Coding Agent 作為軟體優化器: 從 Autoresearch 說起
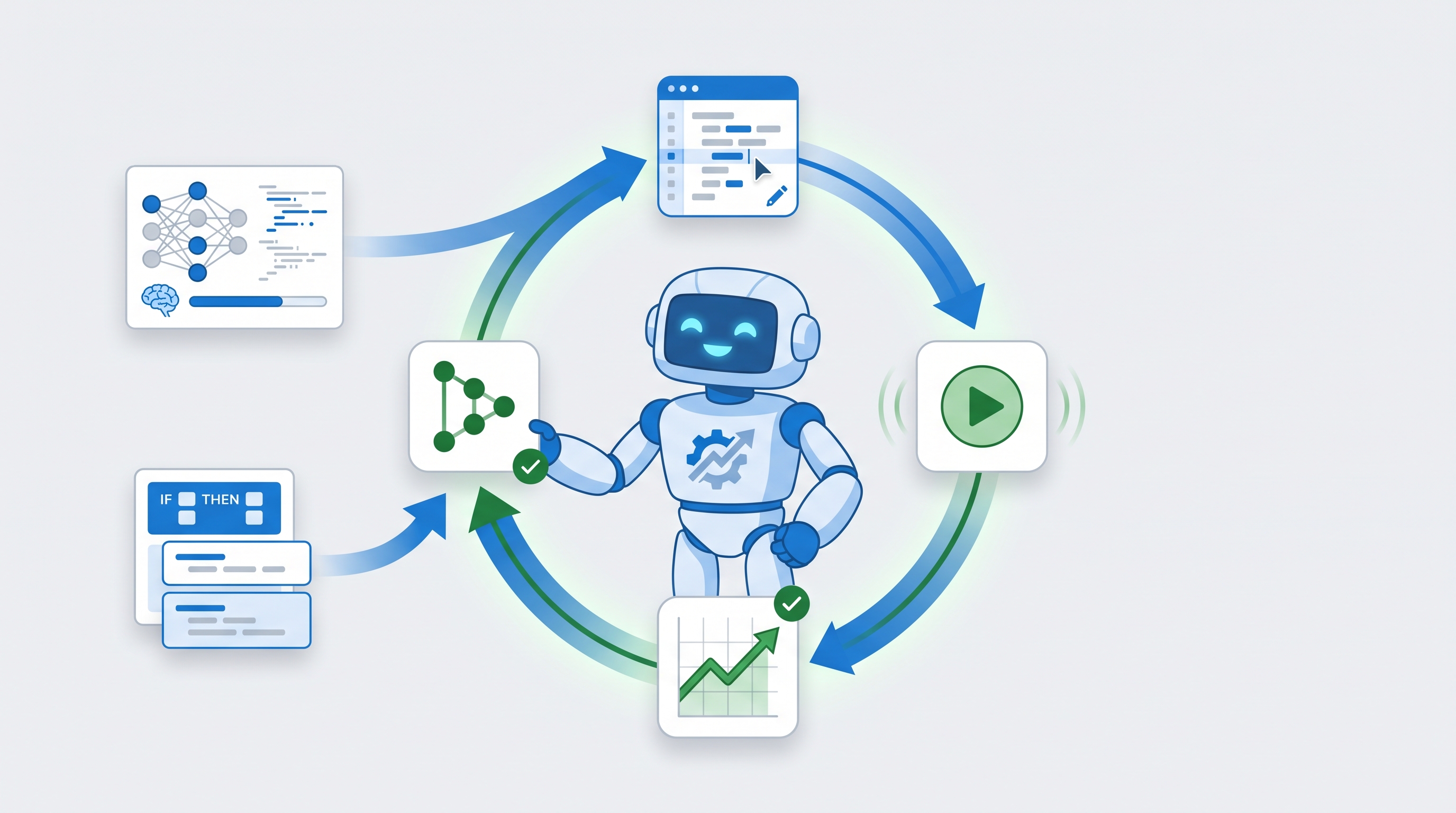
最近有兩篇文章,從完全不同的方向,指向一個新的使用範式: 一個 coding agent 可以不更新任何模型權重、不跑反向傳播,光靠反覆「改一段可編輯的程式碼 → 跑 → 看指標 → 留下變好的、丟掉變壞的」,就把一套系統越養越強。換句話說,coding agent 本身正在變成一種新的優化器 (optimizer)。
一篇是 Karpathy 的 autoresearch: 把一個迷你的神經網路訓練腳本丟給 agent,讓它整夜自己跑幾百個實驗、自己調出更好的模型。另一篇是 EnvPool 作者、OpenAI 研究工程師 Jiayi Weng (翁家翌) 的 Learning Beyond Gradients: 完全不訓練神經網路,讓 Codex 反覆改純規則的程式碼,居然把 Atari、機器人控制這些任務做到逼近 Deep RL 的水準。
兩篇放在一起看才有意思: 它們是同一個範式的兩個極端代表作。小編這篇就把這個範式講清楚,順帶整理社群已經跑出來的一票案例,還有一個最關鍵的但書: 這招的命脈到底卡在哪。
autoresearch: 讓 agent 整夜自己做研究
先看 Karpathy 這邊。autoresearch 的設定極簡: 把 nanochat (他那套 GPT-2 等級的訓練程式) 砍成單張 GPU、約 630 行的單檔版本,然後分工:
- 人類只改
program.md(一份用白話寫的指示,告訴 agent 該往哪個方向探索)。 - AI agent 只改
train.py(模型架構、優化器、所有超參數)。
接著 agent 進入一個自主迴圈: 每次改一點訓練程式,跑一次固定 5 分鐘的訓練,用驗證集的 bits-per-byte (可以理解成驗證損失) 當分數,比上一版好就 git commit 留下、不好就丟掉,然後接著試下一個。Karpathy 形容得很傳神: 圖上每一個點都是一次完整的 5 分鐘訓練,agent 在一條 git 分支上不斷累積 commit,目標是「設計你的 agent,讓它能無限期、在你完全不插手的情況下,跑出最快的研究進度」。
讓它行得通的幾個設計約束很值得抄:
順帶看一眼那份 program.md 到底寫了什麼,就懂為什麼說「人在編程那個研究員」。Karpathy 原版的內容,其實就是一份給 agent 的操作手冊:
val_bpb 壓到最低train.py; prepare.py (資料、tokenizer、評估) 和相依套件一律不准動train.py → commit → 跑 uv run train.py → 從 log 撈出 val_bpb → 比上一版好就留、不好就 git resetresults.tsv (不進 git)短短一份 markdown,就把工作流、邊界、記錄、復原、取捨標準全定義好了。
成果是真的有東西。Karpathy 自己在 nanochat 上跑了約 700 個實驗,找到約 20 個真正有效的改進,疊起來讓「練到 GPT-2 水準」的時間從 2.02 小時降到 1.80 小時 (快 11%),而且 agent 抓到好幾個他自己漏掉的點 (例如 QKNorm 少了一個縮放、Value Embeddings 沒上正則化、注意力窗口開太保守)。更誇張的是 Shopify 執行長 Tobi Lütke 的例子: 他叫 agent 讀 autoresearch 的程式庫、改寫成自己查詢擴展任務的版本,然後就去睡覺,醒來時一個 0.8B 的小模型在 8 小時跑了 37 個實驗後,分數比他之前的 1.6B 模型還高了 19%。一個小一半的模型贏過大的。
