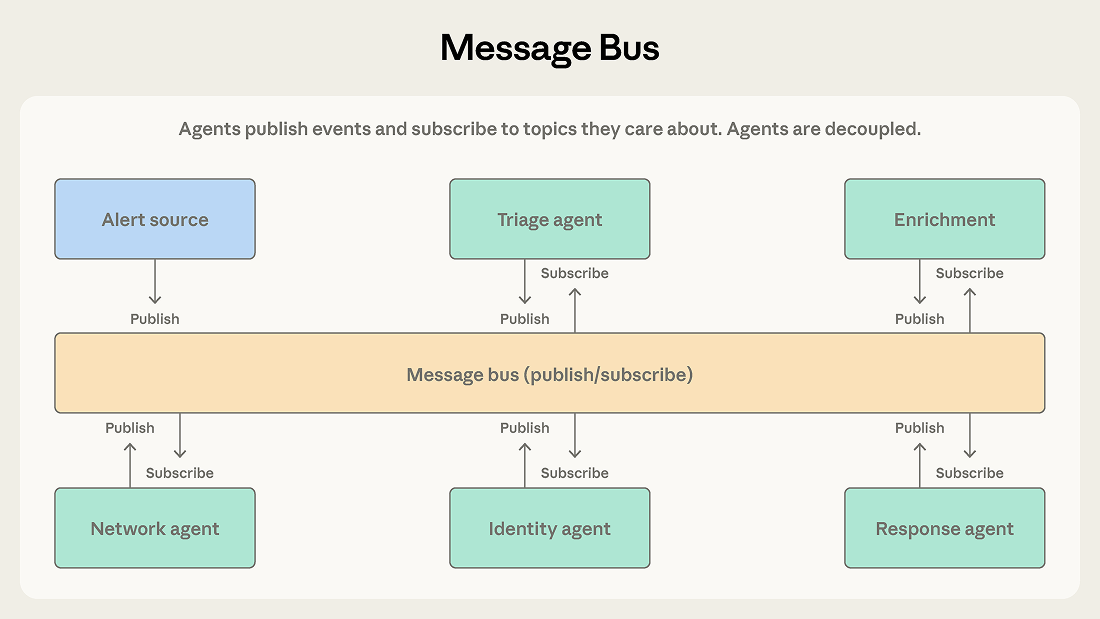
agent 之間透過發布/訂閱事件來溝通,不需要中央調度。適合事件驅動的流水線 (如安全警報處理系統),以及 agent 生態會持續擴展的場景。靈活但除錯困難——事件在五個 agent 之間串聯時,要追蹤發生了什麼事需要很仔細的 logging。
5. Shared State (共享狀態)
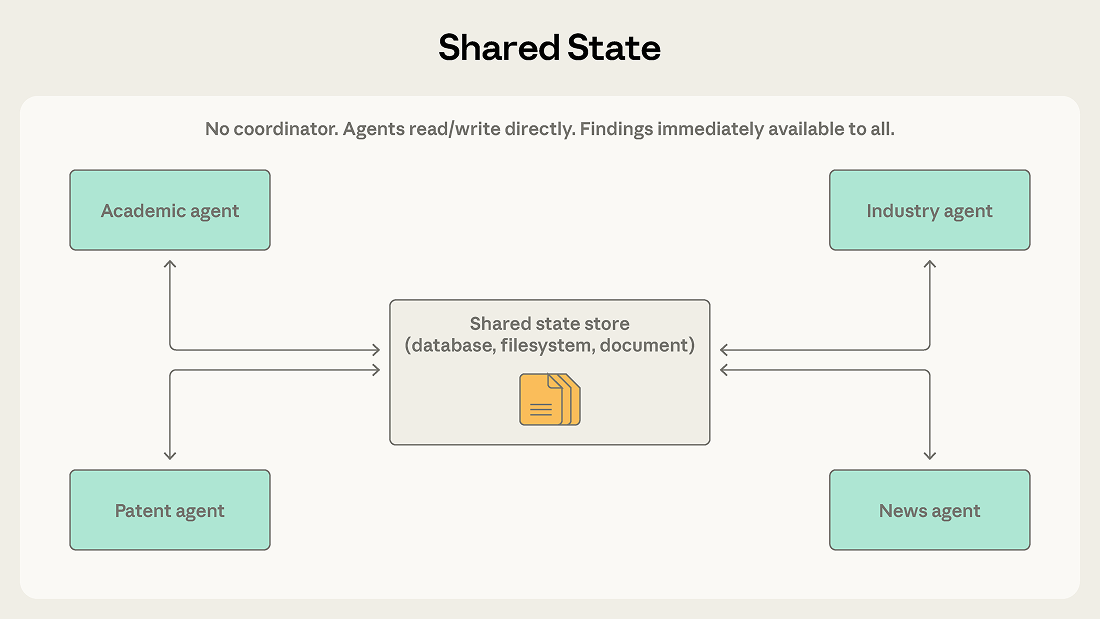
沒有中央協調者,所有 agent 透過讀寫同一個共享儲存 (資料庫、檔案) 來協作。適合研究綜合類任務——一個 agent 找到的線索,其他 agent 能即時看到並跟進。好處是沒有單點故障,壞處是容易出現重複工作和反應式迴圈 (A 寫了發現,B 看到後回應,A 又回應 B…),必須設好終止條件。
以上圖片來源: Anthropic Blog
小編補充幾點觀察:
🔹 大多數團隊從 Orchestrator-Subagent 開始就對了,它能處理最廣泛的問題且協調開銷最小。觀察哪裡撞牆,再往其他模式演化。
🔹 生產系統通常是混合模式: 整體用 orchestrator-subagent,某個高度協作的子任務內部用 shared state。這些模式是積木,不是互斥選擇。
🔹 Generator-Verifier 是投資報酬率最高的起手式: 只要加一個驗證 agent 就能顯著提升品質,不需要大改架構。很多團隊第一步就是從 single-agent 加一個 verifier 開始。
LangChain 的觀察: 讀取 vs. 寫入,以及四種架構模式
LangChain 在 2025 年中提出了一個蠻有洞見的區分: 「讀取型」任務的 multi-agent 比「寫入型」好管理。搜尋、研究這類讀取任務天生適合並行化,多個 agent 讀同樣的東西不會衝突;但寫程式碼、寫文件這類寫入任務,平行化就容易出現衝突的決策和難以合併的輸出。這也解釋了為什麼 Anthropic 的 Research 系統 (讀取型) 成功用了 multi-agent,而 Cognition/Devin 去年會說「不要用 multi-agent」——因為他們面對的是寫入型任務 (不過他們今年的立場有演化,見下一節)。
他們在 2026 年一月的架構選擇指南中,進一步整理了四種實作模式:
| 你的需求 | 推薦模式 |
|---|---|
| 多個不同領域 (日曆、Email、CRM),需要平行執行 | Subagents (子代理) |
| 單一 agent 有多種可能的專長,輕量組合 | Skills (技能) |
| 有順序的工作流,需要狀態轉換,agent 全程與用戶對話 | Handoffs (交接) |
| 不同垂直領域,平行查詢多個來源再綜合 | Router (路由) |
幾個有意思的實測觀察:
🔹 Subagents 和 Router 在多領域任務上效率最高,因為能平行執行且 context 隔離——處理三個語言的比較文件時,Subagents 的 token 用量比 Skills 少了 67%。
