Replit 如何規模化評測和持續改進 Vibe coding

Replit 的總裁兼 AI 負責人 Michele Catasta 在 Anthropic「Code with Claude」場子的這場演講 Evaluating and improving Replit Agent at scale,小編覺得是少數真的把「規模化做 eval」講到骨子裡的一場。Replit 每天對著數百萬使用者出貨好幾個版本的 agent,模型又一直在變,他們到底怎麼確定 agent 真的有變好、而不是憑感覺?這場演講把整套體系攤開來講,還順手在台上 open source 了一個新的 vibe coding benchmark。
🎬 影片: Evaluating and improving Replit Agent at scale
以下是重點整理:
1. Replit 面對的是 vibe coding 最極端的那一版
Catasta 一開場就先界定問題的特殊性。vibe coding 這個詞涵蓋範圍很廣,一端是給軟體工程師用的工具,但 Replit 的場景是最極端的那一端: 使用者只給一句自然語言的需求描述,其他什麼都沒有。
他講得很白: 使用者期待「從一句 prompt 直接變成一個能跑的應用」,但他們不會告訴你要用什麼框架,不會寫測試,也不指定任何實作細節,就是預期 agent 跑完之後東西能動。這跟過去替軟體工程師打造 agent 的假設完全不一樣,所以「過去做 eval 的方式,跟過去建 agent 的方式,都必須從根本上改變」。
這點是整場演講的地基。Replit 的使用者大多是完全沒寫過程式碼的知識工作者(knowledge worker),這直接決定了他們的 eval 不能只看「程式碼有沒有改對」,而要看「做出來的 app 有沒有照使用者要的去動」。
2. 為什麼這件事特別難: 腳下的地一直在動
Catasta 用「shifting grounds」(腳下的地一直在動) 來形容他們的處境,小編覺得這個比喻蠻到位的。
模型一直在變,而且演進速度比一年前更快。模型一變,他們的 system prompt、user prompt 就得跟著改;為了配合產品新功能,prompt 也要常常調整;工具定義也一直在動,他們不斷新增、簡化工具。然後最關鍵的是出貨頻率: Replit 每天都有好幾次發布,而且是直接推到數百萬使用者面前。
在這種一切都在流動的狀態下,要怎麼確定 agent 每天都在進步、而且真的對齊使用者要的東西?這就是他們整套 eval 體系要回答的問題。
3. 核心主張: eval 不該是一個分數,而該是一條串流

這張投影片是整場的核心論點。左邊是「舊工作」: 你跑一次 eval,產出一個分數,然後由人類來看這個分數,決定「我的 agent harness 比之前好還是退步了」「該不該多做點 post-training」。整個流程在「人類做決定」這一步就停了。
