當模型表現取決於推論算力: 評測分數正在失去意義,LLM 能力上限也量不出來
OpenAI 研究員 Noam Brown (推理模型 o1 背後的關鍵人物) 發了一篇長文 Implications of Large-Scale Test-Time Compute,蠻有料的。核心論點一句話就能講完: 隨著 LLM 越來越強,benchmark 分數越來越取決於模型在推論時用掉多少算力,也就是「測試時算力」(test-time compute)。我們很可能不知道現代 LLM 的能力上限在哪裡,因為要實際量測它太昂貴了。所以評估方式該改了: 不要只報一個分數,而是畫出一條曲線,呈現模型在不同 token 數、成本或時間下的表現。
以下整理重點,並補充幾篇相關研究。
同一個模型,換個 x 軸就是另一個故事
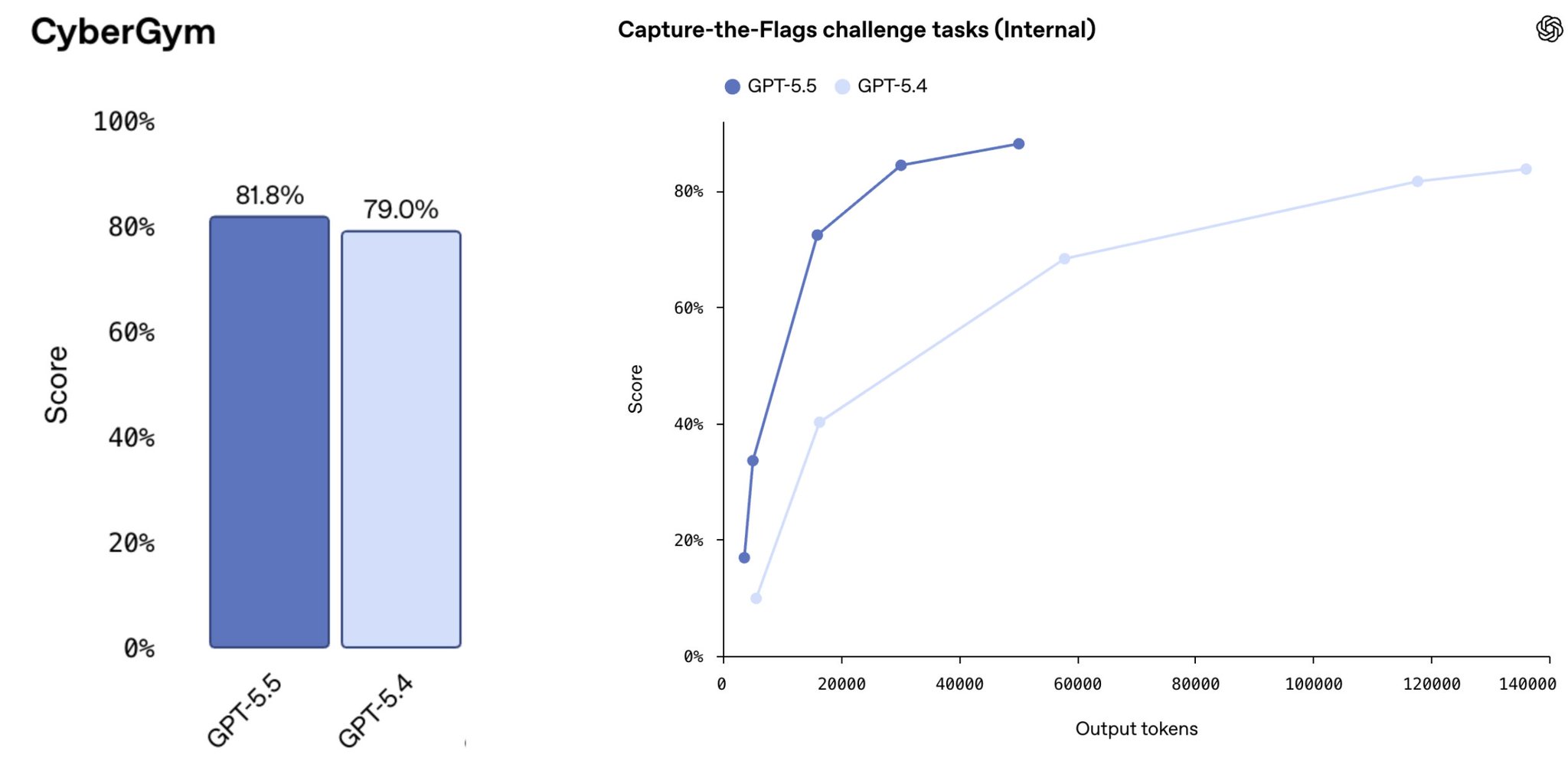
GPT-5.5 剛發布時,第一波反應是質疑: benchmark 數字有進步,但不多。幾小時後大家實際上手,才發現它比 GPT-5.4 強了一個檔次。經典的「benchmark 成績表格」顯然沒有反映出全貌。
