AI 時代的 Code Review: 當 Pull Request 成為新瓶頸

最近蠻多人在討論 AI coding agent 帶來的一個弔詭現象: 寫程式碼從來沒這麼快過,但真正上線、被用戶用到的軟體並沒有等比例地增加。瓶頸已經不是寫程式,而是 Code Review 跟不上了。
小編挑了五篇 2026 年的必讀文章一起整理,每篇代表一種不同的路線:
- Fayssal El Mofatiche — Ticketing Is Dead. Review Might Be the New Planning: 計畫儀式在瓦解,review 變成真正的工程工作
- Ankit Jain — How to Kill the Code Review: 直接把 code review 幹掉,人類往上游看規格
- Noah Hein — What Comes After the Pull Request: 產業三種賭注的全景整理
- Simon Willison — The AI-driven software factory: 介紹 StrongDM「完全不讓人類碰程式碼」的極端做法
- Boris Tane — The Software Development Lifecycle Is Dead: 拉遠看,不只 code review,整個 SDLC 都在崩解
再補上一些社群實戰數據,把 AI 時代 code review 的轉變講清楚。
先看數據: 新瓶頸在哪裡
Faros AI 分析了一萬多位工程師、1200 多個團隊的活動。高 AI 採用率的團隊:
- 完成任務量多 21%
- 合併的 PR 數多 98%
- 但每天 review 程式碼的時間也多了 91%
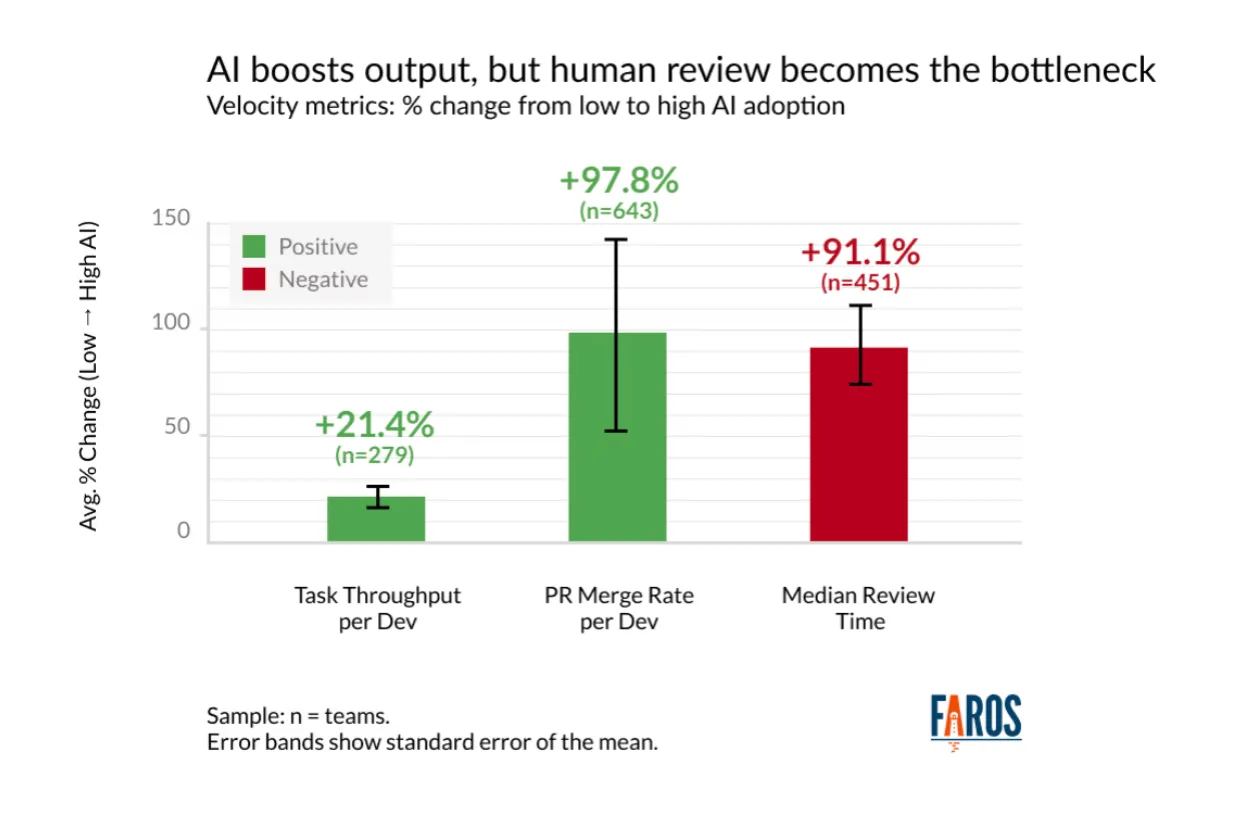 圖片來源: Faros AI, 引用自 Ankit Jain 在 Latent Space 的文章
圖片來源: Faros AI, 引用自 Ankit Jain 在 Latent Space 的文章
Noah Hein 引用 Cognition 改寫邱吉爾的一句話蠻經典的: 「在軟體工程的歷史上,從來沒有這麼多人寫出這麼多程式碼,卻只交付給這麼少人。」 寫了一堆,真正上線給用戶用的反而沒有對應變多。
換句話說, agent 寫程式碼的速度暴衝,但審查、理解、驗證、建立信任這些下游環節整個跟不上。Pull Request 以前是品質把關點,現在變成塞車點。
觀點一: 計畫儀式在瓦解, review 變成真正的工程工作
Fayssal El Mofatiche 的 Ticketing Is Dead. Review Might Be the New Planning 論點蠻犀利的。
