從 Token 串流到 Agent 事件串流:OpenAI、AG-UI、Vercel、LangChain 的格式設計比一比
LangChain 的 Christian Bromann 寫了一篇 From Token Streams to Agent Streams(從 token 流到 agent 流),講的是一件常被當成傳輸小事、其實是該好好設計的工程問題: 當你的產品從「一次模型呼叫」長成「一個會規劃、會分派子代理(subagent)、會呼叫工具、還會中途停下來等人核准」的 agent,你在前端收到的那串資料,格式整個都得重新設計。
他開頭那句話蠻精準的:「agent 串流已經超出 token 增量(token deltas)能承載的範圍。」小編就借這個命題,把幾家的設計做法整理在一起聊聊: 從最原始的 OpenAI 串流當基準,一路看到 AG-UI、Vercel AI SDK、LangChain 各自怎麼設計這串資料的格式,中間再穿插一些 ihower 實際做串流產品時累積的經驗。算是一篇參考各家設計、加上實戰心得的整理分享,看完你大概會同意:「能不能顯示 token」早就不是重點了。
先談基準: 從增量到語意事件
最原始的串流長這樣。OpenAI Chat Completions 的每個 chunk 是 choices[0].delta.content,裡頭塞一小段文字,前端要做的就是把這些片段一段段接起來。工具呼叫更麻煩: 它是 tool_calls[].function.arguments 的片段,用陣列位置(index)標記這是第幾個工具,你得自己照著位置把 JSON 碎片拼回完整的參數物件。這就是典型的「不透明 chunk」: 格式只關心「下一段資料是什麼」,語意全得靠你自己重建。
文字和工具參數都是裸片段,工具還得靠 index 自己對位拼回來,語意全靠前端重建。
OpenAI 後來的 Responses API 其實已經進步很多。它不再是沒有語意的增量,而是一串「語意事件」: response.output_item.added 告訴你新開了一個輸出項目(可能是訊息、工具呼叫、推理),response.output_text.delta 串文字,response.function_call_arguments.delta 串工具參數,推理(reasoning)有自己的事件,最後用 response.completed 收尾。整個輸出被組織成一個個輸出項目,每個項目內部用「開始 / 增量 / 結束」的節奏串。
事件名稱本身就帶語意,前端一看就知道現在在串哪個輸出項目,推理和最終答案也分開了。
這已經是相當像樣的設計: 有型別、知道自己在串什麼、推理和答案分開、連用量(usage)資訊都保得住。所以問題來了,既然基準都做到這樣了,為什麼還不夠用在應用層級?
基準暗藏的三個假設
關鍵在於 Responses API 這類設計,骨子裡假設了三件事,而 agent 應用把這三件事全打破了:
但複雜的 agent 會展開成一棵樹: 主 agent 分派三個子代理,每個又各自呼叫工具。一條線性的串流講不清「這段是誰產生的」。
把所有子代理的 token、工具、狀態壓成一條串流,等於逼前端下載每個子代理的每個 token,哪怕畫面上只開了其中一個。
會跑很久的 agent 一動就是十幾分鐘。瀏覽器一刷新就斷線,沒有排序和回放機制就只能重跑,或是內容重複。
Bromann 把應用層級真正該問的問題列得很到位,小編挑幾個最有感的: 能不能即時畫出一棵 agent 的工作樹? 能不能只訂閱畫面上那一個子代理,而不用付下載其他所有子代理的頻寬代價? 能不能把「等人核准」當成第一級的事件來處理? 能不能斷線後重新接上、接著上次的進度繼續,而不是整段重播?
