LLM Knowledge Base: 用 LLM 編譯個人知識庫,各路實作全比較
Andrej Karpathy 四月初在 X 上發了一篇推文,講他怎麼用 LLM 來建個人知識庫,2100 萬次觀看、近 6 萬個讚,直接引爆了一波熱潮。接下來幾天各路高手紛紛分享自己的做法,從極簡版到工程級都有。
小編把 Karpathy 的原始構想、社群裡幾個有代表性的實作,以及 DAIR.AI 的 Elvis Saravia 整理的教學版一起做個比較。重點不是哪個「最好」,而是幫你搞清楚不同設計決策背後的取捨,找到適合自己的起手式。
核心概念: 不是 RAG,是「編譯」
先講最重要的事: Karpathy 提出的模式跟大家熟悉的 RAG 完全不同。
RAG 的做法是每次問問題時,從原始文件裡撈相關片段,然後讓 LLM 即時拼湊答案。問題是知識每次都從零開始重建,沒有累積。問一個需要綜合五篇文章的複雜問題,LLM 每次都得重新找、重新拼,效率很差。
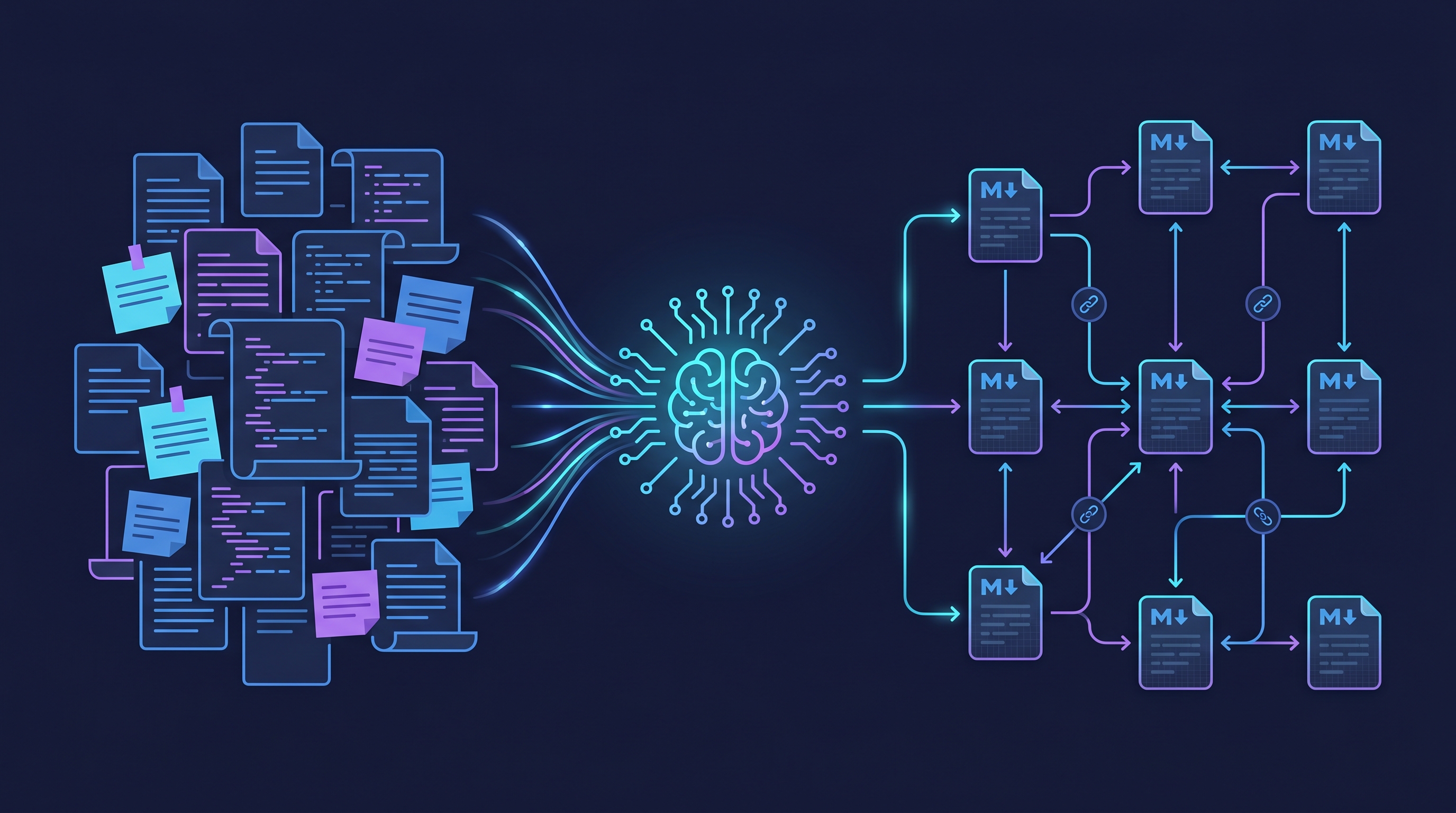
Karpathy 的做法是把 LLM 當「編譯器」: 原始資料進來之後,LLM 不只是索引它,而是讀懂、摘要、分類、交叉連結,把知識「編譯」成一座結構化的 Markdown wiki。知識被寫進結構裡,下次查詢時直接從 wiki 裡找,不用每次從零推導。
用他自己的類比: Obsidian 是 IDE (你在上面瀏覽)、LLM 是寫程式的人 (它負責寫和維護 wiki)、wiki 就是程式碼庫 (你幾乎不直接動手編輯)。
Karpathy 的原始架構: 三層 + 四個動作
Karpathy 後來在 GitHub Gist 發了一份更完整的構想文件,把架構講得更清楚。核心是三層:
🔹 raw/ — 原始資料,只讀不改。文章、論文、程式碼、圖片,用 Obsidian Web Clipper 一鍵存入
🔹 wiki/ — LLM 編譯出的知識庫。摘要、概念頁、實體頁、交叉引用,全部由 LLM 維護,人不碰這層
🔹 Schema (CLAUDE.md) — 告訴 LLM 怎麼維護 wiki 的規則文件。命名規範、引用規則、匯入流程、查詢方式,全寫在這裡。這個檔案是讓 LLM 從「通用聊天機器人」變成「有紀律的 wiki 維護員」的關鍵
四個動作形成閉環:
- 匯入 (Ingest): 新資料進
raw/,LLM 讀取後更新 wiki,一次可能動到 10-15 個頁面 - 查詢 (Query): 問問題時 LLM 從 wiki (不是 raw) 查答案
- 回寫 (File back): 有價值的問答結果寫回 wiki,讓知識持續累積
- 健檢 (Lint): 定期跑健康檢查,找矛盾、補缺漏、發現新的研究方向
Karpathy 自己在某個研究主題上累積了約 100 篇筆記、40 萬字。他說本來以為需要搞 RAG 管線,結果發現在這個規模下,LLM 靠自動維護的 index.md 加上摘要就能搞定,根本不需要向量資料庫。
他最後留了一句:「我覺得這裡有空間誕生一個了不起的產品,而不只是一堆雜七雜八的腳本。」
各路實作比較
Karpathy 刻意把構想文件寫得很抽象——只講概念模式,不講具體實作。結果社群裡幾天內就冒出一堆版本。以下挑幾個有代表性的來比較。