他認為 story points、sprint 會議、backlog 整理這些傳統專案管理儀式,本質上都是「風險管理儀式」— 在「實作成本很貴」的年代才有意義。現在 agent 幾分鐘就能把東西寫完,整個協調層正在壓縮到接近零。
取而代之浮上來的是:
- 審查、評估、架構判斷變成主要瓶頸
- 架構決策紀錄(ADR, Architectural Decision Records)變成新時代最重要的文件 — 跟一次性消耗的 ticket 不同,ADR 會持續累積,在實作、審查、下個功能都持續發揮價值
有個蠻反直覺的觀點: AI 其實是「強化」工程師角色,不是取代。因為過往「不算真正工程」的雜事全都被商品化掉了,留下來的是貨真價實的架構判斷 — 這類工作過去一直被低估,因為組織只在意產出量。
成敗關鍵在於: 團隊是把審查當成「主要的工程實踐」,還是讓它變成「幫 agent 蓋橡皮章」。
觀點二: 直接幹掉 code review
Ankit Jain 在 Latent Space 發的 How to Kill the Code Review 更激進。他認為 code review 在 agent 時代以前就已經在壞掉了:
- PR 常常放置 play 好幾天
- 橡皮章式批准
- 審查者自己有 sprint 工作,看到 500 行的改動根本只是掃過
他的替代方案是「規格驅動開發」(spec-driven development) — 人類審的是「規格」和「驗收標準」,不再盯實作細節。搭配一個五層信任框架:
- 多個 agent 產出不同解法互相競爭
- 確定性的護欄(測試、型別檢查)取代主觀判斷
- 人類寫的驗收準則定義成功
- 權限系統從架構上限制 agent 能碰的範圍
- 對抗式驗證 — 用另一隻 agent 挑戰實作
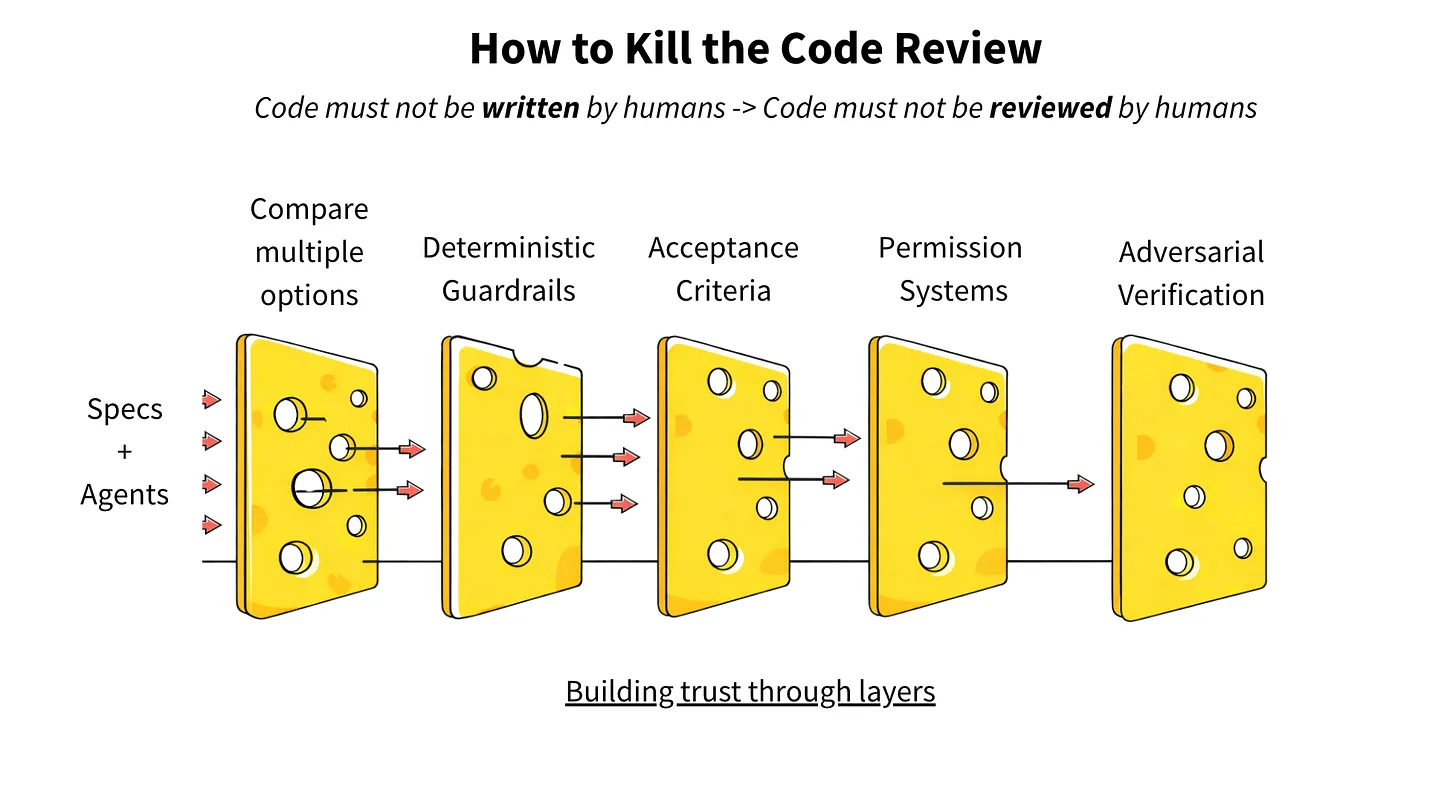 圖片來源: Ankit Jain, How to Kill the Code Review (Latent Space)
圖片來源: Ankit Jain, How to Kill the Code Review (Latent Space)
這張圖用瑞士起司模型來比喻 — 每一層都有漏洞,但五層疊起來能攔下大部分問題。邏輯跟資安界的「縱深防禦」很像。
核心轉變是: 人在迴圈中的角色從「你寫對了嗎?」變成「我們是在解對的問題嗎?」成功指標從下游的程式品質,往上游推到意圖本身。
小編覺得最有料的一點是他點出「審查本來就是劇場」— 只是 agent 時代讓大家沒辦法再假裝了。GitHub 在 2012-2014 年才讓 PR 變成主流,在那之前幾十年軟體業也是這樣交付的。