Catasta 主張要往右邊那種「持續性」的設定走: eval 不是給人類消費的一個分數 (a score humans consume),而是一個系統運行所依賴的串流 (a stream a system runs on)。當你有東西真的跑在線上、而且每天產生數百萬條 trace 的時候,這些 trace 本身就藏著大量可以挖掘的超額價值(alpha)。
所以他們做的是 offline eval (類似 SWE-bench 那種 benchmark) 加上 online eval (基於真實系統使用) 的組合。他對 eval 的要求很明確: 第一要優化使用者真正在乎的東西,而不是只告訴你 agent 有沒有把程式碼改對;第二要能立刻指出什麼壞掉了,這會直接告訴團隊下一步該出貨什麼改進。
4. 兩根支柱: 出貨前的守門關卡,出貨後的持續挖掘
那個「黑盒子」裡面到底裝了什麼?Replit 的系統有兩根支柱。
一根是老派的 benchmark,通常在出貨新版 agent 之前跑,把它當成一個是非開關、一道發布前的關卡。如果 offline benchmark 出現重大退步,就停止發布;沒變化或變好,就放行。
另一根是他覺得更有意思、也是真正讓他們持續進步的部分: 大量的 A/B testing,加上把線上所有的 trace 拿來分群、從中萃取洞見。這根 online 支柱是在你出貨之後才開始運作,逼著你盡可能快地反應。
兩根支柱到位之後就形成一個迴圈: 看兩邊給你的結果、據此改程式碼、再跑 eval,洗了又重來。Catasta 說這就是他們在 Replit 每一天都在跑的循環。
5. 為什麼 SWE-bench 不夠用: 缺了「功能正確性」那一段

Catasta 特別花時間解釋為什麼要做比 SWE-bench 更貼近自己場景的東西。像 SWE-bench、HumanEval 這類 benchmark 在這個領域當然很關鍵,逼著大家把模型做得更強。但它們本質上都遵循同一套協定: 確認生成的程式碼符合 prompt、把 patch 套到 repository 上、跑測試,測試過了分數就高。
問題是這完全不反映 vibe coding 的真實狀況。使用者不寫測試,常常是從一個完全空白的 code base 開始。根本不存在「套 patch」這種情境,因為你是從零開始把東西蓋起來的。
所以真正要捕捉的是: 這個 app 有沒有做到使用者要求的事?投影片上他把這叫做「functional correctness gap」(功能正確性的落差),並下了一句蠻精準的判斷: 功能正確性才是「沒有人在量測的那個訊號」(the signal nobody was measuring)。
6. 台上發表 ViBench: 一個端到端的 vibe coding 公開 benchmark
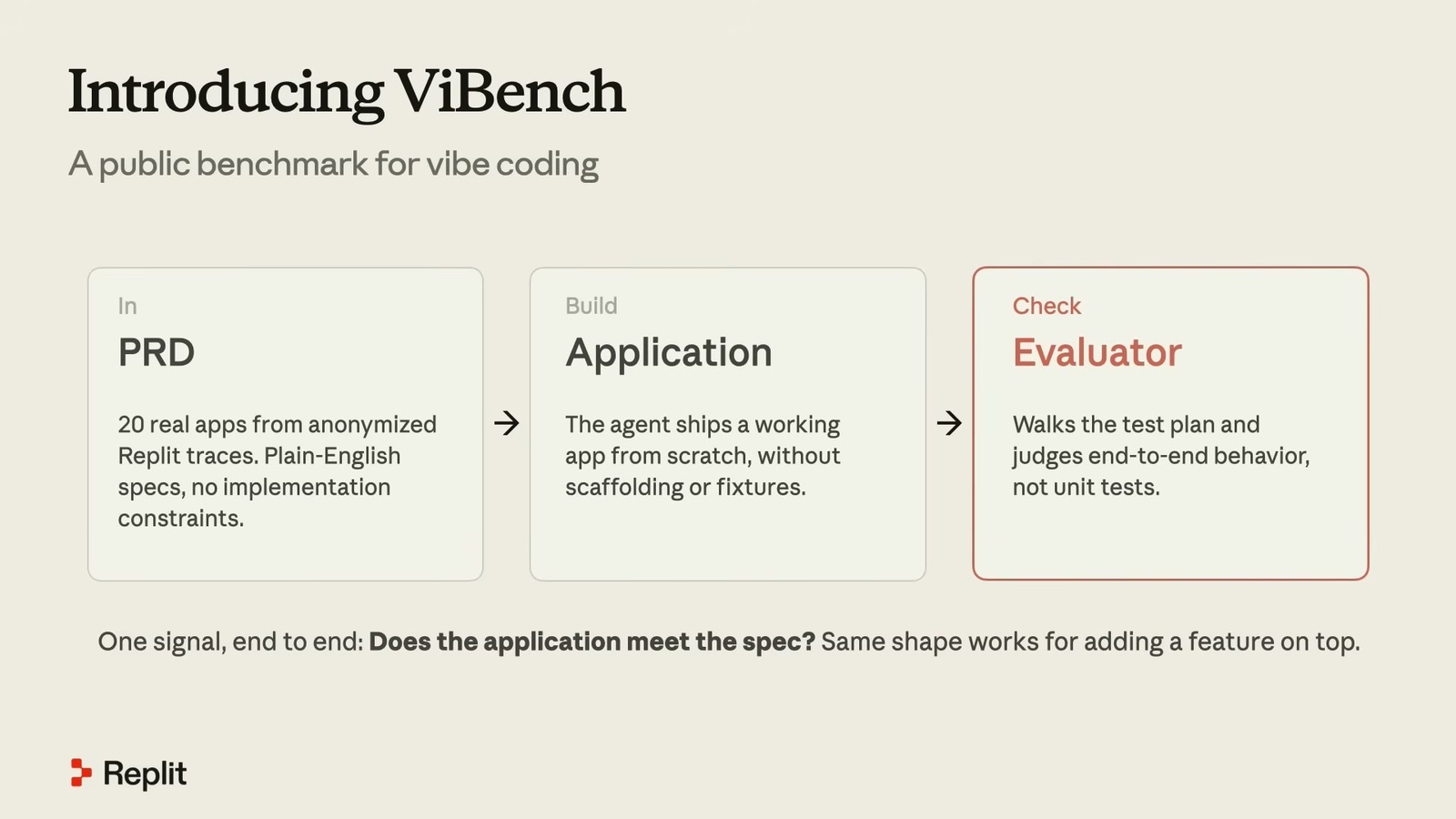