1️⃣ Elvis Saravia / DAIR.AI — 最清楚的教學版
DAIR.AI 的 Elvis Saravia 寫了兩篇文章,第一篇整理架構,第二篇手把手教你從零建起來。後來還做了一個 Wiki Builder 的 Claude Code 外掛。
Elvis 版的特色是極度簡潔: raw/ 放原始素材、wiki/ 放編譯結果 (含論文頁、概念頁、趨勢頁等子目錄)、derived/ 放問答產出、prompts/ 放可重複使用的編譯指令。
他用 AI Papers of the Week 當範例,從三份週報出發,示範完整的匯入 → 編譯索引 → 建論文頁 → 建概念頁 → 提問 → 回寫 → 健檢流程。走完一輪就知道這套東西怎麼運作了。
小編覺得這是入門首選,簡單明瞭,不會被複雜架構嚇到。
2️⃣ Yanhua — 精簡實用版 + 防腐化規則
Yanhua 在 X 上分享的版本也很精煉,把目錄簡化成三層:
原料/— 只讀,LLM 不可修改摘要/— LLM 結構化編譯產物沉淀/— 每次高品質問答的答案落檔
他特別強調兩個「元文件」的作用:
CLAUDE.md: 放在根目錄,是控制 LLM 行為的「最高憲法」,每次會話必讀index.md: 全局目錄,每篇筆記加一行摘要。LLM 檢索時先掃索引,再決定要不要深讀全文,大幅省 token
最有價值的是他的「防腐化規則」: 重要斷言必須有來源連結、新舊衝突時報差異不默默覆蓋、區分「原文事實」和「推論」。這些寫進 CLAUDE.md,知識庫才不會幾個月後變成 LLM 幻覺的堆積場。
3️⃣ 范凱 — 四層工作流版
范凱的 llm-knowledge-base 是目前社群裡做得最完整的開源範本之一。他把 Karpathy 的三層擴展成四層:
raw/ ← 原始素材 (只讀)
wiki/ ← LLM 編譯的知識 (摘要 + 概念 + 索引)
brainstorming/ ← 探索紀錄 (問答、健檢報告)
artifacts/ ← 你的成品 (文章、報告)
跟 Karpathy 原版最大的差別是: Karpathy 的架構偏向「由上往下管理」(schema 管 wiki 管 raw),范凱的偏向「工作流式」——知識在不同階段間流動。他自己既是知識的生產者也是消費者,所以需要雙向編譯跟與 LLM 討論的階段。
他還附了 6 個 Claude Code 指令 (/compile、/health-check、/thinking-partner、/write-partner 等),降低上手門檻。
編按: 范凱在 README 裡寫的反思蠻有意思的——他說真正的問題從來不只是工具。以前用「第二大腦」方法論,摩擦力來自整理本身;現在把整理交給 AI,摩擦力沒消失,只是變成了「對話裡那些你答不上來的問題、那些被指出的矛盾」。
4️⃣ Tim Feng — 語義分層版 + 漸進式披露
Tim Feng 在 Facebook 分享了一個蠻獨特的架構,把知識庫分成三層語義結構:
sources/— 原始文本 (書、文章、影片逐字稿),一定保留原文不摘要thoughts/— 讀後心得,跟 sources 一對一對應,每篇來源都有同名心得projects/— 實作產出,每個專案都有說明文件