這些問題,token 增量一個都答不了。因為它根本沒有「樹」(tree)「頻道」(channel)「斷點」(checkpoint)這些概念。
兩個維度: 頻道與命名空間
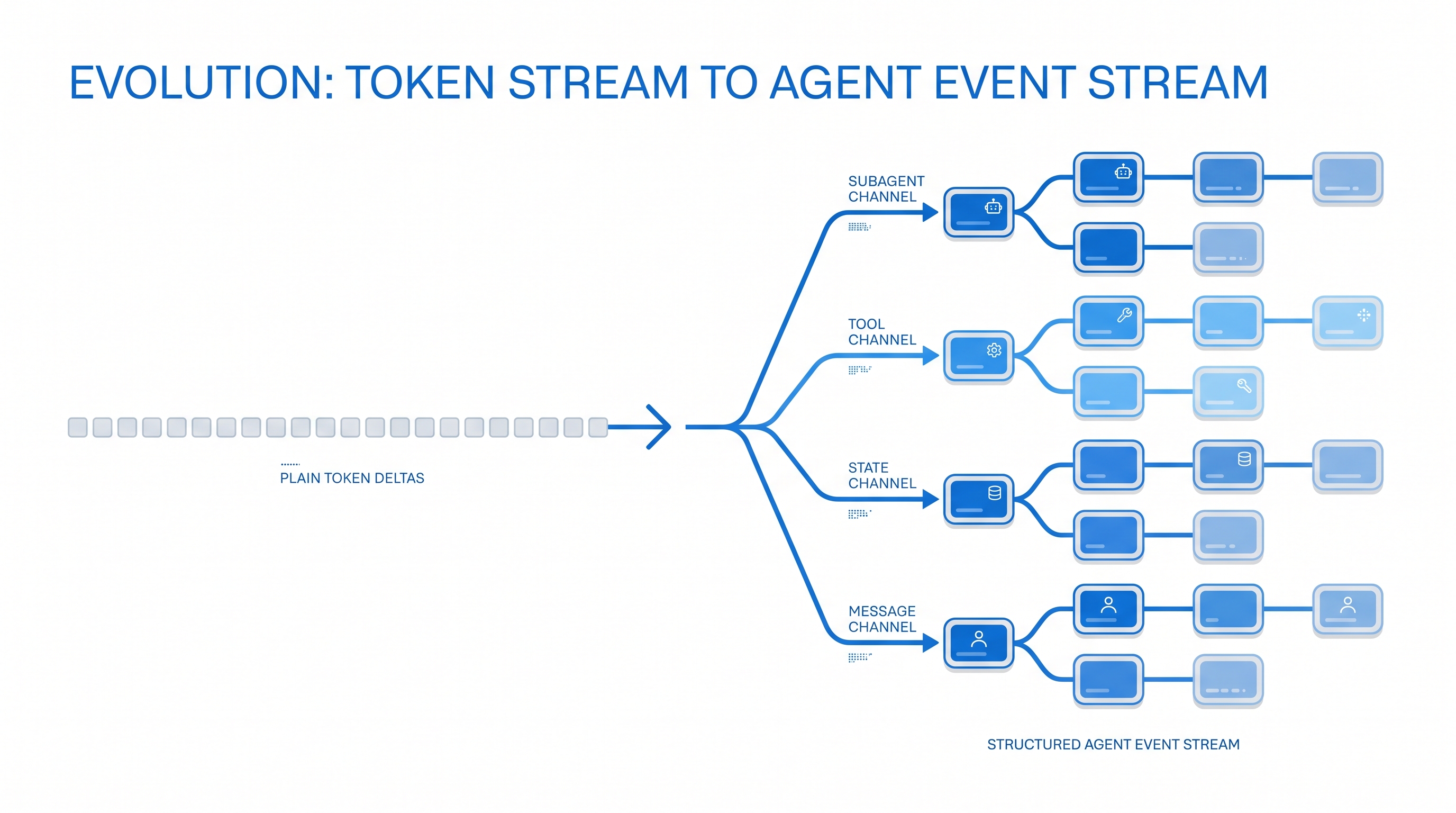
LangChain 這套新串流原語的核心設計,小編覺得最值得學的,是它把每一段資料拆成「兩個正交維度」來標記。
第一個維度是 頻道(channel): 標記這串資料「屬於哪一類關注點」,也就是你會想分開來看的不同面向。messages 是對話內容、values 和 updates 是流程圖共享的狀態(例如目前累積的搜尋結果、計畫清單、步數計數器這類資料: values 給你完整快照,updates 給你每一步改了哪些欄位)、tools 是工具執行的起訖、lifecycle 是整段執行和子代理的生死、custom:* 是應用自己定義的投影。
第二個維度是 命名空間(namespace): 描述這個事件「發生在 agent 樹的哪個位置」。根節點、巢狀的子流程圖、某個子代理,都可以發出同一種頻道的事件,但各自保有身分、不會混在一起。
用一張表最好懂。每段資料都落在某個「頻道 × 位置」的格子裡,而你可以只訂閱自己正在畫的那幾格:
「頻道是可重複使用的關注點、命名空間是產生它的位置」這個拆分,就是整套設計的關鍵選擇。有了它,一個子代理檢視器才能只打開它要的那一格,不會把每個子代理的 token 全拉下來。
多了 namespace 這個維度,同一種事件就能標出「是樹上哪個子代理發的」,這正是前面那些設計都沒有的。(實際 LangGraph 傳輸線上的欄位名稱略有不同,這裡是概念示意。)
投影: 不要解析,直接拿你要畫的東西
光有型別還不夠。Bromann 的第二個重點是 投影(projection)。先講清楚: 投影不是傳輸線上的某種格式,而是一個設計概念。它指的是執行層在那串底層事件「之上」,幫你組好幾種現成的視圖,讓你的程式碼直接拿來用,不必自己一條條去解析原始事件。
具體長什麼樣? 在 LangChain 的框架 SDK 裡,這個概念落地成一組 API: 你呼叫 useMessages() 就拿到一串已經組好的訊息、useToolCalls() 拿到工具呼叫的清單、useValues() 拿到目前的狀態。至於重組、重新排序、斷線重連這些髒活,執行層全幫你包掉。而且每則訊息本身是「一連串有型別的區塊」: 文字、推理、工具參數、用量,而不是一條要你自己切的字串。這點對現代模型輸出很重要,推理和最終答案本來就該分開呈現,工具參數要當成結構化資料來組裝,多媒體資料更不該被硬塞進純文字介面。
(瀏覽器 JS)
組裝 · 排序 · 重連
useMessages() → 聊天泡泡useToolCalls() → 工具指示器useValues() → 狀態面板這裡 ihower 補了一個很實務的提醒: 你不應該把上游 Responses API 或 Completions API 的串流原封不動轉傳給前端。模型 API 吐出來的東西,很多根本不該給使用者看,可能是內部推理、給除錯用的中繼資料、或牽涉權限不該外露的內容。前端要收的,是你「為這個產品設計過」的事件,而不是上游吐什麼就照單全收。換句話說,你前端那層格式,是一個你要主動設計的應用層介面,不是模型 API 的透傳管線。這也是投影這個概念為什麼這麼關鍵: 哪些事件、長什麼形狀、露給前端,都由你決定。
跨模型使用是另一個自己設計格式的硬道理。實務上你很可能今天用 OpenAI、明天換 Anthropic 或 Gemini,每一家原生的串流格式都長得不一樣。要是前端直接綁死某一家的格式,換一次模型前端就得跟著改一輪;但只要中間隔了一層你自己設計的事件格式,換模型時你只要改後端那段轉換,前端依賴的那份約定完全不用動。模型是會換的,你的格式不該跟著換。