觀點三: Pull Request 的三種賭注
Noah Hein 的 What Comes After the Pull Request 把整個產業的不同路線整理得蠻清楚的。他觀察到各家公司對「PR 之後是什麼」有三種賭注:
賭注一: 讓審查變成 AI 原生
Cognition 推出的 Devin Review 是代表。他們點出一個觀察蠻準的,叫「Lazy LGTM 問題」— 小 PR 大家還能認真看,大 PR 的審查效率會急速下降,審查者往往就直接蓋章。GitHub 的 PR 流程從 15 年前定下來後其實沒什麼變化,但 AI 把大 PR 變成常態。
Devin Review 的做法:
- 智慧分組差異(把邏輯相關的改動排在一起)
- 偵測檔案複製/搬移(檔案重命名不會被當成整份刪掉重寫)
- 在審查過程中直接用對話問影響範圍
- AI 自動找 bug,把可疑處分紅、黃、灰三級標記
更進一步是 Cognition 後來寫的 Closing the Agent Loop — Devin 可以自動接收 linter、CI、安全掃描器、審查 agent 留下的 PR 留言並直接修掉,機械式的修正不再需要人類介入。這讓 Noah Hein 講的「agent 寫 → 審查 agent 驗 → 回饋修」閉環真的可以閉起來,人類只在需要架構判斷時才介入。
賭注是: 人類留在迴圈裡,但 code review 必須進化成 AI 原生。
賭注二: 把審查幹掉
就是前面 Ankit Jain 那套 — 把人類檢查點往上游搬到規格。
賭注三: 連平台都換掉
OpenAI 正在做 GitHub 的競品,同時開源了 Symphony — 一個 agent 導向的協調層,工程師只管意圖,agent 處理中間的執行。
Symphony 現在已經有 15k+ stars,定位是「engineering preview」(工程預覽),設計核心是從「盯著 agent 寫 code」變成「管理工作項目本身」。具體運作流程是:
- 持續輪詢 Linear 之類的議題追蹤工具,看哪些 issue 可以接
- 為每個 issue 建立隔離的 workspace,自動派 agent 去做
- 產出可驗證的「工作證據」: CI 狀態、PR 審查回饋、複雜度分析,甚至走查影片(walkthrough video)
- 全部協調策略寫在版本控管的
WORKFLOW.md裡 — 包含並行數、workspace 位置、agent 設定等
OpenAI 給了兩種採用方式: 跟著 SPEC.md 自己實作一套(任何語言都行),或直接用他們官方的 Elixir 參考實作。用 Elixir 這個選擇蠻有意思的 — Elixir 的 BEAM 虛擬機天生擅長處理大量並行、長時間運行的程序,剛好符合「同時管幾十個 agent workspace」的需求。