每層各有一個 INDEX.json (不是 Markdown,是 JSON),包含標籤、摘要、檔案連結。設計靈感來自 Claude Code 的 Skill 機制: LLM 啟動時先載入所有索引,只看摘要和標籤,需要時才深讀全文——他稱之為「漸進式披露」。
他還有個特別的 CONCEPTS.md,記錄「跨心得重複出現的共通概念」。如果一個概念在不同來源反覆出現,就值得獨立抽出來。
工作流也蠻完整: 新來源進來會自動跟現有資料庫做比對,找出「起始共鳴」(可能的關聯),寫進同名的心得檔裡。日後有新專案,LLM 會透過三份索引去搜尋所有可能相關的素材。
5️⃣ Garry Tan / GBrain — 工程級知識圖譜
GBrain 是 Y Combinator 總裁 Garry Tan 做的,跟前面幾個完全不是同一個量級。這不是一個概念模式,是一套完整的知識基礎設施:
- 17,888 頁、4,383 人物、723 家公司,21 個排程任務自動跑
- 用 Postgres + pgvector 做混合搜尋 (向量 + 關鍵字 + 知識圖譜 + 重排序)
- 自動建立有型別的關係連結 (出席、任職、投資、創辦等),不需要額外的 LLM 呼叫
- 自動匯入: 會議、信件、推文、語音通話,全部自動關聯
- 43 個預設技能,從訊號偵測到引用修正都有
GBrain 的頁面模型是「編譯後的當前最佳論述」加上「只增不刪的時間軸證據鏈」。搜尋是關鍵字 + 向量 + 倒數排名融合的工程級組合,測試顯示知識圖譜比純向量搜尋的精準度高了 31.4 個百分點。
簡單說,如果 Karpathy 的是「用筆記本管研究資料」,GBrain 就是「用 ERP 系統管整間公司的知識資產」。
6️⃣ Tobi Lütke / QMD — 本地搜尋引擎
Shopify 執行長 Tobi Lütke 做的 QMD 走的是另一條路: 不幫你建 wiki,但幫你在既有的 Markdown 檔案上做極致搜尋。關鍵字比對 + 向量語意 + 查詢擴展 + LLM 重排序,全部在本地跑,不上雲端。
QMD 跟 Karpathy 的 wiki 其實是互補的: wiki 長大之後需要更好的搜尋能力,QMD 剛好補這塊。Karpathy 本人也推薦過 QMD 作為 wiki 的搜尋層。
其他社群衍生專案
除了上面幾個之外,社群裡還冒出了大量衍生工具,例如 SwarmVault (本地優先、內建知識圖譜)、llm-wiki.net (Claude Code 外掛、支援多 agent 平行研究)、OpenKB (支援 PDF/Word/PPT 等多格式匯入)、sage-wiki (Go 寫的單一執行檔、內建 MCP 伺服器) 等。大多是 Karpathy 原始概念的不同包裝,核心架構差異不大,但各自在特定場景 (離線使用、多格式支援、多 agent 整合) 上做了延伸。
關鍵設計決策比較
把這些實作攤開來看,幾個核心設計決策的差異:
| 層數 | 索引方式 | 搜尋方式 | 適合規模 | 特色 | |
|---|---|---|---|---|---|
| Karpathy 原版 | 3 層 | index.md | 索引 + 全文 | ~100 篇 | 概念定義者 |