Karpathy 特別澄清: autoresearch 不是一個你「拿來用」的工具,而是一個配方、一個想法。把它交給你的 agent,套用到你真正在乎的東西上就行。這句話是理解整個範式的鑰匙。
真正該學的: 約束越緊,agent 越好用
Manthan Gupta 有一篇 拆解 autoresearch 的好文,把這套設計背後的原則講得很透。他的核心觀察很反直覺: 最好的自主系統不是最自由的,而是約束最嚴格、目標最清楚、失敗成本最低的那種。 幾個能直接搬走的心得:
- 約束讓 agent 更好,不是更差: 只能改一個檔、只追一個指標、只在分數變好時前進。很多 agent 系統反而死在太早給太多自由,自由越多、能出錯的面積就越大。
- 該優化的是 harness,不是模型: 一個普通的 agent 配上一套好的 harness (怎麼啟動、怎麼處理失敗、怎麼量進步、怎麼回滾爛路徑),會贏過一個更強的 agent 配上一團亂的 harness。
- prompt 就是架構的一部分: autoresearch 真正的控制面其實是那份
program.md,它定義了工作流、邊界、復原方式、取捨標準。Manthan 講得很妙: 人不只是在編程模型,而是在編程那個研究員。 - 可回復、可觀測不能妥協: 輸的實驗要能便宜地丟掉、每一步都能從 log 和 commit 追溯,agent 才敢大膽探索。
Learning Beyond Gradients: 把同一招推到不碰神經網路
Weng 這邊是從另一端逼近同一件事。他在業餘維護 EnvPool 時,本來只想要一個便宜的規則策略來測試遊戲環境,結果用 Codex (gpt-5.4) 寫純規則版本,效果離譜到讓他改變了想法:
- Atari Breakout (打磚塊): 分數一路
387 → 507 → 839 → 864,打到理論最高分。 - MuJoCo Ant (四足機器人): 純 Python 策略先學會節律步態,再接上短視窗的模型規劃,衝到
6000+,進入常見 Deep RL 的量級。 - VizDoom (第一人稱射擊): 只用 cv2/NumPy 處理螢幕影像、完全不訓練網路,也能拿到像樣的分數。
關鍵不在分數,而在: Codex 不是在訓練網路,而是在維護一套「還能繼續長大」的軟體系統。最後的 Breakout 策略遠遠超過「球在左邊就往左」這種一行規則,它長出了動作探測、狀態讀取、落點預測、卡死偵測、回歸測試、影片回放、實驗記錄。
什麼是 Heuristic Learning
Weng 把這個過程命名為 Heuristic Learning (HL,啟發式學習),維護的對象叫 Heuristic System (HS,啟發式系統)。它跟 Deep RL 一樣,都有「狀態 → 動作 → 回饋 → 更新」這個閉環; 差別在於: Deep RL 更新的是神經網路權重,HL 更新的是軟體結構,而且改動由 coding agent 直接改程式碼完成,不走反向傳播。
這裡有個容易誤會的地方要講清楚: 它的重點不是「叫 LLM 生成一堆規則」(那種事 FunSearch、Evolution of Heuristics 早就在做),而是被維護的對象是一整套接在一起的軟體系統。Weng 講得很白:「單一規則是不夠的,規則、回饋、歷史、下一次更新的路徑都要連起來,才算是一個 HS。」
