如何讓 AI 協作越用越順? Eugene Yan 五層複利工作法完整解讀
小編最近看到 Eugene Yan 寫的這篇 How to Work and Compound with AI,覺得資訊密度很高蠻有料的,值得好好解讀一下。
先介紹一下作者: Eugene Yan 目前在 Anthropic 工作,之前是 Amazon 的 Principal Applied Scientist、也在阿里巴巴帶過 ML 團隊,長期經營個人部落格分享 ML 和 AI 工程實務,在業界蠻有影響力的。
這篇文章本質上是一份個人 AI 工作流的深度分享——Eugene 以自己日常使用 Claude Code 的經驗為主,詳細講他怎麼組織檔案、設定偏好、建立自動化工作流、同時開多個 AI session 來並行開發。雖然範例都圍繞在個人工作情境,但他在結尾點出: 同一套原則換到 agent 框架設計、團隊規範、組織基礎設施的層次,一樣完全適用。
這篇不是那種「10 個 Prompt 技巧」的速食文,而是一整套讓 AI 協作能「越用越順」的方法論。核心概念是「複利」(compound): 每完成一件事,產出的程式碼、文件、決策都變成下一次的 context;每一次修正,都變成減少未來錯誤的 config。你不只是在完成任務,而是在「訓練一個協作者」。Eugene 也點出: 這些原則其實不是 AI 專屬的,跟任何新同事協作都是同一套邏輯。
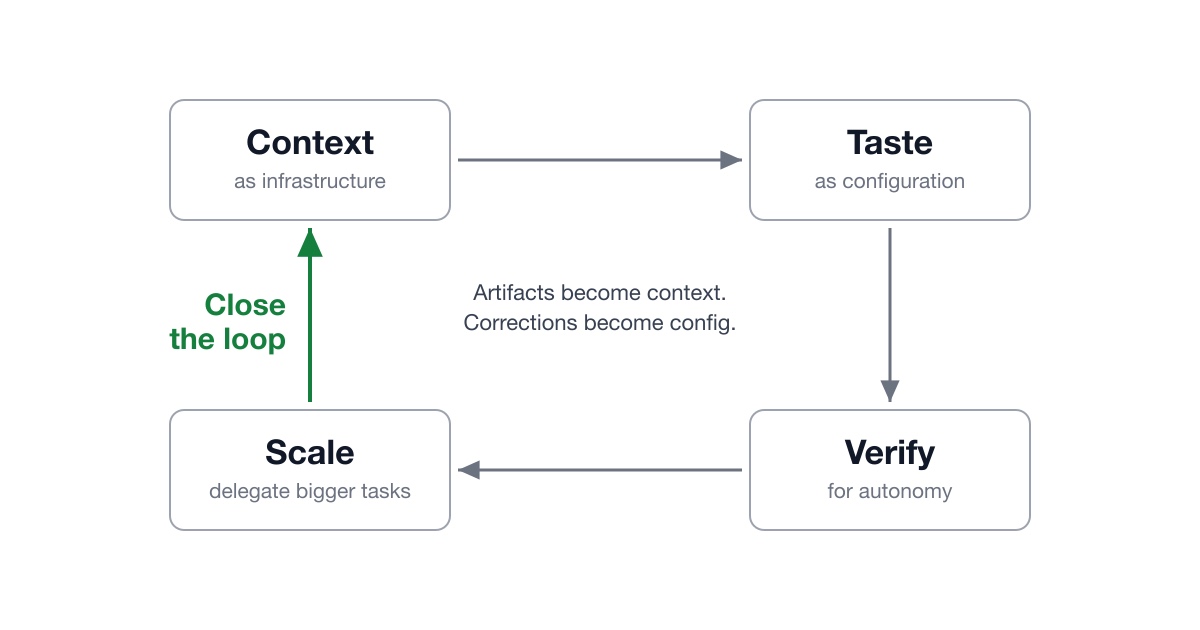
文章分五個層次,小編覺得這個架構蠻漂亮的,每一層都建立在前一層之上:
1. Context 即基礎建設
第一層講的是: 你的資料夾結構和文件組織方式,本身就是一種基礎建設。
Eugene 的做法是程式碼統一放 ~/src,知識工作放 ~/vault(再細分 projects/、notes/、kb/)。這不只是個人的整潔癖好——當檔案結構夠乾淨,AI 用 grep 或 glob 就能快速找到需要的 context,也更容易參考之前的程式碼、專案文件和分析結果來提升當前工作的品質。
除了本地檔案,組織內的知識通常散落在 Slack、Google Drive、Email 等地方。Eugene 會透過 MCP 把這些外部工具接進 Claude Code,讓模型也能讀取組織脈絡。此外,每個專案他會維護一份 INDEX.md,裡面放相關文件的連結、負責人、以及「這份文件是幹嘛的、什麼時候該看」的簡短說明。重點在那段說明——如果只丟一堆 URL,模型就得一個一個打開才知道哪個跟當前任務有關,浪費時間也浪費 context window。先幫它做一次「策展」,後面每個 session 都省事。
另一個關鍵觀念: 每次新 session 都要當成新人 onboarding。AI 模型每次都是從零開始、沒有前一次對話的記憶,所以 CLAUDE.md 要寫得像給新同事的第一天入職手冊——包含縮寫對照表、專案代號、同名同事怎麼區分、以及「先讀什麼再讀什麼」的建議閱讀順序。
記憶層的設計也有講究: Eugene 把需要持久化的資訊分成兩個桶。~/vault 放事實性資料(專案狀態、產出物、領域知識),~/.claude(包含 CLAUDE.md、skills/、guides/)放偏好、工作流程和個人品味。前者提供 context(你在做什麼),後者提供 config(你希望怎麼做)。這個區分蠻重要的——兩者的更新頻率和用途完全不同。
2. 品味即設定檔
這一層是整篇文章最多人討論的概念。你的審美、偏好、工作標準,都可以被編碼成 AI 的設定檔。
Eugene 把他的 CLAUDE.md 當成一份「行為合約」(behavioral contract)——不只是告訴模型「你是什麼角色」,而是精確定義他期望的互動方式:
- 「不確定的時候直接說不確定,不要自信地猜」