編按: 這背後其實是一個「抽象反轉」的觀念,真正的事件來源是執行引擎(harness),token 串流和畫面更新都只是它的投影。所以換掉底層模型,換掉的只是投影,你前端依賴的那份語意約定不變。這也是為什麼這類協定都強調「按類別訂閱,而不是按單一事件名稱訂閱」: 訂「所有工具呼叫類的事件」,協定日後新增事件名稱你也不會壞;把每個事件名稱寫死進去就會壞。
AG-UI 怎麼設計的
講到標準化的事件協定,就不能不看 AG-UI(Agent-User Interaction Protocol,由 CopilotKit 發起)。它的定位跟 LangChain 那套有點不同: AG-UI 想當的是「agent 後端」和「前端」之間那條通用的線,和 MCP(管工具)、A2A(管 agent 之間的溝通)並列在 agent 協定的堆疊裡。
編按: 釐清一下 CopilotKit 和 AG-UI 的關係,免得搞混。CopilotKit 是一間公司、也是一套 React / Angular 的前端 SDK(現成的聊天元件、
useAgenthook、generative UI 那些);AG-UI 則是他們從跟 LangGraph、CrewAI 的合作中抽出來、再開源給整個生態的「協定」,後來被 Google、LangChain、AWS、微軟、Mastra、PydanticAI 等採用。一句話: AG-UI 是開放協定(規格),CopilotKit 是講這個協定的第一方前端框架。
它的設計小編覺得乾淨俐落。所有事件都繼承自同一個 BaseEvent(至少帶 type,另有可選的 timestamp、rawEvent),核心大約十多種,分成幾類:
- 生命週期:
RUN_STARTED、STEP_STARTED/STEP_FINISHED、RUN_FINISHED/RUN_ERROR,帶threadId、runId,還有可選的parentRunId給分支用 - 文字訊息:
TEXT_MESSAGE_START→ 多個TEXT_MESSAGE_CONTENT(各帶一段delta)→TEXT_MESSAGE_END,用messageId串起來 - 工具呼叫:
TOOL_CALL_START→ 多個TOOL_CALL_ARGS(串 JSON 片段)→TOOL_CALL_END→TOOL_CALL_RESULT,用toolCallId串 - 狀態管理:
STATE_SNAPSHOT(完整狀態)、STATE_DELTA(用 JSON Patch / RFC 6902 送增量)、MESSAGES_SNAPSHOT - 特殊事件:
RAW(包外部系統的事件)、CUSTOM(應用自訂)當逃生口
這裡有兩個小編覺得很值得抄的設計。一是 「開始 / 內容 / 結束」三段式,套用在所有串流內容上(文字、工具參數都是同一個節奏),前端只要實作一套組裝邏輯就好。二是 「快照 / 增量」模式 來同步狀態: 偶爾送一次完整快照當基準,中間用 JSON Patch 送小增量,兼顧完整和省頻寬。它還貼心地提供 TEXT_MESSAGE_CHUNK 這種便利事件,第一段自動展開成 start,串流切到下一個 id 時自動補上 end,省掉手動管理生命週期的麻煩。
傳輸層的選擇上 AG-UI 也刻意保持開放: SSE、WebSocket、webhook 甚至自家的二進位傳輸都能載,不綁死單一種(對照之下 Vercel 那套主要走 SSE)。再配上雙向溝通,使用者的中斷和確認可以回傳給 agent,所以「人在迴路」(human-in-the-loop)是它內建的概念(RUN_FINISHED 的結果可以是一個中斷,代表停下來等人)。