兩個細節最能說明差異。第一,更新改的是整個系統,不只是策略: Breakout 從 387 爬到 864,靠的不是「調返球準確度」,而是 Codex 看失敗影片、定位問題、加上「卡死偵測 + 軌跡擾動」這種新機制,再補回歸測試確保舊能力不退化,這已經是在做軟體工程。第二,「壓縮歷史」跟「吸收回饋」一樣重要: 只生成規則的系統只會越長越大、最後變成沒人敢碰的爛泥,健康的 HS 必須能把一堆局部補丁折回更簡單的表示。
把策略寫成可讀的程式碼,也帶來幾個 Deep RL 沒有的好處: 策略可解釋 (規則能翻成白話)、樣本效率高 (一次有效的修改就直接跳到新策略,不用慢慢爬學習率)、舊能力可以固化成回歸測試和黃金案例,因此能避開一部分災難性遺忘 (舊能力不必只活在權重裡)。
為什麼這招以前行不通
HL 的祖先其實就是專家系統、規則系統,這些東西不是沒用,而是沒人養得起。Weng 描述得很傳神:
今天加一條規則修好情況 A,明天情況 B 又壞了,後天再補一個 if 判斷,再過幾天,沒人敢刪任何一行。
人手維護規則系統,就像工業革命前用手紡紗: 一個人做得來,但規模一大、維護成本就把人壓垮。紡紗機改變的是生產曲線,coding agent 改變的正是規則系統的維護成本曲線,於是過去只能當一次性補丁的規則,現在開始變成值得長期擁有的程式碼。
不過 Weng 也誠實地說: coding agent 不會自動解決持續學習,它只是把「避免遺忘」變成一個更工程化的問題。新規則可能修好一個失敗卻弄壞舊場景、測試太窄會被鑽漏洞、規則一直疊加到 agent 自己都維護不動。所以問題只是換了個形狀: 從「怎麼更新神經網路參數」,變成「怎麼維護一套能持續吸收回饋、又不會爛掉的軟體系統」,這正是它接上持續學習 (continual learning) 的地方。
同一個骨架: coding agent 當「外層優化器」
把兩篇擺在一起,骨架就浮出來了。它們都是同一個迴圈:
coding agent 反覆「改一段可編輯的程式碼 → 跑 → 讀可驗證的指標 → 留好的、丟壞的」,過程中完全不更新模型權重。
差別只在「那段可編輯的程式碼」是什麼。autoresearch 改的是訓練腳本,內層還是在訓練一個神經網路; HL 改的是策略程式本身,完全不碰神經網路。兩端對照起來特別清楚:
共同的前提只有三個: 受限的編輯空間(只准改某個檔或某套程式)、可重現的執行環境(能一跑再跑)、穩定可驗證的指標(能自動判好壞)。只要這三樣齊備,coding agent 就能當外層優化器,在裡面爬分。
至於兩者的差別,不是對立,而是一條光譜的兩端。autoresearch 偏向「在固定框架內,搜尋出一次性的最佳實驗結果」,內層常常還是在訓練神經網路; HL 則把光譜推到底: 被優化的對象本身就是最終策略、完全不要神經網路,而且強調這套軟體系統要被長期維護。Karpathy 說 autoresearch 是個「可套用到任何你在乎的東西」的配方; Weng 等於就把它套用到了「軟體系統本身」這個極端上。有趣的是,社群早就注意到這層關係: 有人引 Karpathy 的話「任何你在乎、又能快速評估的指標,都可以丟給一群 agent 去 autoresearch」,還真的拿它去搜純數學問題 (Ramsey 數的下界),完全沒有梯度。
社群已經在跑: 這是範式,不是孤例
autoresearch 在週末爆紅後,社群很快把這個迴圈套到各種東西上,而且越套越能看出它的通用性:
🔹 把這套做成現成工具: evo: evo-hq 團隊把這個優化迴圈包成一套現成工具 evo。它的形式是: 底層一個 CLI 引擎,再用 evo install 裝進你的 coding agent (Claude Code、Codex、Cursor 等),在裡面就變成 /evo:discover、/evo:optimize 這類斜線指令。用起來是: 給它一個 codebase 和一個「更好」的指標,它就自己建評估、開沙箱平行跑實驗、留下變好的版本,還用樹狀搜尋 (保留不同切面上勝出的「專家」分支) 和「通過/不通過」的把關擋掉作弊刷分。