為了補上這個落差,Catasta 直接在台上開源了 ViBench,一個端到端、針對 vibe coding 的公開 benchmark,他們做了好幾個月,網址在 vibench.ai。
設定很有意思。輸入就是一份 PRD(產品需求文件),本質上是一段很長、描述怎麼蓋一個 app 的 prompt。他們不是用合成資料硬編出來的,而是從 Replit 的真實使用 trace 裡挑了 20 個案例,都是純英文的需求描述,沒有任何實作上的限制。然後有一個 harness 把 app 從空 repo 端到端蓋成可以動的東西。
關鍵的 insight 在最後一步: 與其在這裡停下來、找人類來評估這些 PRD 的產出,他們做了自動化的 evaluator。這就是讓 benchmark 從「大概一週跑一次」變成「每次都能跑」的關鍵——你 repository 裡只要有新的 PR merge 進來,就能跑一次。當然,跑所有 evaluation 的也是 AI。
7. 一個核心、一份開放的情境型錄: 從 zero-to-one 到 slop-on-slop

ViBench 的架構是「一個寫死的核心 + 兩個開放的槽」。寫死的核心是那個 behavioral eval (行為評估);前面兩個槽——輸入 (input) 跟策略 (strategy)——可以接任何東西。他們命名了五種配對,但你自己還能想出更多。
由淺到深大概是這樣:
- Zero-to-One: 輸入是 PRD,一次到位從零蓋到一。
- Vibe-on-Ref: 從一個已經能動的 reference 實作開始,在上面加功能。
- Vibe-on-Vibe: 從 agent 自己蓋的 MVP 開始,再疊一個新功能上去。Catasta 說這個用 X 上的黑話講就是「slop-on-slop」——agent 蓋了一個沒驗證過的東西,然後又在上面疊更多 agent 寫的程式碼,再跑評估看它還能不能動。
- Parallel + Merge: 對應他們幾個月前發布的 Agent 4,把任務分解、平行跑多個 agent、再把所有 patch 合併的複雜度都藏起來。這個「平行加合併」的情境對一般 coding agent 來說挑戰大得多。
- Decomposition: 輸入一份超大的 PRD,讓 agent 自己規劃跟拆解。
他還補了個更狠的玩法: 從一個有 bug 的 app 開始,在上面加功能,看 agent 要多掙扎才能讓它正確運作。型錄是開放的,社群可以一直往裡面加更難的情境。
8. 真正的難關在「怎麼打分」: 一個完全與實作無關的 evaluator
評分 (grading) 才是他們花最多力氣的地方,也是 ViBench 最硬的部分。
難在哪?因為在 vibe coding 裡,Replit 完全不給使用者任何框限(guardrail),他們愛用什麼語言、什麼框架都可以。所以 evaluator 必須對「實作長什麼樣子」完全不可知 (agnostic)。