社群已經開始長出其他語言實作,像是 symphony-go — 用 Go 重寫、跑 Claude Code agent、還附 Kanban 儀表板。看得出來 OpenAI 的策略不是把 Symphony 做成一個產品,而是定義一套規格讓生態自己長出來。
這個賭注最大 — 他們認為瓶頸不只是 code review 這一層,整個平台當初是為「人類寫程式」設計的,需要從底層重做,把 agent 當成一等公民。
Noah Hein 最精彩的觀點是: 這三種賭注都可能只是暫時的鷹架(scaffolding)。他引用 Noam Brown 的例子: 在推理模型(reasoning model)出來前,大家拿弱模型搭一堆思維鏈、多次呼叫串接,結果新模型一出場全都不需要,甚至反而變成累贅。AI 領域不斷上演「鷹架被吃掉」的故事。
所以弔詭的是: 現在最有影響力能做的事情,幾乎一定是暫時的。但你還是得做,因為:
- 不能等下一代模型來解決今天的瓶頸
- 搭鷹架的過程本身就是在學「審查在 agent 時代應該長什麼樣」
- 鷹架可以丟棄,學到的東西丟不掉
小編覺得這段蠻有啟發: 新時代的工程師技能不是「搭精美系統」,而是「有意識地搭可丟棄的系統」— 知道什麼時候該把它拔掉,因為模型已經追上了。
觀點四: 極端路線 — 人類既不寫程式, 也不 review
Simon Willison 寫了 StrongDM 的 software factory,介紹 StrongDM 採用 Dan Shapiro 所謂「黑燈工廠」(Dark Factory) 等級的 AI 工程模式。他們訂了幾條看起來很極端的規則:
- 程式碼不可以由人類寫
- 程式碼不可以由人類審查
- 每位工程師每天的 token 消耗要超過 1000 美金
他們主要用「情境測試」(scenario testing)取代傳統審查 — 把端到端的用戶故事放在儲存庫之外當測試保留集,驗證看的是「多少比例的測試軌跡可能符合用戶需求」,本質是機率性的品質指標。
最強大的是他們打造了一套「數位孿生宇宙」(Digital Twin Universe): 把 Okta、Jira、Slack、Google 等第三方服務做成行為複製的執行檔,可以用比生產環境更大的規模跑測試、模擬危險的失敗情境、每小時跑幾千個場景,不會被頻率限制,也沒有真實成本。他們還開源了 Attractor(只放規格的儲存庫)跟 CXDB(用 Rust 寫的 16000 多行對話歷史資料庫)。
這個做法看起來很科幻,Simon 也點出兩個關鍵問題:
- 程式碼和測試都來自 AI agent,要怎麼證明系統本身的正確性?