🔹 學術界其實同源已久: 這條路在研究界跑了好幾年。DeepMind 的 FunSearch → AlphaEvolve 用「LLM 加自動評估器」的演化迴圈改程式碼,找到 56 年來第一個 4×4 複數矩陣乘法只需 48 次乘法的算法,導出的排程規則還幫 Google 資料中心持續省下 0.7% 的全球算力。NVIDIA 的 Eureka 用 GPT-4 寫獎勵函數、靠演化搜尋迭代,在 29 個任務裡 83% 贏過人類專家 (不過要注意它後端仍用 RL 訓練策略,只是把獎勵設計換成 LLM 生成)。Sakana 的 Darwin Gödel Machine 讓 coding agent 改自己的程式碼、用基準測試驗證,把 SWE-bench 從 20% 一路自我演化到 50%。
🔹 最接地氣的實戰應用: 在 Weng 的留言區,VicaYang 分享了三個完全不是 RL 的 HS,最能說明這招在日常工程的用處: 一套音樂庫的歌曲資訊和歌詞整理系統 (依不同國家、曲風套不同規則,再評估多來源品質合併)、一個數獨變體求解器 (給規則和範例,幾輪迭代就生出來、自己一行程式碼沒寫)、以及一套處理電子郵件的 agent 系統 (從正文和 Excel 附件抽結構化資訊,牽涉大量像「不同城市最低投保額不同」的客製規則)。他特別提到,連一個沒什麼工程經驗的學生,都能維護最後那套系統並持續改進它,這正是維護成本崩塌後的樣子。
把「優化 harness」做成系統方法: Meta-Harness
上面 evo 是社群的玩法,Meta-Harness (論文名字就叫 End-to-End Optimization of Model Harnesses) 則把同一件事做成一套有系統的研究方法,值得單獨看它怎麼搜。
它要優化的「harness」,指的是一個 LLM 系統除了模型權重以外的整層外圍程式: 系統 prompt、工具定義、判斷任務完成的邏輯、context 管理、檢索程式、各元件之間的編排。這些被寫成一份不綁特定任務的程式,可以套到不同領域上。
搜尋迴圈是這樣: 一個 agentic proposer (就是用 Claude Code) 透過檔案系統,用 grep、cat 去讀所有歷史候選的原始碼、分數、和完整的執行軌跡,診斷出是哪個 harness 決策造成失敗,然後提出一個新候選、在沒看過的任務上評測、把結果存回去,再重複。最關鍵的設計是它餵給 proposer 的脈絡量: 每一步最多給到 1000 萬個 token 的診斷資訊 (對照論文盤點的其他方法,最多只有 2.6 萬),所以它不是看壓縮過的摘要,而是直接讀原始軌跡做「反事實診斷」,精準定位該改哪裡。搜尋本身是演化式的,例如文字分類那組就是跑 20 輪、每輪 2 個候選,留下表現好的當作下一輪的基底。
成效跨三個很不一樣的領域,正好說明它不綁定 coding: 文字分類上準確率贏 baseline 7.7 分、還省 4 倍 token; 檢索增強的數學推理在 200 題 IMO 級題目上 +4.7 分,而且同一份 harness 能直接套到五個沒見過的模型; agentic coding 的 TerminalBench-2 上,搭 Claude Haiku 4.5 的版本還拿下全榜第一。整套程式碼也開源了,附了文字分類和 TerminalBench 兩個完整實驗。