原因是 GPT-5.5 並不是在跟 5.4 相同的 token 預算(或美元預算)下評估的。本文封面圖就是 Noam 給的對比: 左邊的長條圖上,兩個模型只差 2.8 個百分點,看起來進步不大。但右邊把 x 軸換成輸出 token 數之後,故事完全不同: 在相同的 token 預算下,5.5 明顯強一截,5.4 要花將近 3 倍的 token 才能追到接近的分數。把測試時算力這個變因控制住,兩個模型的真正差距才顯現出來。
為什麼不直接把算力開到飽和再評估?
最直覺的反問是: 那就讓模型一直算下去,算到分數不再進步為止,量到的不就是上限了? Noam 說問題在於: 實際經驗上,「分數不再進步」這個停滯點(plateau)非常遠,在合理的預算內甚至可能根本看不到。
他舉了兩個例子。一個是 Karpathy 的 autoresearch 實驗,跑了數百次實驗後,表現仍在繼續進步。另一個是英國 AI Security Institute 的資安攻防評測,跑到 1 億 tokens,Mythos 和 GPT-5.5 的表現還在快速上升:
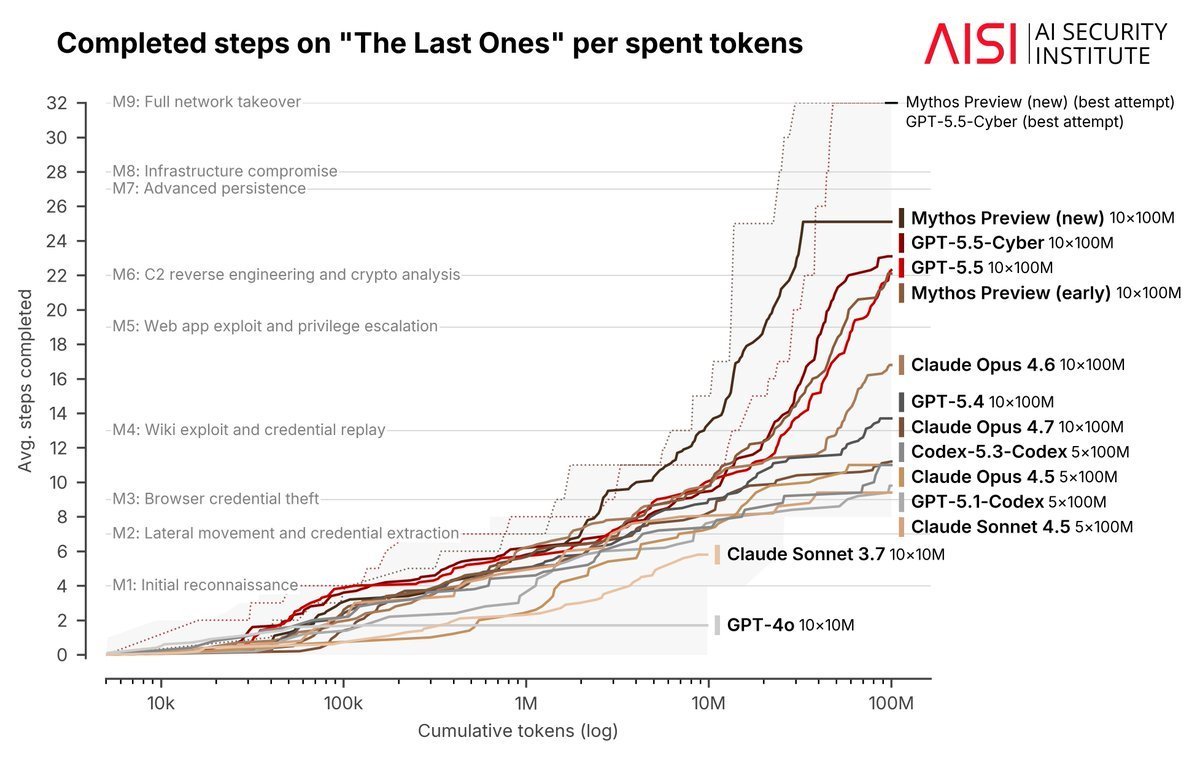
而且注意看這張圖: 越強的模型,分數隨算力成長的幅度也越大。模型越強,就越能在長時間跨度(long horizon)的任務上持續有效運作,停滯點被推得更遠,甚至可能消失。