- 每位工程師每月 2 萬美金的 token 成本,小團隊根本燒不起
這不會是主流做法,但值得看 — 它把「如果徹底把人拿出程式碼這個環節」會長什麼樣子展示出來了。
觀點五: 拉遠看 — 不只 code review, 整個 SDLC 都在崩解
前面四篇都聚焦在 code review 這一環,Boris Tane 寫的 The Software Development Lifecycle Is Dead 把鏡頭拉得更遠 — 他主張 code review 只是冰山一角,整個傳統 SDLC(軟體開發生命週期)都在崩解。
傳統 SDLC 的順序: 需求 → 設計 → 實作 → 測試 → 審查 → 部署 → 監控。這套流程是「實作很慢很貴」年代的產物,每個階段之間都有交接、審批、文件。但當 agent 幾分鐘就能完成一個功能,這些階段之間的縫早就被壓掉了。
Boris 點出一個蠻有意思的觀察: 「Cursor 之後才入行的工程師根本不知道什麼是 DevOps、什麼是 SRE。」 這群 AI-native 工程師直接跳過所有傳統儀式 — 沒有 sprint 計畫、沒有 story point、沒有 PR 流程。從「意圖」直接走到「迭代」再到「上線」。
他逐個拆解每個階段怎麼變:
- 需求: 不再是事先凍結的 PRD,變成跟 agent 邊做邊改。Jira 之類的工具角色從專案管理退化成「上下文儲存區」。
- 系統設計: 從「先設計再實作」變成「做的過程中浮現」。Agent 提出的架構常常還比人想的更好。
- 實作: agent 直接產出含錯誤處理、邊界情況、型別的完整解法。人類角色變成「掌舵」。
- 測試: 「TDD 不再是一種方法論,它就是 agent 預設的工作方式」這句蠻精闢,獨立的 QA 階段直接消失。
- Code Review: 跟前四篇方向一致 — PR 是過時產物,由 agent 自我驗證、對抗式驗證,例外情況才叫人類進來。
- 部署: feature flag 加漸進式發布天然契合 agent 流程,不再需要人類審批的 gate。
- 監控: 唯一倖存下來的階段,但定位完全變了 — 不是給人看的儀表板,而是要直接餵回 agent 的反饋迴圈。
最戳的一句話是: 「監控如果不會觸發行動,就只是昂貴的儲存空間。」 意思是: 公司花一堆錢收 log、metrics、trace,最後堆在 Datadog 或 Grafana 裡等人類去看,但真正觸發修復動作的訊號其實很少 — 大部分資料只是躺在那裡產生帳單。Boris 認為在 agent 時代這套邏輯要翻過來: observability 不該是配給人看的儀表板,而是 agent 能直接消費的反饋迴圈 — 出狀況時 agent 看到、判斷、自動修復或回滾,不必經過人類點頭。
他重新畫的開發迴圈只剩一條: 意圖 → Agent → 建構/測試/部署 → 觀察 → 重複。沒有 ticket、沒有 sprint、沒有審批佇列。
那人類的核心技能還剩什麼? Boris 的答案是「context engineering」(上下文工程) — 給 agent 的資訊品質直接決定產出品質,其他工程儀式大多會被吃掉。
小編覺得這個視角跟前四篇蠻互補: Ankit Jain 打掉 code review、Fayssal 打掉 planning 儀式、Noah Hein 在問下一步是什麼 — Boris 直接告訴你「整條生產線都要重新設計」。如果只盯著 code review 這一段,可能會錯失更大的轉變。
社群的實戰觀察
光看這四篇可能會覺得「未來很美好」,但看一下 2026 年初的社群實測數據,事情沒那麼順:
📊 審查排隊時間拖長: LinearB 2026 Benchmark 分析了 810 萬個 PR,AI 寫的程式碼要等 4.6 倍時間才會被接手進入審查,被接受不修改的比例只有 32.7% (人類寫的是 84.4%)。審查速度雖然變快 2 倍,但排隊時間拖長,整體沒優勢。