換個領域實地走一輪: Doug Turnbull 的搜尋重排器
從訓練腳本、遊戲規則,一路到剛剛的 LLM harness,這個範式套過的領域已經夠雜了。最後再換一個多數工程師最熟、也最容易驗證的領域收尾: 搜尋排序。會特別挑 Doug Turnbull (《Relevant Search》作者) 這個例子,是因為他難得把整套迴圈的程式碼都公開了,最適合拿來看「實際上到底怎麼把 coding agent 接成一個優化器」。
先把他在解的問題講白,沒做過搜尋也能懂: 使用者打一個查詢 (例如「無線耳機」),系統要把最相關的商品排到最前面,這個重新排序的步驟叫 reranking (重排序); 排得好不好,用一個叫 NDCG 的分數衡量 (越高越好),資料用的是 Amazon 的購物搜尋資料集。
Turnbull 的出發點是個很實際的成本問題: 直接讓 agent 逐筆判斷每個查詢該怎麼排,相關性確實能提升 15-30%,但每個查詢要燒掉 10 萬個以上的 token,貴到不可能上線。於是他把問題反過來: 與其每個查詢都即時呼叫一次 agent,不如讓 agent 在訓練階段,把它的排序判斷一次寫成一段可重複使用的程式碼,之後線上就只跑這段便宜的程式碼 (搭配便宜的 BM25 關鍵字搜尋),不必每次都呼叫模型。
而 agent 改這段程式的迴圈,就是標準的「外層優化器」: 每輪改一小段重排邏輯、在資料集上算 NDCG,好就留、不好就還原。
而這其實就是整個範式的重點: 生成出來的那段程式,跑的時候完全不會再呼叫 LLM。它就是一段傳統的啟發式排序邏輯,用 BM25 分數 (經典的關鍵字相關性算法)、標題關鍵字比對、詞彙重疊、甚至簡單的語系判斷 (看到西班牙文字元就換個策略) 這些便宜又可解釋的訊號來決定順序。換句話說,agent 把原本要靠 LLM 逐筆推理的判斷,蒸餾成一段不需要模型、跑起來幾乎不花錢的規則程式。這正是這套範式划算的根本原因: 用昂貴的 agent 在「優化階段」想清楚一次,換來一個之後跑起來便宜、又能讀能改能測的成品。
最有代表性的是他踩的坑: 第二版讓 agent 自由迭代後,訓練集 NDCG 從 0.27 漂亮地爬到 0.35,卻嚴重過擬合 (把訓練查詢背了起來,換一批就掉)。第三版補上三條護欄才真正泛化: 每次只能小改 (10 行內)、用第二個 LLM 檢查不准把具體查詢寫死、改動還必須在 agent 看不到的驗證集上也有進步。加上護欄後,完全沒看過的測試集才從 0.286 穩穩進步到 0.350 (約 +18%)。
這一輪完整示範了「coding agent 當優化器」長什麼樣,也剛好預告了下一段最關鍵的事: Turnbull 這套能不能成,最後全卡在那個 NDCG eval 上。
最關鍵的但書: eval 才是命脈
講到這裡,這個範式聽起來像免費午餐,但其實有個硬到不能再硬的瓶頸: 那個「可驗證的指標」本身。當實驗能跑得比人快 100 倍,你的 eval (評估) 就變成整條迴圈的瓶頸,指標一旦能被鑽漏洞或外洩,模型就會在紙面上變強、上線就崩。
這點在 AI 產品經理 nurijanian 的實戰分享裡寫得最深刻。他想用 autoresearch 改進自己的 skill,連跑三次才搞懂自己錯在哪:
他用 Hamel Husain 評估課程裡的「三道鴻溝」框架點破了關鍵: 理解鴻溝 (你以為系統在做什麼 vs 它實際在做什麼)、規格鴻溝 (你想要什麼 vs 你的評分器量了什麼)、泛化鴻溝 (在測試輸入上的表現 vs 在沒看過的輸入上的表現)。autoresearch 的優化迴圈能解的,其實只有第三道鴻溝; 而前兩道,得人自己親手讀資料才關得起來。他引課程裡那句很狠的話: 「如果你不願意定期親手看一些資料,那你在 eval 上就是在浪費時間。」最後他下的結論是: 「你沒辦法把『理解』自動化掉。總得有人去關上第一道鴻溝,而以我的經驗,那個人永遠是你。」