不過對照一下會發現一個有意思的差別: AG-UI 的核心比較像「單一 agent + 工具 + 狀態」的一條扁平串流,多 agent 樹的部分主要靠 RAW 和 CUSTOM 當擴充點。而 LangChain 那套多了命名空間這個維度,把 agent 樹的位置直接做進協定的第一層。兩種取捨沒有絕對好壞: 前者簡單通用、好接既有框架,後者為複雜的樹狀 agent 而生。
還有哪些值得參考的設計
小編另外撈了幾個業界的做法,會發現大家其實在往同一個方向走。
Vercel AI SDK 的 data stream 協定 跟 AG-UI 幾乎是同一個形狀,只是換了名字: 文字用 text-start / text-delta / text-end(每段內容有自己的 id),工具用 tool-input-start / tool-input-delta / tool-input-available / tool-output-available,推理也是「開始 / 增量 / 結束」。它有兩個設計小編覺得很實用: 一是 資料片段的就地更新,你送一個帶 id 的資料片段,之後用同一個 id 再送一次就會更新同一塊(很適合做進度條、載入狀態、協作中的文件);二是 暫時性片段,送給前端顯示、但不寫進訊息歷史(適合那種一閃即逝的通知)。它一樣走 SSE,主打連線保活、可重連、好快取。
這兩個設計用程式碼最好懂。上面那筆 data-weather 是 loading,之後用同一個 id 再送一次,前端就會就地把那塊換成新內容(很適合進度條、協作中的文件);而帶 transient:true 的片段只會即時顯示、不寫進訊息歷史(適合一閃即逝的通知):
編按: 這裡的
data-前綴和整套資料片段機制(id就地更新、transient不入歷史)是 Vercel AI SDK 協定定義的,但後面的weather、notification是你自己取的名字、可搭配型別做到型別安全,並非內建事件;對照之下text-start、tool-input-delta那些才是固定的內建事件名。
順帶分清楚: A2UI 是「格式」,AG-UI 是「傳輸」
既然講到 AG-UI,順手帶一個名字超像、又最容易跟它搞混的東西: A2UI。兩者其實是不同層的協定。
A2UI(Agent to UI)是 Google 提出的協定,要解決的問題是:「agent 要怎麼安全地把一個畫面送到前端?」尤其在多代理場景,有些 agent 跑在別人的伺服器上,你不可能讓它直接塞 HTML/JavaScript 進你的頁面(有安全風險,畫出來也跟你的 app 樣式不搭)。
A2UI 的做法是: agent 不送程式碼,而是送一串「宣告式的 JSON」描述畫面長怎樣,前端再用自己的原生元件(React、Flutter、SwiftUI 都行)把它畫出來。它的幾個設計重點:
- 送的是「資料」不是「程式碼」: agent 只能從前端提供的「元件目錄(catalog)」裡挑元件,沒有任意執行程式碼的風險,所以連跑在別人伺服器上的 agent 送來的 UI 都能安全地畫。
- 結構和資料分開: 一種訊息(
updateComponents)描述畫面結構、另一種(updateDataModel)灌資料,前端可以只更新某個欄位、不必重畫整個畫面。 - 扁平的元件清單 + ID 互相參照(adjacency list): 不用一次生出完美的巢狀 JSON,LLM 可以邊生邊串,收到 root 元件就先開始畫。
關鍵就在這個分工: A2UI 管「要畫什麼」(格式),AG-UI 管「事件怎麼在前後端之間流動」(傳輸)。兩者是互補的,A2UI 本身就標明自己不挑傳輸,可以走 AG-UI、A2A、SSE、WebSocket;反過來 AG-UI 也可以把一包 A2UI 內容當成某個事件的酬載載過去。實際上任何已經會講 AG-UI 的 agent,幾乎零成本就能驅動 A2UI。把這兩層分清楚,你才不會拿「要畫什麼」去跟「怎麼傳」硬比。