🔹 Skills 和 Handoffs 是有狀態的模式,在重複請求時能省 40-50% 的 API 呼叫,因為能記住之前的對話 context。
🔹 Handoffs 無法平行化,只能順序執行,所以不適合需要同時查多個領域的場景。
他們的結論也呼應了 Anthropic: context engineering 才是讓 agentic 系統可靠運作的核心。LangGraph 作為底層框架,刻意不藏任何隱藏的 prompt 或強制的認知架構,就是為了讓開發者完全掌控 context 的組成。
Cognition/Devin 的實戰驗證
Cognition 的 Walden Yan 在四月發了一篇「Multi-Agents: What’s Actually Working」,算是去年那篇「Don’t Build Multi-Agents」的續集。核心立場沒變: 平行寫入還是行不通,多個 agent 同時寫程式碼會產生隱性的風格和決策衝突。但他們找到了一類真正有效的模式——寫入動作維持單線程,其他 agent 只負責提供判斷,不負責動手做事。
他們分享了兩個具體實驗:
🔹 程式碼審查迴圈: 讓 Devin 寫完程式碼後,另一個 Devin Review 專門挑錯。平均每個 PR 抓到 2 個 bug,58% 是嚴重問題 (邏輯錯誤、邊界情況遺漏、安全漏洞)。最反直覺的發現是: 審查 agent 不共享寫程式 agent 的 context,效果反而更好。原因是寫程式的 agent 工作幾小時後會累積大量 context,注意力品質會隨長度下降 (他們稱為 context rot);審查 agent 從乾淨的 context 出發,只看差異,需要什麼資訊再自己去查,反而能更深入地推理。這跟 Anthropic 說的「context 隔離」不謀而合,但提供了更具體的機制解釋。
🔹 聰明朋友模式 (目前算失敗): 構想是用便宜快速的小模型當主力,遇到困難時呼叫大模型當「顧問」,藉此兼顧成本和品質。但他們坦承這個方向還沒成功——小模型 (SWE 1.5) 太弱,根本判斷不了「什麼時候該求助」,而這恰恰是整個架構最關鍵的決策。後續的 SWE 1.6 好一些但仍不到位。他們認為這本質上是個訓練問題,未來的模型需要在這種來回協作的環境中被訓練才行。唯一成功的變體是讓兩個前沿模型互相搭配 (例如 Claude + GPT),利用不同模型擅長不同子任務的特性來互補——但那就不是在省錢了,意義完全不同。
編按: 這個「小模型遇到困難時諮詢大模型」的方向,Anthropic 也在四月推出了官方實作 Advisor Strategy: Sonnet 自己完成工作,卡住時才向 Opus 請求建議。官方數據顯示 Sonnet + Opus 顧問比單獨 Sonnet 表現高 2.7 個百分點,成本反而低 12%。但同樣有「執行者過度自信而不求助」的問題,可見這個模式的核心難題是共通的。