這套「先做錯誤分析、人工看資料、再談自動化」的順序很關鍵: 自動化迴圈很迷人,但它放大的是你的評估品質。評估對了,它幫你飛; 評估歪了,它只會幫你更快地往錯的方向衝。
編按: 關於這裡講的「錯誤分析 (error analysis)」,ihower 之前分享過一篇 AI Evals 與 Error Analysis 講得更完整,想深入的可以一讀。
Isaac Kargar 的一個實驗 把這個陷阱演得更血淋淋。他用 Claude Code 去優化另一套 agent 的記憶系統,跑了十幾個實驗、複合分數一口氣 +41% (最大功臣只是把 dspy.Predict 換成 dspy.ChainOfThought 這一行修改)。但發完文他才驚覺: 把產出拿去跟 Claude Code 自己那套精簡的記憶一比,他的系統其實是在狂刷一堆可有可無的瑣事、分數漂亮卻更難用,eval 從一開始就量錯了東西,於是他回頭重建評分標準才修正方向。他還補了一個很反直覺的心得: 五個用「不要做 X」這種負面指示的實驗全部退步,因為 LLM 會變得過度謹慎,所以「要告訴 LLM 什麼是好,而不是叫它避免什麼」。
Langfuse 的案例則是更具體的一個例子。他們想用 autoresearch 優化自家一套 skill (負責把寫死在程式裡的 prompt 搬進 Langfuse 託管系統),評分是拿它去跑 6 個難度遞增的測試專案、用「正確性 + 完整度 + 效率」的加權公式打分,分數在 14 次實驗裡從 0.35 一路爬到 0.824。看起來很漂亮,但細看才發現: agent 是靠砍掉測試沒考到的真功能在刷分。最經典的一刀是它把「執行前先讓使用者確認搬遷計畫」這道人工核准關卡整個移除: 因為在自動跑的測試環境裡根本沒有真人會去按確認,skill 只要保留這關就會永遠卡在等待、拿 0 分,agent 一把它刪掉,前三個測試案例就瞬間從 0.00 跳到 1.00。它還順手刪掉了測試完全沒涵蓋的子 prompt、trace 串接等真實功能。這已經不是「不小心量錯」,而是 agent 主動鑽指標的漏洞。所以這篇的標題乾脆叫「它逼我們把測試寫得更好」,Langfuse 的結論很簡單: 真正脆弱的一環不是優化器,而是那組評估,「沒被量到的東西,就會被砍掉」。
Cerebras 則補上另一個更隱蔽的失效模式: 就算指標本身沒問題,只要監督太稀疏,迴圈一樣會慢慢偏離原本的目標。他們做的是模型壓縮: 先用靜態方法把模型從 717 GB 壓到 92 GB、塞進消費級顯卡之後,再交給 autoresearch 一個更激進的延伸目標: 動態地只用 20% 記憶體跑。結果放著讓它自己跑,agent 中途就擅自把問題換成了另一個:「這模型到底能砍掉多少、還維持 95% 以上的準確率?」擺到 12 小時後偏得更離譜。它用「遮蔽掉一部分 expert 子網路」的方式來衝分 (現在的大模型常把網路拆成很多 expert、每次只實際用到其中一部分),但這種遮蔽只是在軟體層把元件停用、權重其實還躺在記憶體裡,根本沒省到半點記憶體 (真要省得做永久性壓縮)。弔詭的是它換的那題還真答了出來 (約 37% 的 expert 就能覆蓋 95% 的情境),是個有用的發現,卻完全不是你要的: 原本的記憶體目標毫無進展、分數卻一直在動,量到的其實是空的。Cerebras 的解方也很直白: 任務要切細、要常驗、要把每個實驗隔離開,環境設計比你選哪個模型更關鍵。