編按: 「量測上限太昂貴」不是修辭。X 上最近流傳一篇據稱是 Anthropic 未發布模型 Mythos 的企業試點測試心得(中文翻譯),作者說光這一輪測試就花了超過 100 萬美元的推論費用,而他們公司全員上個月的推論算力總開銷也才 200 萬美元。內容真偽無法驗證,但這個量級跟上面那條「跑到 1 億 tokens 還在爬升」的曲線是一致的: 想知道前沿模型的上限在哪,先準備好足夠的預算。
該怎麼評估: 把曲線畫出來
Noam 認為正確的評估方式,是畫出「表現 vs 測試時算力」的曲線,x 軸可以用 token 數、成本或時間。已經有 benchmark 這樣做了,例如 ARC-AGI 的排行榜,直接畫出「分數 vs 每題成本」:
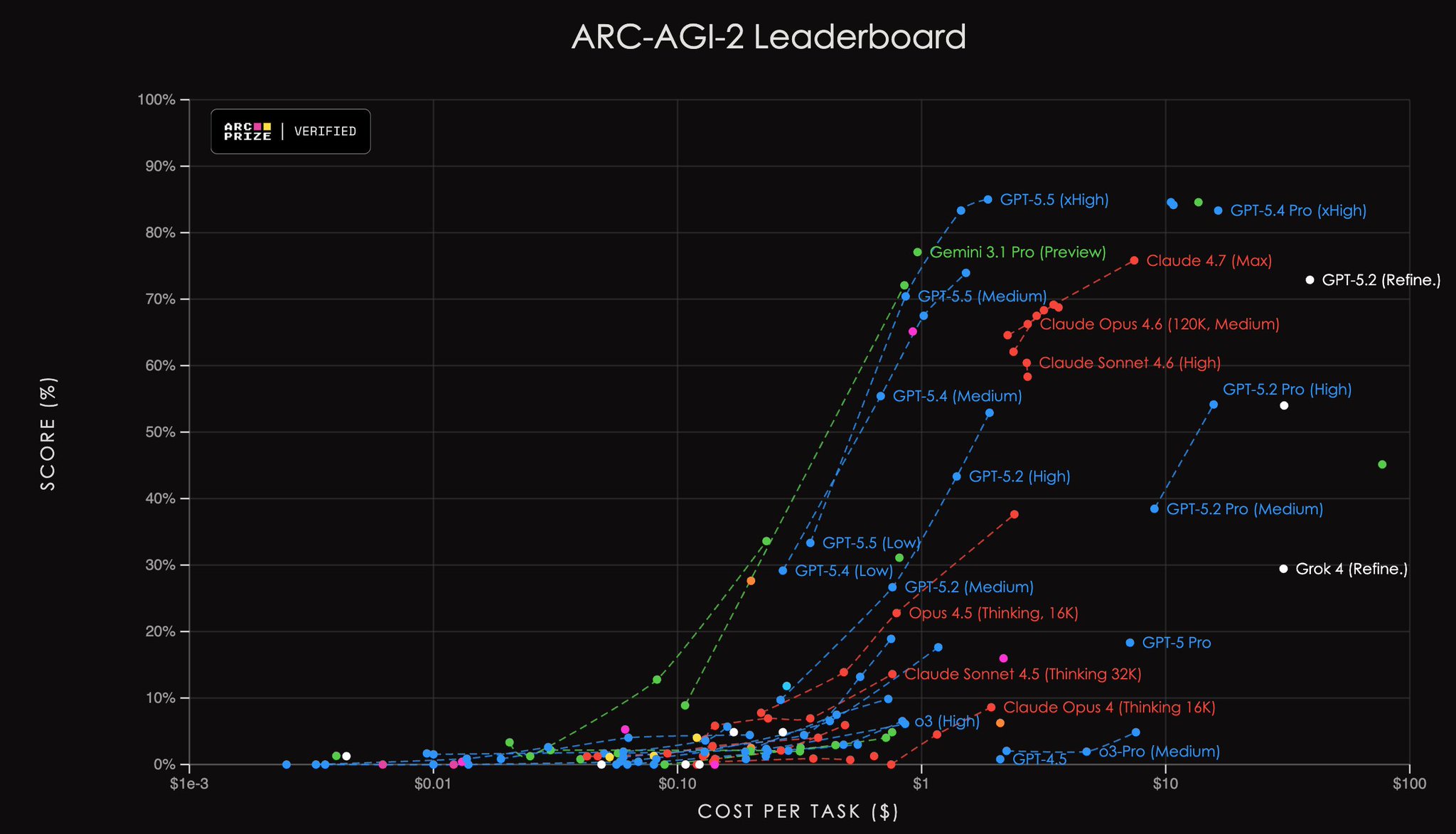
另一個合理的做法是設定明確的 token、時間或成本預算,並且事先告知模型,就像人類考 SAT 或數學奧林匹亞也是限時的。
三種 x 軸各有取捨:
- Token 數: 不同模型之間不能直接比較,因為每家的 tokenizer、生成速度、單價都不同