他們也在做更高層級的委派: 由管理者 Devin 拆分大任務、派子 Devin 執行、透過 MCP 協調進度。但踩了不少坑——管理者缺乏程式碼庫 context 時會過度指揮、agent 誤以為跟子 agent 共享狀態、跨 agent 的溝通不會自動發生。至於無結構的 swarm 架構? 他們直接說是在繞遠路,實務上有效的形態是「拆分-執行-彙整」(map-reduce-manage)。
Walden 的文章有一個很好的總結: 所有 multi-agent 的待解問題,本質上都是溝通問題——弱模型怎麼知道該向強模型求助、子 agent 發現了什麼重要資訊該怎麼傳給兄弟 agent、怎麼傳遞 context 又不淹沒接收方。
業界收斂的 Best Practices
綜合 Anthropic、OpenAI、LangChain 以及各家生產經驗,幾條最重要的建議:
1️⃣ 先證明 single-agent 不夠用,再考慮 multi-agent。量化你的瓶頸: 是 context 不夠?工具太多?需要並行探索?如果改進 prompt 或用 context compaction 就能解決,就別加 agent。
2️⃣ 從 2-3 個 agent 開始,不要一口氣蓋大系統。每多一個 agent 都會增加除錯面積。
3️⃣ Day 1 就建 observability: 沒有 tracing 的 multi-agent 系統是不可能除錯的。LangSmith、OpenTelemetry 這類工具是必備的。
4️⃣ 設定成本上限和熔斷機制: 每個 task 設 token/金額上限。凌晨三點的 runaway agent 應該自動停掉而不是燒光 API 預算。
5️⃣ 驗證 agent 只負責挑錯,不負責接手執行: 如果你想加一個 agent 來做品質把關,它的職責就是「專門找前一個 agent 的問題」——跑測試、查事實、驗格式,發現問題就打回去讓原本的 agent 重做。它不會自己動手修,也不會接棒繼續往下產出。Anthropic 叫這個 Generator-Verifier 模式,兩個 agent 之間是對抗關係 (一個產出、一個否決),不是流水線關係 (一個做完交給下一個繼續做)。
6️⃣ 保持架構的可演化性: Anthropic 自己也發現,為 Sonnet 4.5 設計的 context reset workaround,在 Opus 4.5 上就變成了無用代碼。模型能力在快速提升,今天的 workaround 六個月後可能就是死重量。
再往前看: 動態子代理生成
上面整理的模式——不管是 Anthropic 的五種還是 LangChain 的四種——其實都還是在「設計時」就決定好 agent 的分工和流程。但有一個方向值得關注: 讓模型自己決定要拆幾個子代理、各自做什麼。
小編之前寫過 為什麼多數 Agent 框架都沒有內化 Bitter Lesson?,裡面引用 Minh Pham 的觀點: 現在多數 agent 架構都在做一件事——「模型不夠可靠,所以把可靠性寫進外層框架裡。」這在產品層面合理,但本質上是把複雜度從可規模化的部分 (模型) 搬到不可規模化的部分 (手工搭建的鷹架程式碼)。