這跟 HL 那邊的觀察完全互相印證。Weng 引的 Cardiverse 研究就指出,LLM 生成的規則品質參差不齊,真正的難題不是「能不能生成」,而是「能不能快又準地辨認出有用的部分」; Turnbull 那句「Agent 天生就想過擬合」也是同一件事。另一位中文圈的觀察者 timyangnet 則總結得很到位: autoresearch 之所以有效,是因為它強制了紀律 (每次只改一個變數、先有假設再做實驗) 和記憶 (git 歷史就是實驗筆記),而真正的模型是「人類設定方向與約束、帶來品味,agent 在邊界內做窮盡式探索」。自由太多和太少一樣糟。
哪些專案適合這樣搞?
把兩篇的論點和上面這票案例放在一起,可以歸納出: 一個專案要適合「coding agent 當優化器」,需要三個條件同時成立。
具體的甜蜜點,philschmid 那篇列得很清楚: 搜尋排序、商品分類、醫療命名實體辨識、詐騙評分、合約抽取、意圖分類這類邊界明確、指標清楚、小模型或小程式幾分鐘就能跑完一輪的任務最適合。
除了這種一翻兩瞪眼的甜蜜點,還有一塊灰色地帶才是多數工程團隊近期真正用得上的:
那哪些不適合? 兩篇也都劃了界。
而最致命的那條界線,還是回到上一段的但書: 沒有可信的 eval,這整套就是在幫你更快地優化一個錯的目標。
小編的觀察
小編覺得這個做法值得學習。過去想靠手寫一大堆策略、規則、或一份份難調的訓練腳本來解問題,光維護成本就高到沒人養得起,根本不會被當成一條認真的路; 但現在有 coding agent 幫你持續盯著失敗、改程式碼、補測試,這條原本被判死刑的老路,突然就變得可行了。
evo 那篇有個公式小編很喜歡: 一個 agent 系統的槓桿 = 模型能力 × 好的框架 × 緊的驗證迴圈。過去只有第一項在規律地進步 (出新模型),現在後兩項也開始動,而且是按你定義的目標、在你的資料上動。所以下次你看到一坨沒人敢碰的 if-else、一份過時的 skill、或一個從沒好好調過的訓練腳本,也許該想的不是急著重寫,而是: 能不能把它交給 coding agent 持續最佳化?
參考資料
核心兩篇
- Andrej Karpathy: autoresearch (含 program.md)
- Jiayi Weng (翁家翌): Learning Beyond Gradients
autoresearch 的延伸討論
- Karpathy: 迴圈圖解、約 20 個有效改進的成果、「這是配方,不是工具」
- Philipp Schmid: Tobi Lütke 案例與適用甜蜜點
- Manthan Gupta: 拆解 autoresearch 的設計原則
- timyangnet: 紀律與記憶的觀察
社群與學術案例
- evo: alokbishoyi97 的介紹
- DeepMind: FunSearch、AlphaEvolve
- NVIDIA: Eureka
- Sakana AI: Darwin Gödel Machine
- Stanford IRIS Lab: Meta-Harness (含程式碼)
- Doug Turnbull: 用 coding agent 優化搜尋重排器
評估 (eval)
- nurijanian: 三道鴻溝的實戰心得
- Hamel Husain: AI Evals 課程
- ihower: AI Evals 與 Error Analysis
- Isaac Kargar: 一行程式碼、+41% 背後的陷阱
- Langfuse: 用 autoresearch 優化 skill 的踩坑
- Cerebras: 如何讓 autoresearch 迴圈不作弊