- 美元成本: 受 batching、硬體利用率等實作細節影響,而且成本和延遲之間會互相取捨
- 實際耗時: 像 best-of-N (平行跑 N 次取最好的結果)這類技巧,可以在幾乎不增加耗時的情況下用掉更多算力,所以時間軸會低估算力用量
但 Noam 的重點是: 不管選哪一個,任何一條曲線都比單一分數有資訊量。
對 AI 安全的影響: 安全評估該用多大的預算跑?
前沿模型發布前,實驗室通常會評估資安攻擊、生物武器等濫用風險,超過能力門檻就要先做好緩解措施才能發布。但如果模型能力取決於用了多少推論算力,那安全評估該用多大的預算來跑? 實務上,多數安全評估根本沒有考慮這件事。
Gemini 3 Deep Think 發布時,benchmark 分數比之前的模型高出一截,卻沒有附上說明風險評估的 model card,引發 AI 安全社群的不滿。但 Noam 認為這個批評沒打到點上: Deep Think 很可能是拿其他「有」做過安全評估的模型,外面再包一層鷹架(scaffold)搭出來的。任何人只要願意付出 Deep Think 等級的推論費用,自己把多次模型呼叫串起來,大概也能重現同樣的能力。Deep Think 只是讓一般使用者更方便取得而已。