你可能會問: AG-UI 不是也有「generative UI」能嗎? 有,但差別在「誰決定畫面長怎樣」。AG-UI 的 UI 是「事件驅動、由你的 app 自己渲染」: agent 發出工具呼叫或自訂事件,你在前端自己決定哪個事件對應哪個元件,渲染邏輯寫在你(受信任的)app 程式碼裡,它本身沒有規定元件樹的標準格式。A2UI 則是把「UI 描述本身」標準化成一棵宣告式元件樹,一個通用 renderer 就能畫。所以前者載的是「你 app 會自己渲染的訊號」,後者載的是「通用 renderer 就能畫的 UI 描述」,這也是為什麼不受信任的遠端 agent 適合用 A2UI。
編按: CopilotKit 自己把 generative UI 分成三種模式,剛好把這個層次標得很清楚: Static(走 AG-UI,前端預先寫好元件、agent 用事件或狀態觸發)、Declarative(走 A2UI,agent 吐元件樹、通用 renderer 畫)、Open-Ended(MCP Apps / Open JSON,更自由)。重點是: AG-UI 是事件導向、本身不是宣告式 UI;同一個前端可以底層用 AG-UI 載事件,需要時再把 A2UI 當酬載塞進某個事件裡,兩者疊著用。
講完設計,小編插一段比較主觀的看法: 對 A2UI 這種「宣告式 UI」,小編其實蠻保留的。畫面長怎樣、怎麼排版、怎麼互動,本來就是前端最擅長、也最該掌握的事;讓 agent 去描述一棵 UI 元件樹,某種程度上就是在重新發明一套 HTML/CSS,多數情況下是 over-engineering。Hacker News 上的討論也有人吐同樣的槽:「看這些範例,感覺它最後會收斂回我們早就有的 HTML,那為什麼不乾脆讓各平台支援 HTML 就好? LLM 本來就很會生 HTML」、「『用 JSON 描述畫面、客戶端來畫』這套我們搞很多年了,難的從來不是線上格式,而是元件版本管理跟跨客戶端 debug」。
那 A2UI 真正有價值的情境是什麼? 小編認為其實就一個: 當前端不屬於你的時候。比方你要把 agent 上架到別人的平台、嵌進別人的 app,你沒辦法自己寫前端、也不能塞程式碼進去,只能用對方提供的元件目錄,這時候一套宣告式、跨平台、又安全(只能挑核可過的元件)的 UI 描述格式才划算。同一串討論裡也有人精準點出這點: A2UI 最有意思的就是「遠端訊息傳遞、你不擁有那個 UI」的場景。反過來說,如果前端是你自己的,老老實實寫前端就好,別繞這一圈。
編按: 這種「agent 吐一份 UI 描述、通用 renderer 來畫」的路子,A2UI 並不是唯一一家。Thesys 的 OpenUI(MIT 授權)走同一個方向,切入點不同: 它不送 JSON,而是設計了一套叫 OpenUI Lang 的精簡 DSL(每行一個
identifier = Expression),主打兩點,一是 token 更省(官方自宣稱比 JSON 少約 67%),二是 line-oriented,每收到一行就能立刻畫一塊,streaming 更順。
存下來的不是答案,是整段串流
ihower 還提了一個小編覺得超多人會踩到的坑: 串流型的應用不能只存最後那段最終答案的文字。
想想看,使用者關掉頁面、隔天再回來,你要讓他看到的應該是「完整的過程」: 中間呼叫了哪些工具、各個子代理做了什麼、推理怎麼一步步走、多媒體怎麼一塊塊長出來。如果你資料庫裡只存了最終答案,這些全沒了,回訪的使用者只看到一個乾巴巴的結果,和當時親眼看著它一步步生出來的體驗完全是兩回事。
所以你真正該存下來的,是「整段串流本身」: 當時串流長什麼樣,存下來就是什麼樣,回放的時候也放同一份。這正好解釋了為什麼前面那些協定都那麼在意型別事件、排序資訊和「快照 / 增量」,因為那串有序的事件本身,同時就是你的「儲存格式」和「回放格式」。格式設計得好不好,直接決定了你能不能把一段跑了十分鐘的 agent 執行完整存起來、之後一模一樣地放出來。