⚠️ GitHub 快被塞爆: 根據 Maksim Danilchenko 的分析,到 2026 年 3 月,GitHub 每月收到 1700 萬個 AI agent 發的 PR (2025 年 9 月才 400 萬)。4 月前兩天連續出五次故障。Voiceflow 的 Xavier Portilla Edo 說得直接: 「AI 發的 PR 只有十分之一是合格的」— 90% 是雜訊。開源專案維護者快被淹死,審查佇列變成一個對新人極不友善的戰場。
🔐 安全問題也被放大: Ahmed Ibrahim 整理的一份大規模研究顯示 45% 的 AI 生成程式碼樣本帶入 OWASP Top 10 漏洞。66% 的開發者表示對「差一點就對」的 AI 程式碼感到挫折。
🤖 Anthropic 自己也推出 Claude Code Review (2026 年 3 月上線): 五個專門 agent 平行跑,各看 bug、安全、合規、git 脈絡、留言驗證。有意思的是它永遠不會自動批准 PR,最終合併決定一定是人做。Anthropic 自己導入後,收到有意義審查留言的 PR 從 16% 跳到 54%,每次審查成本約 15-25 美金。
📈 不過 agent 自己也在變好: Cognition 發表的 Devin 2025 年度回顧 指出,Devin 產的 PR 合併率在一年內從 34% 爬到 67%,問題解決速度快 4 倍。典型場景是 4-8 小時、需求明確、結果可驗證的工作 — 像某家銀行做 Java 版本遷移從 30-40 小時壓縮到 3-4 小時、安全漏洞修復從人均 30 分鐘變成 1.5 分鐘。Cognition 也是「工程師只有 20% 時間在寫程式碼」這個流傳蠻廣的數字的原始出處。
編按: Siddhant Khare 有篇文章用「反壓」(backpressure)概念描述這個狀況蠻到位 — AI 是快速的產出者,人類是慢速的消化者,中間沒有緩衝機制,所以審查者成為品質把關的疲勞點。這個視角跟前面四篇文章蠻互補的。
小編的整理
綜合這四篇加社群實測,可以帶走三個判斷:
1. 瓶頸已經從「寫程式碼」移到「Code Review」。這件事 2026 年已經是共識,不是未來預測。光靠現有的 PR 流程硬撐不會有好結果 — 數據已經說話了。
2. 人類的價值往上游移動。不管是 ADR、規格、驗收標準、情境測試,共同方向都是: 人定義「什麼是對的」,agent 執行、系統驗證「是否達成」。程式碼本身從「主要審查對象」變成「被生成的產物」。這跟軟體業不斷抬升抽象層的歷史完全一致 — 就像編譯器出現時程式設計師被迫改變工作方式一樣。
3. 今天建的東西大多是暫時的, 但還是得建。Devin Review、規格驅動框架、AI 原生平台都可能被下一代模型吃掉,但你不搭就永遠不會知道「agent 世界裡審查應該長什麼樣」。新時代的工程師技能,是把可丟棄系統建得好。
但別誤會 — 人類 Code Review 還沒被拿掉
讀完這四篇可能會有一個錯覺: 業界好像準備要把人類從 Code Review 全部抽掉了。其實沒有。小編覺得現在更準確的描述是: 大家都在重新定位人類 Code Review 的位置,但還沒有共識,也沒人真的敢完全拿掉。
幾個觀察可以佐證:
- 三種賭注互相矛盾: AI 原生審查(Cognition)、規格驅動(Ankit Jain)、換平台(OpenAI) — 連方向都不一樣。大廠都還在試水溫,不是在收斂到某個答案。
- 主流工具的共識是「絕不自動批准」: Anthropic 的 Claude Code Review 明確設計成永遠不會自動 approve PR,Cognition 的 Devin Review 也是把結果丟給人看。兩大廠都選擇保留人類這道 gate,不是偶然。
- StrongDM 的極端做法還是小眾: 「完全不讓人類寫也不讓人類審」這條路線目前只有少數公司跑得起來,每位工程師每月 2 萬美金的 token 成本,多數團隊燒不起,也還沒證明長期能維持品質。