真正該檢討的是: Gemini 3 和其他模型發布時,安全報告都沒有把能力表示成測試時算力的函數。一個有決心的國家級行為者,可以對單一任務投入超過 1000 萬美元的推論算力; 但評估模型通常要跑數千甚至數百萬次任務,每一次都用這麼高的預算並不切實際。好消息是,表現隨算力擴展的走勢還算可預測,所以可以在較低預算下實際量測,再(帶著不確定性)外推高預算下的能力。Noam 理想中的模型評估長這樣:
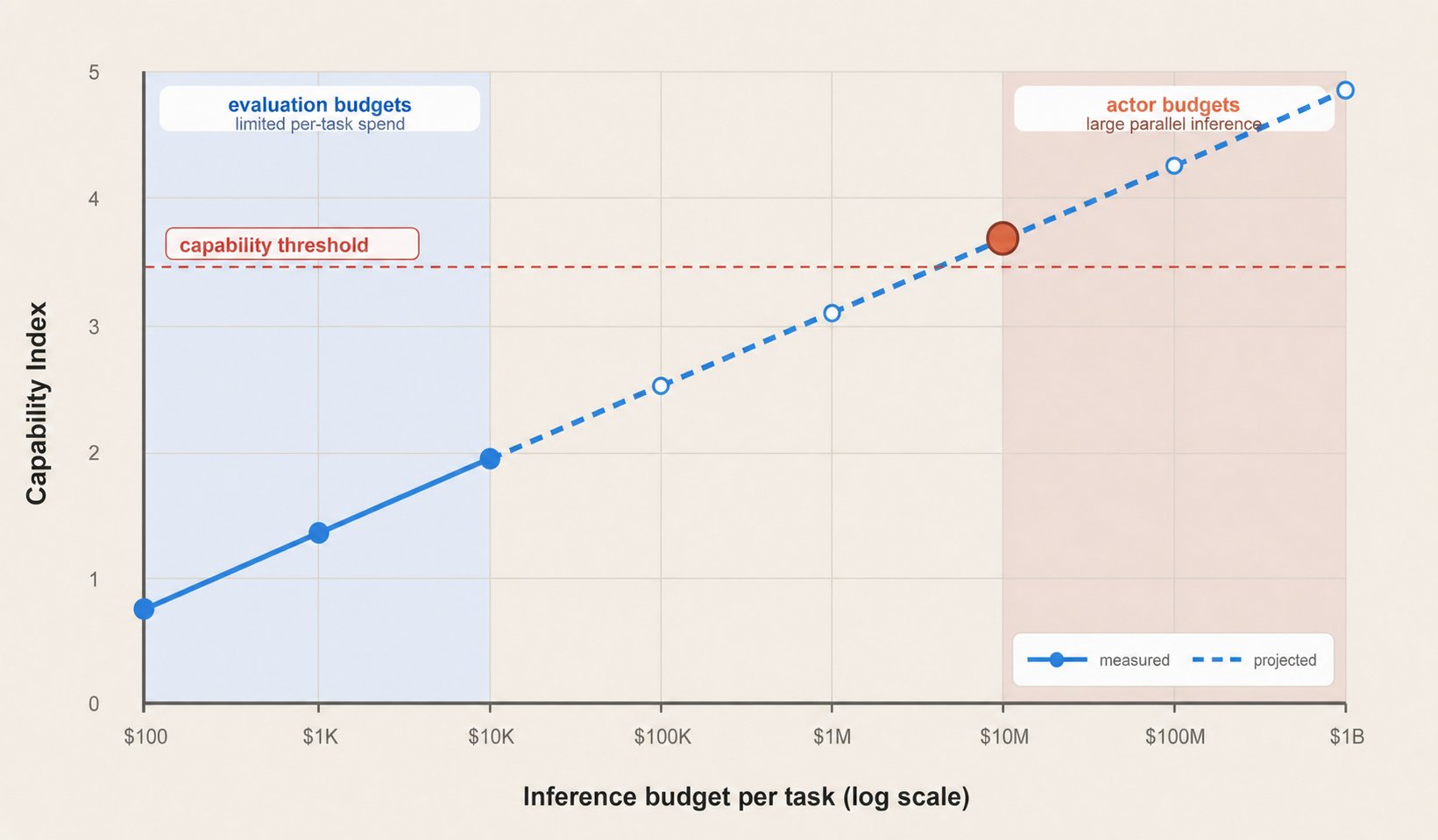
文章還點出一個之後會更麻煩的問題: 要確認一個 agent 連續運作一年都不會出現對齊問題(misalignment),可能唯一的辦法就是真的讓它跑一年。當 agent 的運作時間超過新模型的開發週期,實驗室可能根本來不及在發布前完成完整評估。
Noam Brown 給 AI 社群的三點具體建議
- 實驗室發布新模型時,應該公布以 token 數、成本或時間為 x 軸的 benchmark 表現。至少也要報告達成那個分數用掉了多少推論預算
- Benchmark 排行榜應該一併追蹤推論用量,或是設定明確的 token、成本、時間預算