他們的做法是: evaluator agent 先讀過整個程式碼庫,然後開一個瀏覽器、指向 agent 蓋好的那個應用,接著一步一步照著測試計畫走。連測試計畫本身都是用自然語言寫的,動作像是「打開後台儀表板、用某個帳號登入、點某個開關」。任何一步失敗,就把它們全部彙整起來,生成一個分數。
Catasta 把這個跟 SWE-bench 對照: SWE-bench 永遠是固定的場地,你知道 repository、知道 test harness、知道怎麼讓它跑起來。但 ViBench 的場地是完全的 greenfield (全新空地),這就是為什麼他們花了好幾個月才做出來。
9. ViBench 的兩個發現: 前沿模型領先 2 倍,改自己的程式碼最爛
論文會在幾週後的研討會上發表 (專案主導人也是論文一作 Peter 就坐在台下),但 Catasta 先劇透了兩個最值得注意的結果。
第一,前沿模型跟開源模型之間有將近 2 倍的差距。他特別點出這點,是希望整個社群——不管開放權重(open weight)還是封閉權重——都來採用這個 benchmark,因為每個模型廠商都在爬特定的 benchmark,他希望大家一起在 vibe coding 上整體進步。他甚至開玩笑說,把 benchmark 開源,社群可以一直把它弄得更難,「讓 Anthropic 的日子更難過一點」。
後段對談裡 Hannah 直接問了大家最好奇的問題: 為什麼不把這套 benchmark 當成自家的祕密武器、留著當護城河?Catasta 的回答蠻能看出他的價值觀——他出身研究圈,相信東西就該開放,而且「不相信在 eval 上互相競爭」。公開的 eval 能讓模型更好、agent 更好,最後是所有人的產品都更好。他還補了個有意思的轉折: 這個想法他過去在不少場合都試著對社群喊話、希望大家一起做,但喊久了發現沒人動手,最後只好自己先把它蓋出來。
第二個結果可能不太意外,但很重要: 大多數模型在「延伸自己寫的程式碼」時表現更差。也就是前面講的 slop-on-slop / vibe-on-vibe 情境,是目前為止最難的。
Catasta 從這裡帶出一個實戰建議,小編覺得這句對所有在 vibe coding 的人都很受用: 每次新增功能之間,一定要插一個測試的步驟。否則你就是不斷在搖晃的地基上往上蓋,最後你的 vibe coding 應用遲早會垮。
10. 第二根支柱 online eval: 數百萬條真實 session 的價值
光有 offline 還不夠。Catasta 強調他們同樣在乎 online eval,原因是兩者能收集到的訊號量級差太多。
offline 那邊大概就 20 個 app (他特別說之所以開源,就是歡迎社群貢獻更多 app、更多 prompt,把 benchmark 越弄越難)。但 Replit 這邊每天收集到數百萬條 session,而且這些 session 極有價值,因為它們捕捉的是使用者在平台上真正做的事,完全沒有腳本、agent 一直在跑。
問題就變成: 怎麼從這堆東西裡蒸餾出有用的資訊?