- 實測數據也沒漂亮: LinearB 2026 Benchmark 顯示 AI 程式碼的接受率只有 32.7%、排隊時間拖 4.6 倍;GitHub 塞爆到要考慮 kill switch。這些都是「人類還是得接手」的訊號。
所以目前比較靠譜的心法是: 不要盲目追求「移除人類 Code Review」,而是重新設計它。
怎麼設計? 可以照前面幾篇的方向試:
- 把人類的注意力從「diff 的每一行」挪到「規格、驗收標準、架構判斷」
- 讓 AI 處理機械性的檢查(linter、格式、明顯 bug),人類專注在判斷題
- 小 PR 讓 AI 自動跑完閉環、大 PR 或高風險變更保留人類看
- 用 ADR 把重要決策沉澱下來,不是每個 PR 重新討論一次
至於 StrongDM 那種「完全不讓人類碰程式碼」的極端做法,短期內不太會是主流,但它逼人去想一個關鍵問題: 當程式碼完全是 agent 的產物時,我們到底在審什麼?
Noah Hein 的觀察戳中這個問題的核心: 目前規格驅動開發的死結在於「一旦規格精確到機器可以執行的程度,它自己就變成一種程式語言」。Kevlin Henney 早說過「把程式精確描述出來這件事本身,就是程式設計」。換句話說,人類意圖和機器執行之間的抽象層,還在等一個「編譯器」出現。
其實這個觀察一點都不新。CommitStrip 在 2016 年就畫過一則迷因漫畫 A very comprehensive and precise spec,剛好戳中同一個點:

十年前的笑話,在 AI 時代變成必須認真面對的工程問題。接下來幾年最值得投入的方向,大概就是這件事。
延伸閱讀清單
五篇本文主要參考:
- Fayssal El Mofatiche, Ticketing Is Dead. Review Might Be the New Planning (2026/3)
- Ankit Jain, How to Kill the Code Review (Latent Space, 2026/3)
- Noah Hein, What Comes After the Pull Request (2026/3)
- Simon Willison, The AI-driven software factory (2026/2)
- Boris Tane, The Software Development Lifecycle Is Dead
Cognition 關於 Devin Review 的三篇補充:
- Devin Review: AI to Stop Slop (2026/1)
- Closing the Agent Loop: Devin Autofixes Review Comments
- Devin Annual Performance Review 2025
社群觀察與實測數據:
- GitHub’s AI Agent Problem: 17 Million PRs, Five Outages, and a Kill Switch (Maksim Danilchenko, 2026/4)
- Software Engineering Benchmarks 2026: AI Code Review Gap (LinearB 資料來源, 2026/3)
- The AI Code Review Bottleneck Is Already Here (Ahmed Ibrahim, 2026/3)
- You’re tired because your AI has no feedback loop (Siddhant Khare, 2026/2)
- Claude Code Review: Multi-Agent PR Reviews That Actually Catch Bugs (2026/3)
- Code Review is the New Bottleneck For Engineering Teams (2026/4)
- Rethinking Code Review for the AI Era (2026/1)