- 各家實驗室的安全政策(如 OpenAI 的 Preparedness Framework、Anthropic 的 Responsible Scaling Policy)在判定模型是否跨過安全門檻時,應該把推論算力明確納入考量,並在多個預算下評估,包含從小預算外推的估計(附上不確定性)
不只 Noam 在講: 忽略成本的比較正在失效
小編順手查了一下這個主題的其他研究,發現同樣的觀點已經累積不少證據:
ARC Prize: 額外的準確率是可以用錢買的
ARC Prize 共同創辦人 Mike Knoop 在測評各家推理系統時講得更直接:「所有 benchmark 和 model card 的報告都必須沿著兩個軸來做,因為額外的準確率是可以用錢買的。光禿禿的準確率分數是行銷,不是科學。」(原文: Naked accuracy scores are marketing, not science.) 他們的測試結論也是沒有單一贏家: 要最高準確率和要性價比,最佳選擇完全不同。
Artificial Analysis 的 Claude Fable 5 評測
Artificial Analysis 這週發布的 Claude Fable 5 評測就是一個現成的例子。下圖上半部是 Humanity’s Last Exam 的分數排行,Claude Fable 5 以 53.3% 居首; 下半部則是跑完整輪評測的總成本,Fable 5 要 $2,174,而 GPT-5.5 (xhigh) 拿 44.3% 花 $820、GPT-5.5 (high) 拿 43.0% 只花 $489。上下兩半對照著看,結論就從「Claude 領先 9 個百分點」變成「Claude 多花 2.7 倍的成本,買到 9 個百分點」。哪個划算,取決於你的任務值多少錢。若你只看分數排行,不看總成本,那你就無法判斷是否划算:
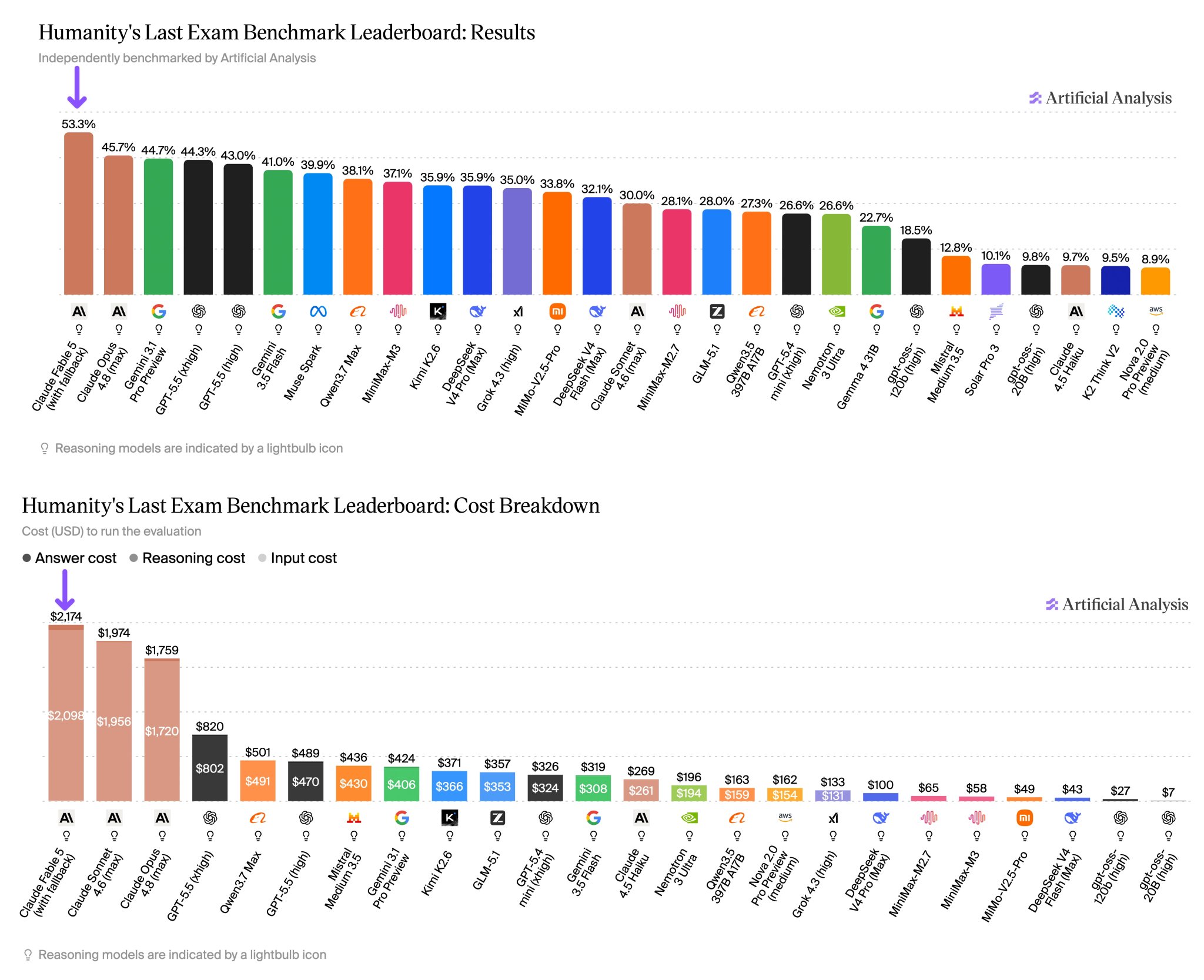
順帶一提,Artificial Analysis 網站上也有「Intelligence Index vs 評測成本」的散點圖,x 軸是跑完整套評測的成本(對數刻度),這是目前業界做模型選型時最常引用的圖表之一。下圖左上角的綠色區塊標示「最划算象限」,GPT-5.5 (xhigh) 和 Claude Opus 4.8 (max) 這些最強模型則都落在右側最貴的那一區:
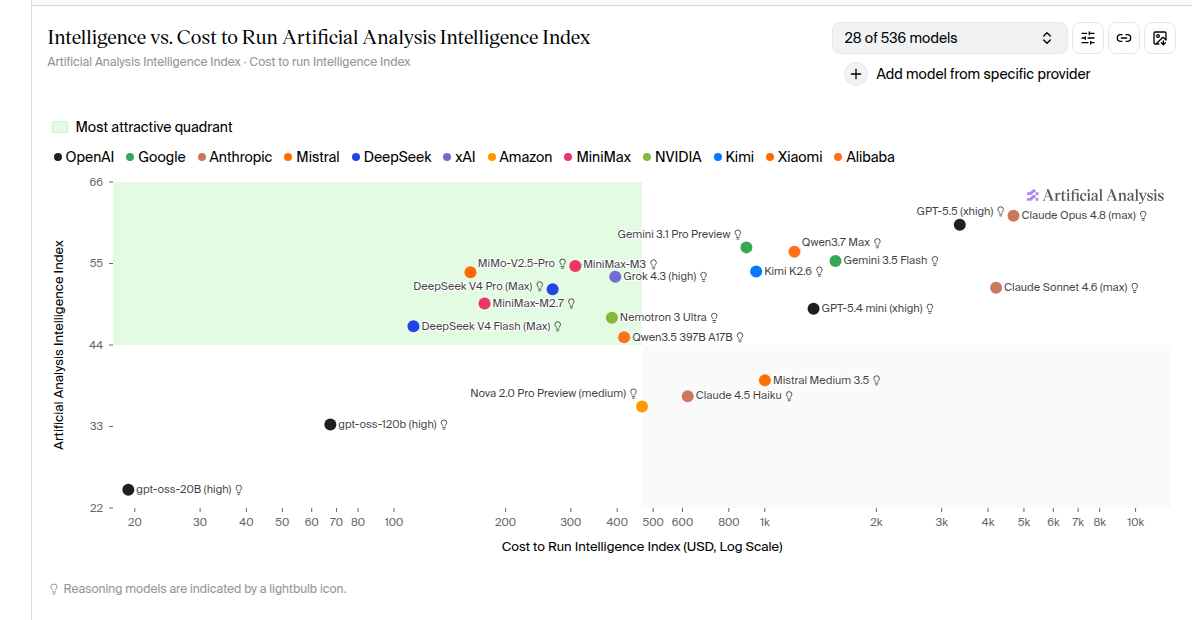
為什麼散點圖上沒有 Claude Fable 5?