- 「如果你不同意,直接反駁」
- 「出錯時先查根本原因,不要直接重試」
- 「diff 要限縮在任務範圍內,不要順手重構不相關的程式碼」
他甚至還設定了「教學模式」: 當出現他可能還沒內化的關鍵術語時,模型要用 1-2 句話解釋,然後繼續往下走。
這些設定按作用範圍分層放: 全域偏好(行為、長期目標、教學)放 ~/.claude/CLAUDE.md,repo 層級的慣例(linting、命名、PR 規範)放 repo 根目錄,專案特定的 context(目錄結構、領域知識)放專案目錄。Claude Code 啟動時會沿著目錄樹往上找,每一層的 CLAUDE.md 都會載入。
當 CLAUDE.md 長到變成 context 負擔怎麼辦? 拆成「懶載入」的 guide 檔案——不要用 @import(那等於直接內嵌,每次都載入),而是在 CLAUDE.md 裡告訴模型「寫文件的時候去讀 ~/.claude/guides/writing.md」。這樣做 eval 的 session 就不會載入寫文件的指南,按需取用,省 context。
Skill: 把重複工作變成可執行的工作流
如果一件事每週做一次以上,就該做成 skill。Skill 是用 markdown 寫的工作流程,包含名稱、觸發條件和執行步驟,而且可以包含判斷邏輯——不只是死板的 checklist,而是「根據情況決定走哪條路」的決策樹。Eugene 舉了幾個他自己的 skill:
/polish: 看 diff,如果產出有指標就跑 eval,如果有 UI 就用 Chrome 檢查,都沒有就跑程式看 output,反覆迭代到沒有重大問題,最後開 PR/write: 先訪談釐清大綱、派研究 subagent、寫初稿、用對抗式批評者給回饋、迭代到沒問題/daily: 讀行事曆、Slack、PR、昨天的 log,寫出今天的優先事項
設計上有個原則: Skill 本身要保持精簡,只放工作流程和路由邏輯。 具體的知識(模板、腳本等)放在另外的檔案裡,模型需要時才去讀,跟 guide 一樣是懶載入的思路。
怎麼建 skill? 不用從零寫——先手動做一遍,再讓模型幫你變成 skill。流程是: 正常做一次任務 → 請模型把剛才做的事轉成 skill → 在同類任務上跑跑看 → 在同一個 session 裡修正問題 → 請模型根據修正更新 skill。你也可以直接餵範例 output 給模型,讓它自己抽取模式——比如你平常怎麼組織程式碼、文件的結構和語氣等。幾輪迭代之後,skill 就會收斂到幾乎不用改 output 的程度。
這裡有一個很重要的細節: 修正要在 session 內做,不要直接去改 SKILL.md 檔案。 為什麼? 因為第一版 skill 幾乎一定不完美——它會 overfit 到你第一次做的那個案例。在 session 內修正,模型可以看到「原本產出什麼 → 你期望什麼 → 為什麼要改」的前後對照,這些 before/after pairs 累積在 transcript 裡,等到 output 修到滿意了,再請模型把這些回饋合併回 skill,效果遠比直接編輯檔案好。
不過 Eugene 也提醒,不是每件事都需要全套裝備。腦力激盪、探索性分析、打草稿這類工作,他會用 simple mode(CLAUDE_CODE_SIMPLE=1 claude),CLAUDE.md 還是會載入,但 hook、skill 這些 agentic 機制不會啟動。有時候你想要的是更直接地跟模型對話,不是一整個自動化流水線。
3. 驗證機制決定自主程度
這一層是社群討論度最高的,很多人都說這是整篇文章最關鍵的一環。道理很直覺: 你能給 AI 多少自主權,完全取決於你的驗證機制有多好。
Eugene 把驗證想成一個「階梯」,同時提出「驗證左移」(shift verification left) 的概念——盡量在寫程式的當下就抓到問題,而不是等到後面:
- 底層(便宜、確定性高): post-edit hook 自動跑 formatter 和 linter(例如
ruff format、ruff check --fix),不花 token,完全確定性 - 中層: 測試、eval
- 頂層(昂貴、需要判斷力): LLM review
原則是盡量在最低層解決問題。能用 linter 自動修的格式問題,就不需要用 eval 去抓。
更關鍵的是: 讓模型擁有自我驗證的能力。 給它 feedback loop,讓它能看到自己的產出效果然後改進。Eugene 舉了幾個具體場景:
- 建 Docker image 時,讓模型自己 build、讀 error、改 Dockerfile、再 build,直到成功
- 調整 agent 框架時,讓模型跑 eval、讀 transcript、修掉失敗的 case
- 做 dashboard 時,讓模型用 Chrome 檢查 tooltip 有沒有正常顯示、label 有沒有重疊、數據敘述跟圖表是否一致
重點是不能「做完就算」,要有閉環的回饋機制。
對於長時間運行的任務,Eugene 還用了一招: 讓模型監督模型。 開兩個 tmux pane,一個跑主要開發、一個跑「結對程式設計師」。主要開發的初始指令和後續追加的 prompt 會寫進一個共享檔案。結對程式設計師定期啟動,用全新的 context 去比對原始 spec 和主 session 最近的操作,發現偏差就回饋修正。
他把偏差分兩種,分別對應不同的檢查頻率:
- 執行漂移 (execution drift): 戰術層面——忽略了某個 error、回報錯誤的指標、偏離 spec。要經常檢查
- 方向漂移 (direction drift): 策略層面——模型誤解了原始意圖,花好幾個小時在做錯的事。偶爾檢查就好
編按: 推特上有人分享實戰經驗——跑 multi-agent 半年下來,即使有 eval rubric,自我驗證的失敗率還是高達 40%。最後他們改用獨立的 reviewer agent 來審查所有不可逆操作,算是最接近「斷路器」(circuit breaker) 的可行方案。
4. 透過委派來擴展
當驗證機制夠可靠,就可以開始委派更大塊的工作了。Eugene 點出一句很關鍵的話: 你沒辦法委派你無法驗證的事。 所以第三層(驗證)是第四層(委派)的前提——你得先定義好成功標準和指標,才有辦法放手讓模型去做。
一開始跟 AI 協作,大部分人的模式是 pair programming: 短任務、快速回饋、全程盯著。這對快速迭代和原型開發很好用。但隨著模型越來越強,應該漸漸往「委派」的方向移動——把意圖、限制條件、成功標準講清楚,然後讓模型端到端地執行。這個轉變是從「一次給一條指令」變成「給一份完整的計畫書,讓模型自己執行」:
「拿這些 eval suite,為每個 suite 建隔離的容器並確認能 build。然後跑完整的 eval,記錄指標和 transcript,用 subagent 讀 transcript 確認 eval 有正確執行。每個 eval 跑 n 次算信賴區間。最後生成報告,確認符合報告格式,然後把結果和報告連結發到 Slack。」
能委派大任務之後,自然就能同時跑更多 session。Eugene 說他通常同時開 3 到 6 個 session。如果共用同一個 repo,就用 git worktree 讓每個 session 有自己獨立的 checkout,避免互相覆蓋。
這時候瓶頸已經不是「做事」,而是「寫夠清楚的 spec」和「review output 的速度跟不上」——中間執行的部分正在被掏空。
同時跑多個 session,可觀察性就變得很重要了。Eugene 的做法是:
- stop hook 在 session 完成時播音效,耳朵就知道有東西做完了