這跟斷線重連其實是同一個能力的兩面: 重連是「執行還在跑,我接回去」,回放是「執行早就結束,我重看一遍」,兩者吃的都是同一份有序的事件記錄。一個沒有設計好格式的串流應用,這兩件事都別想做。
「整段都存」會踩到的儲存效率問題
不過「整段都存」馬上會帶出另一個工程問題: 怎麼存才不會爆掉? LangGraph 團隊最近就在處理這件事。
問題出在它預設的存法: 每走一步,就把當下「完整的狀態」整包存一次。對話的訊息清單尤其慘,因為每一輪都是在前面所有訊息後面再接一句,於是第 1 步存 1 則、第 2 步存 2 則、到第 N 步存 N 則… 前面的內容被一存再存,儲存成本是用 O(N²) 在膨脹。官方給的數字很嚇人: 一段累積到約 10 萬 token 的對話,單一執行緒就吃掉約 250 MB;外推到百萬 token 等級會到約 25 GB。多輪對話拖越長,重複浪費越誇張。
他們的解法叫 DeltaChannel,精神跟前面 AG-UI 的「快照 / 增量」一模一樣: 別每步都存完整清單,只存「這一步新增了什麼」(增量),要讀的時候再順著增量鏈把狀態重播回來;再加一個 snapshot_every 參數,每隔幾步存一張完整快照,免得重播鏈拉太長。儲存成本就從 O(N²) 降到 O(N),同一段對話省下幾十倍空間(官方實測 500 輪、約 10 萬 token 的對話,從 252 MB 降到約 712 KB)。
編按: 這個儲存最佳化的細節可以參考 LangGraph 的 DeltaChannel PR #7547 和官方持久化文件的「Optimize checkpoint storage」一節。
這也帶出一個蠻漂亮的呼應: 「快照 / 增量」這組設計,在串流時是為了省頻寬,在儲存時是為了省空間,在斷線重連和回放時又變成「接得回去、放得出來」的關鍵。同一套格式上的巧思,一次解決了好幾層的問題。
而「一段執行就是一串事件」這個想法,甚至已經被做進基礎設施。LangChain 在 2026 年 5 月發表了一個專門的資料庫 SmithDB,用來扛 agent 的觀測(observability)資料,它的核心設計原則一句話就講完,而且跟這篇通篇在講的是同一件事:「一段執行是一串事件,不是一筆不可變的資料列」(a run is a sequence of events, not a single immutable row)。當 agent 動輒跑好幾個小時、夾帶上百個巢狀步驟和圖片影音,連儲存層都得照著「事件序列」的形狀重新設計。它還有個細節值得一抄: 把核心欄位和大塊內容(工具的長輸出、模型回應)分開存,主資料列只放指標,真的要看某一筆時才把大內容拉出來,列表和篩選就不會被大 payload 拖慢。從串流、儲存到觀測,大家其實都在往同一個方向收斂。
收尾: 串流是一個你要設計的應用層介面
繞了一圈,這些設計講的其實是同一件事: 串流不再是每個應用都得自己解析的低階傳輸細節,它變成了一個 你要主動設計的應用層介面。
而且這層格式並不貴。把上游 API 轉成你自己的事件格式,不過是讓 CPU 做點轉換,擺在動輒好幾秒的 LLM 請求延遲面前根本不算什麼。所以就算只是純聊天介面,也建議隔一層自己的格式(裡頭留一個文字增量事件,照樣有逐字打字的感覺),差別只在要做到多細: 聊天可能只需要訊息加上少量狀態,agent 當同事的產品才需要長出完整的頻道、命名空間和回放。
格式設計得好不好,直接決定了你能不能只訂閱螢幕上那塊 agent 的工作、用對的抽象去呈現它、在執行越拉越長時保持連線、在使用者回訪時完整重播。用 Bromann 的話收尾最貼切: 串流 agent 該像在「寫應用程式」,而不是在「讀一堆日誌」。