「動態子代理生成」(Dynamic Subagent Spawning) 的核心思想是: 不要在設計時預先固定 agent 的分工和流程,而是讓模型在執行時根據任務需求自行決定怎麼拆解、要生成幾個子代理、各自做什麼。 這其實是一個光譜——一端是固定工作流 (拖拉式建構器),另一端是完全動態 (模型自己決定一切)。現實中大多數系統落在中間,但趨勢是往動態端移動。
目前已經有一些實作走在這個方向上:
- Anthropic 的 Research 系統: 主代理透過延伸思考動態決定任務分解,子代理是即時建立的新 Claude 實例
- Claude Code: 主代理可以把任務委派給子代理在獨立 context 裡執行
- LangChain Deep Agents: 提供任務工具讓主代理呼叫生成子代理
這個方向符合一個很好的檢驗標準: 如果模型能力明年翻倍,你的系統會不會在不需要大幅重構的情況下,變得更好? 如果 agent 的分工是動態的,模型進步時委派策略會「免費」變好;如果分工是硬編碼的,你就得手動重寫組織圖。
當然,短期內固定工作流在可預測性、可稽核性、成本控制上還是有優勢。但長期來看,最後勝出的 agent 架構會越來越像一個「算力分配引擎」,而不是一張手工打造的組織圖。
結語
一年前的結論——「預設 Single-agent,特定場景才用 Multi-agent」——不但沒過時,反而在 2026 年被更多的論文和生產經驗驗證了。但有進步的是,業界對「特定場景」有了更清晰的定義 (context 隔離、並行搜尋、工具專業化),對「怎麼做」也有了更成熟的模式 (五種協調模式及選擇框架),對「未來往哪走」也有了方向 (動態子代理生成)。
如果非要記住一句話: Multi-Agent 的價值是並行覆蓋,不是分工。最好的 multi-agent 系統不像公司,更像一個思考者的多次草稿——同一個大腦在不同維度展開推理,最終合併成一個連貫的結論。
延伸閱讀:
- Anthropic: Building Multi-Agent Systems (2026/1)
- Anthropic: Multi-Agent Coordination Patterns (2026/4)
- LangChain: Choosing the Right Multi-Agent Architecture (2026/1)
- LangChain: How and When to Build Multi-Agent Systems (2025/6)
- Stanford: Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets (2026/4)
- Cognition: Multi-Agents: What’s Actually Working (2026/4)
- 三省六部幻覺: @sujingshen 全文 (2026/4)