11. A/B testing 是讓自己保持誠實的方式

答案之一是大量的 A/B test。Catasta 說這是他們「讓自己保持誠實」的方式,因為 ViBench 只告訴你故事的一部分。他也直接喊話: 每一個在做 agent 的人,都應該盡早投資自己的 A/B testing 基礎建設,這是讓你穩定進步最好的方式。
他們在 agent 裡埋了大量的監測點(instrumentation)跟指標(metric),可以問各種問題: 有沒有異常的花費?agent 跑得比預期久嗎?他們也持續追蹤使用者情緒 (user sentiment)——這訊號很好收,因為每次收到 prompt 都能做情緒分析,看使用者是不是越來越挫折。還有一個很 Replit 特有的強訊號: 使用者可以把做好的 app 發布出去,如果他願意把成品分享給同事或公開放出來,那就是很強的正面訊號。
但 Catasta 也很誠實地講了 A/B test 的殘酷真相: 結果幾乎不會是非綠即紅的乾淨答案。投影片上那個例子——agent 平均執行時間漲了 7%,但成本反而便宜 8%,同時正負面情緒都有波動。這時候該怎麼辦?這就是人類的品味跟產品哲學還是關鍵的地方。你幾乎永遠不會拿到一個水晶般清澈的 A/B test 結果。
12. 把不知道該找的問題給分群出來

為了生成 A/B test 的候選,他們把每天每夜收到的所有 trace 拿來分群。先找出哪些群集是捕捉 agent 正常行為的 (這種很多,因為大多數時候 Replit 是成功的),但總有一條長尾的問題會被浮現出來。
找到有問題的群集之後: 把所有摘要轉成 embedding、按類型分群,找出某個時間點上發生的各種失敗,再丟給 LLM 去精準分類到底發生什麼事。Catasta 強調,這件事不是靠 regex、掃日誌這類非常確定性的技術來做的,這正是差別所在——因為你能把語意上相近的東西分到一起,即使 agent 給你的輸出不見得每次都長一樣。
而且因為他們同時平行跑好幾個版本的 agent、每天出好幾個版本,所以不能用固定的分群設定,必須每天晚上重新訓練這些群集。
這裡有個很妙的好處: 重訓群集之後,可以回頭看某個群集在你以為修好問題之後是不是真的消失了。比方說有個工具失敗只在特定條件下、1% 的機率發生——這種根本不會出現在你的 Datadog 儀表板上,因為它不是那種 50% 都會發生的數字。但你 ship 了新 PR、那個群集消失了,你就開始有證據說自己緩解了這個問題。小編覺得這招對抓長尾 bug 特別實用。
13. Telescope: 一個幾乎全自動的改進迴圈

他們內部把這套技術叫 Telescope,是一個 (Catasta 希望聽完之後你會覺得) 相當簡單的迴圈:
先發現問題 (discover),基於前面講的 trace 分群。再據此產生程式碼改動 (create code changes)——這完全自動化,他們用 coding agent 直接根據從 trace、日誌、各種儀表板收集到的資訊去開 PR。然後評估這個改動: 先重跑 ViBench 看是不是破壞性改動,ViBench 在這裡像個試金石 (litmus test),分數掉超過 10 分就判定這個改動是壞的。如果是有爭議、可能對 agent 有負面影響的改動,就跑 A/B test 放到使用者面前看取捨;如果是明顯的好球就直接出貨到線上。少數情況下,如果假設正確但 PR 不夠完美,就繼續迭代、再跑一輪 A/B test,直到配置夠好才真正出貨。