- tmux title 用 emoji 標狀態(⏳ 進行中、🟢 完成)加上用 Haiku 模型自動生成的簡短標籤,眼睛掃一眼就知道每個 pane 在幹嘛
- status line 顯示 context 使用量和當前模式
甚至人不在電腦前時,還可以用 Claude Code 的 /remote-control 功能,從手機上的 Claude App 檢查各 session 的進度,幫卡住的 session 補充 context 或新指令。不過 Eugene 也提醒: 這是給真正有事需要處理的時候用的,不是讓你在散步的時候還盯著螢幕。
5. 關閉迴圈,形成複利
最後一層是讓整個系統能「自我改善」——這也是「複利」這個比喻的核心所在。
第一步: 在公開場合工作。 把產出放在共享的 repo、文件、頻道裡,讓 AI 和隊友都能取用。今天分享的東西,明天就變成組織的 context。Eugene 甚至在 CLAUDE.md 裡設定了指令,讓 AI 每次完成重要任務就自動在 worklog 頻道發更新(附上 PR 或文件連結)。
他提了一個簡單的自我檢驗: 新來的隊友能不能只靠共享的 context 就重現你上週的工作? 如果不能,代表有價值的 context 還卡在你腦袋裡,沒有進入組織的知識循環。
第二步: 挖掘 transcript 來改進設定。 這一步蠻有意思的。Eugene 掃了大約 2,500 個他自己過去的 user turn,發現有不少比例包含「can you also…」(你可以順便…)、「did you check…」(你有檢查…嗎)、「still wrong」(還是錯的)之類的修正用語。這些修正每一個都代表: 模型本來應該主動做但沒做的事,而且很可能下次還是不會做——除非你更新 CLAUDE.md 或 skill。出現次數告訴你哪些問題最頻繁,transcript 內容告訴你具體哪裡出了問題。這也是為什麼前面強調「修正要在 session 內做」——因為 transcript 就是你之後改進設定的原料。
第三步: 定期重構設定檔。 Config 會長大、會重疊、會互相矛盾。如果模型忽略了某條規則,不見得是模型笨,很可能是另一條規則跟它衝突了。Eugene 的做法是定期清理: 每條規則只存在一個地方(特別重要的可以在主 CLAUDE.md 重複一次),零散在各目錄的 settings.json 要定期收回 ~/.claude 統一管理。
小編觀察
推特上的迴響蠻有意思的。最多人討論的是「驗證決定自主權」——好幾個人都指出,大部分團隊在這一環投資不足,急著委派卻沒有建好驗證機制,結果就是「更有自信地犯更多錯」。
「品味即設定檔」(taste as config) 這個 framing 也引起不少共鳴。有人說得蠻精準的:「大家都在談 RAG 和 fine-tuning,沒人想承認真正的瓶頸是團隊沒有品味,而品味沒辦法 pip install。」
「關閉迴圈」則是最容易被忽略的一環。有人提到: 很多團隊花力氣做好了前面四層(context、taste、verification、delegation),就是忘了收集回饋。結果 agent 第一天很好用,三個月後悄悄退化,因為缺了複利機制讓它持續進步。
最後,Eugene 在結尾寫了一句蠻好的總結:「我們做的事情,本質上就是在訓練一個協作者——一次回饋一次。」(What we’re doing is training a collaborator, one feedback at a time.) 他也在推特補充: 這篇不只是在講個人工具,把視角換成「Agent 框架」、「團隊規範」、「組織基礎設施」,重讀一遍,你會發現同一套原則完全適用。
原文: How to Work and Compound with AI by Eugene Yan / X 討論串