| Elvis/DAIR.AI | 3+1 層 | index.md | 索引 + 全文 | 教學示範級 | 最佳入門教學 |
| Yanhua | 3 層 | index.md + 摘要 | 先掃索引再深讀 | 個人筆記級 | 防腐化規則 |
| 范凱 | 4 層 | indexes/ 目錄 | 索引 + 全文 | 個人筆記級 | 工作流 + 討論層 |
| Tim Feng | 3 層 | INDEX.json | 漸進式披露 | 個人筆記級 | 語義分層 + 共鳴 |
| GBrain | 資料庫級 | Postgres | 混合搜尋 + 圖譜 | 萬頁級 | 知識圖譜 |
怎麼選?
這些做法看起來差異不小,但背後的核心觀念是一致的: 原始資料唯讀、wiki 由 LLM 全權維護、用 schema 文件約束 LLM 的行為。差別主要在於你的使用情境和規模。
如果你還沒試過,最快的起手方式是把 Karpathy 的 llm-wiki.md 丟給 Claude Code,說「幫我建一個知識庫」,五分鐘就能跑起來。或者照 Elvis Saravia 的教學走一遍,先感受整個工作流再說。
想要現成架構可以直接用的,范凱的 llm-knowledge-base 是目前最完整的開源範本,clone 下來、資料丟進 raw/、跑 /compile 就行。四層架構比較適合同時是知識「生產者 + 消費者」的人。
不管用哪個版本,有幾件事值得從第一天就注意:
- 寫好你的
CLAUDE.md: 這是整套系統最重要的檔案。命名規則、引用格式、衝突處理方式,都要寫清楚,不然 LLM 每次會話的行為都不一致 - 做好防腐化: 把 Yanhua 的規則搬過來——來源追溯、衝突報差異而非靜默覆蓋、區分事實與推論。這決定了知識庫三個月後還能不能信任
- 不要急著上向量資料庫: Karpathy 自己 40 萬字都還不需要。在這個規模下,一份維護好的索引檔就夠用了。等到
index.md真的塞不下,再考慮 QMD 或 pgvector - 讓問答結果回寫到知識庫: 這是整套模式最容易被忽略但最有價值的部分。每次提問的好答案如果只停留在對話紀錄裡,就浪費了。寫回 wiki 讓知識持續複利
更大的啟示
LLM Knowledge Base 之所以引起這麼大的迴響,不只是因為它解決了「筆記整理很煩」這個問題。它背後是一個更根本的思維轉換: LLM 不只是回答問題的機器,而是知識的基礎建設。
傳統的知識管理工具——Notion、Roam、Obsidian——都把整理的苦工甩給人做。大多數人最終放棄,不是沒毅力,是維護成本超過了回報。這套模式把成本轉移給 AI: 人負責找素材、定方向、問好問題;AI 負責摘要、連結、一致性維護。
而且這不限於個人筆記。團隊知識庫、研究文獻管理、投資研究、產品文件——任何「持續有新資料進來、需要被結構化整理、會被反覆查詢」的場景都適用。
不過就算沒有完美的產品,這套做法現在就能用。挑一個版本,花半小時建起來,把你最近在研究的主題丟進去。看到 LLM 自動把散亂的文章編譯成有結構、有交叉連結的 wiki,你會理解為什麼 Karpathy 說他現在「花更多 token 在操作知識,而不是操作程式碼」。