Catasta 下了個蠻有意思的註腳: 如果你想想,這跟你身為 AI engineer 平常做的事很像,只是現在 90% 都由迴圈裡的 agent 代勞,你不用為每一個步驟去流汗。
投影片上那個真實案例蠻具體: Telescope 標記出一個小但在成長的群集——環境設定在一條冷啟動 (cold-start) 的長尾上悄悄退化。Replit 的 agent 在第一次送 prompt 時就會啟動執行環境,而要把這套複雜度都架起來需要好幾秒。有一次長尾上的設定時間比預期久,agent 在環境還沒準備好就先動了起來。
14. 那個 cold-start 案例: 為什麼非靠語意分群不可
這個案例 Catasta 講得很細,小編覺得很能說明 trace clustering 的價值。
現在的 agent 變得非常急著想修問題 (eager to fix)。所以 Replit 的 agent 就「跑偏了」(went on a tangent),當場開始試圖修環境。但因為 agent 本質上不是確定性的,每一次 debug 的 session 看起來都長得不太一樣。
結果就是: 如果你只靠撈日誌去找這個長尾問題,它幾乎不會浮現。但一旦你透過語意層把所有 trace 分群,就會發現這個問題其實發生得相當頻繁,於是馬上就能做出 patch 修掉。這個案例因為是純退步 (pure regression),所以不用跑 A/B test;如果是需要測試的問題,中間就會多插一個步驟。
15. 人類的品味還是最重要的地方
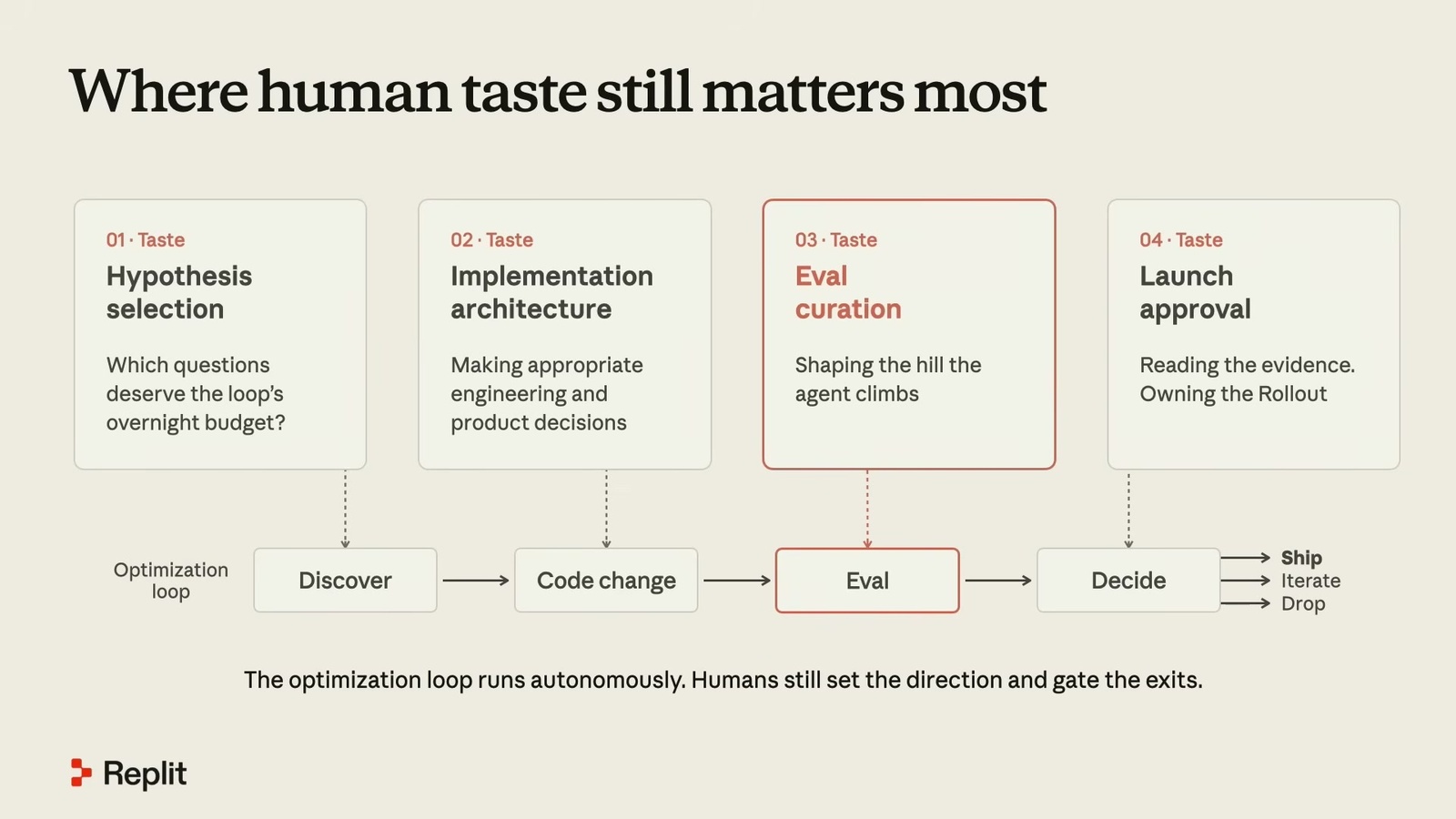
雖然 Catasta 是「盡量用 agent 優化 AI engineer 生活」的大力支持者,但他很明確地說,在他展示的這套迴圈裡,還是有大量需要人類做的智識工作。投影片上他把人類品味落在四個位置:
- 假設選擇 (hypothesis selection): 哪些問題值得花掉迴圈的「過夜預算」?因為跑在線上你會拿到超大量的修復候選,必須排優先序。每次找到一個群集,團隊都會先針對「這裡可能哪裡出錯」形成一個假設,假設夠有意思才往前走,而且不會放手讓 agent 在零監督下亂寫 PR。
- 實作架構 (implementation architecture): 做出恰當的工程跟產品決策。
- Eval 策展 (eval curation): 他用了一個很傳神的說法——你每次決定要做某個 PR、跑某個 A/B test,其實都是在「形塑 agent 要爬的那座山」(shaping the hill that we try to optimize)。如果你只在乎讓產品更便宜,就會去修所有異常花費的問題、拼命優化那一塊。這些選擇真的決定了你想放到使用者面前的產品哲學。
- 發布核可 (launch approval): A/B test 沒有清楚結果時,最後要不要發布還是人類的選擇。Catasta 說「通常那個人就是我」。
在後段跟 Anthropic Applied AI 團隊的 Hannah 對談時,他補充了一段關於「品味怎麼養成」的話蠻值得記: 一年半前剛推出時,agent 還沒這麼強,那時候沒什麼品味可言,比較像是生存遊戲、只求勉強能動。現在 agent 變強、選擇變多了,你才開始發展出品味,而這個品味必須跟你真實的使用者群對齊。Replit 裡每個人都很技術,但產品是給「從沒寫過一行程式碼」的知識工作者用的,所以 80% 的決策可能跟你替工程師做 agent 時是相反的——永遠要記得用的人很可能跟你很不一樣。
16. 一個額外的實戰提醒: 半年前做不起來,現在再試一次
對談裡 Hannah 問「想自己蓋類似 Telescope 系統的人,有什麼教訓可以分享」,Catasta 的回答小編覺得很實在。
第一句就是: 如果你半年前試過、因為投資報酬率不好而放棄,現在絕對值得再試一次。你在 coding agent 上經歷過的那個轉折點 (inflection point)——他特別點名是去年 11 月 Opus 4.5 那一波前沿模型——同樣反映在這件事上。長上下文加上真的能對大量內容做推理的模型,意味著你現在可以把整段 agent trace 灌進 Opus,拿到相當細緻的回饋。
與此同時,你應該認真投資「收集所有能收的訊號」——不只是 trace,還有產品內的回饋。Replit 有回饋表單,所以每次 agent 行為不對、使用者抱怨,他們就同時握有使用者的觀點、agent 的 trace、以及平台在 Datadog 裡所有的監測資料。把這些全部放進同一份上下文,就更能精準定位問題到底出在哪。
Catasta 也補了一個讓人比較安心的角度: 把 trace 分群這件事,其實讓 agent builder 的日子沒那麼難熬。當你開始有大量使用,收到的回饋多到讓人喘不過氣——這是好訊號,代表大家在乎你做的東西——但分群幫你排出「什麼真的重要、什麼動不了大局」的優先序。
寫在最後

整場演講最大的啟發,Catasta 自己用一句話收尾,小編直接翻過來: 別把 eval 只當成出貨前的最後一道檢查、一個是非開關,要把它想成「一具能讓你每天出貨更好 agent 的引擎」(an engine that allows you to ship a better agent every single day)。
把這場演講串起來看,會發現 Replit 其實是在回答一個很多人卡住的問題: 當模型、prompt、工具、產品功能全都在高速流動、而且你每天要面對數百萬使用者出貨時,傳統那種「跑個 benchmark 拿個分數」的 eval 根本撐不住。他們的答案是把 eval 拆成兩根支柱——出貨前當守門員的 offline benchmark (ViBench),加上出貨後靠 trace 分群持續挖掘的 online 系統 (Telescope)——再用一個幾乎全自動的迴圈把兩者接起來,讓「發現問題、改程式碼、驗證、出貨」變成一條每天都在轉的生產線。
而最反直覺、也最該記住的,反而是 Catasta 在全自動的故事裡一再強調的: 自動化跑得越多,人類的品味反而越關鍵。從假設要不要追、到 A/B 結果模稜兩可時要不要發布,這些「形塑那座山」的選擇,最終定義了你的產品。eval 自動化解放了人,但沒有取代判斷。