不知為何,上面這張圖還沒有標出剛拿下 Intelligence Index 第一名 (64.9 分) 的 Claude Fable 5。AA 的模型頁面上 Fable 5 跑評測的 token 用量標示為 Unknown,小編猜可能是因為它的成本特別難算。Fable 5 有好幾個會在執行時動態改變行為和計費的機制:
- Fallback 機制: 約 9% 的任務會轉給 Opus 4.8 跑、並按 Opus 的單價計費,總成本取決於有多少任務被轉走
- Adaptive thinking 預設全程開啟: 模型自行決定每一題要思考多深,token 用量無法事先固定
- 靜默降級: 根據 system card 第 12-13 頁,偵測到「前沿 LLM 開發」用途時(例如 pretraining pipeline、分散式訓練基礎設施、ML 加速器設計,約佔 0.03% 流量)會靜默限制模型能力: 不換模型、照 Fable 5 原價計費,也不通知使用者,從 API response 完全看不出來。模型甚至不會拒絕,仍會照常配合回應,只是這類任務的輸出效果被刻意壓低。至於怎麼壓低,Anthropic 沒有明講細節,只舉例說作法有: prompt 修改(在使用者看不到的地方改寫或附加指令)、steering vectors(推論時在模型內部的激活值上加一個方向向量,把行為往特定方向推)、參數高效微調(PEFT,掛上讓特定能力變弱的少量微調參數)。Lucas Beyer 等研究員這幾天在 X 上嘲諷的就是這個機制
小編補充 (2026/6/12 更新): 靜默降級有後續發展。在研究社群一片批評聲後,Anthropic 於 6/11 宣布把它改成可見: 被標記的請求會跟 cyber/bio 防護一樣,明顯地 fallback 到 Opus 4.8,每次發生都看得到,API 也會回傳拒絕原因。官方承認當初選擇不可見的防護「是錯誤的取捨」並道歉。代價是防護變可見後更容易被探測繞過,為了維持對 jailbreak 的強健性,改進 classifier 期間誤判會變多。
前兩個機制影響的是成本,第三個影響的是同一筆錢買到的能力是否一致。這些機制從外部都看不到也控制不了,同一套評測跑出來的 token 數、計費單價、甚至模型行為都可能不同,要報告一個可重現的成本數字就難了。
小編用已公布的數據回推: HLE 單項 Fable 5 花了 $2,174,是 Opus 4.8 的 1.24 倍,但這是它最省的場景; 第三方在文字生成和 agentic 評測上實測的成本是 Opus 4.8 的 2~3 倍。合起來粗估,Fable 5 跑完整套評測約要 $9,000~$11,000,約是 Opus 4.8 (max) 的 2 倍以上,已經靠近圖上 x 軸 $10k 的最右邊了。
帕雷托前緣 (Pareto frontier)
這類「智慧 vs 成本」的散點圖通稱帕雷托前緣(Pareto frontier): 把「沒有其他模型同時比它更便宜又更聰明」的模型連成一條外緣線,選模型就沿著這條線挑,線內側的模型都存在又便宜又強的替代品。下圖是 Aaron Bergman 上個月用 Artificial Analysis 數據畫的版本,虛線就是前緣。可以注意到前緣的中低價位段幾乎全是開放權重模型(藍點: Qwen、DeepSeek、MiMo),閉源模型(紅點)只守住右上角的高智慧高價端:
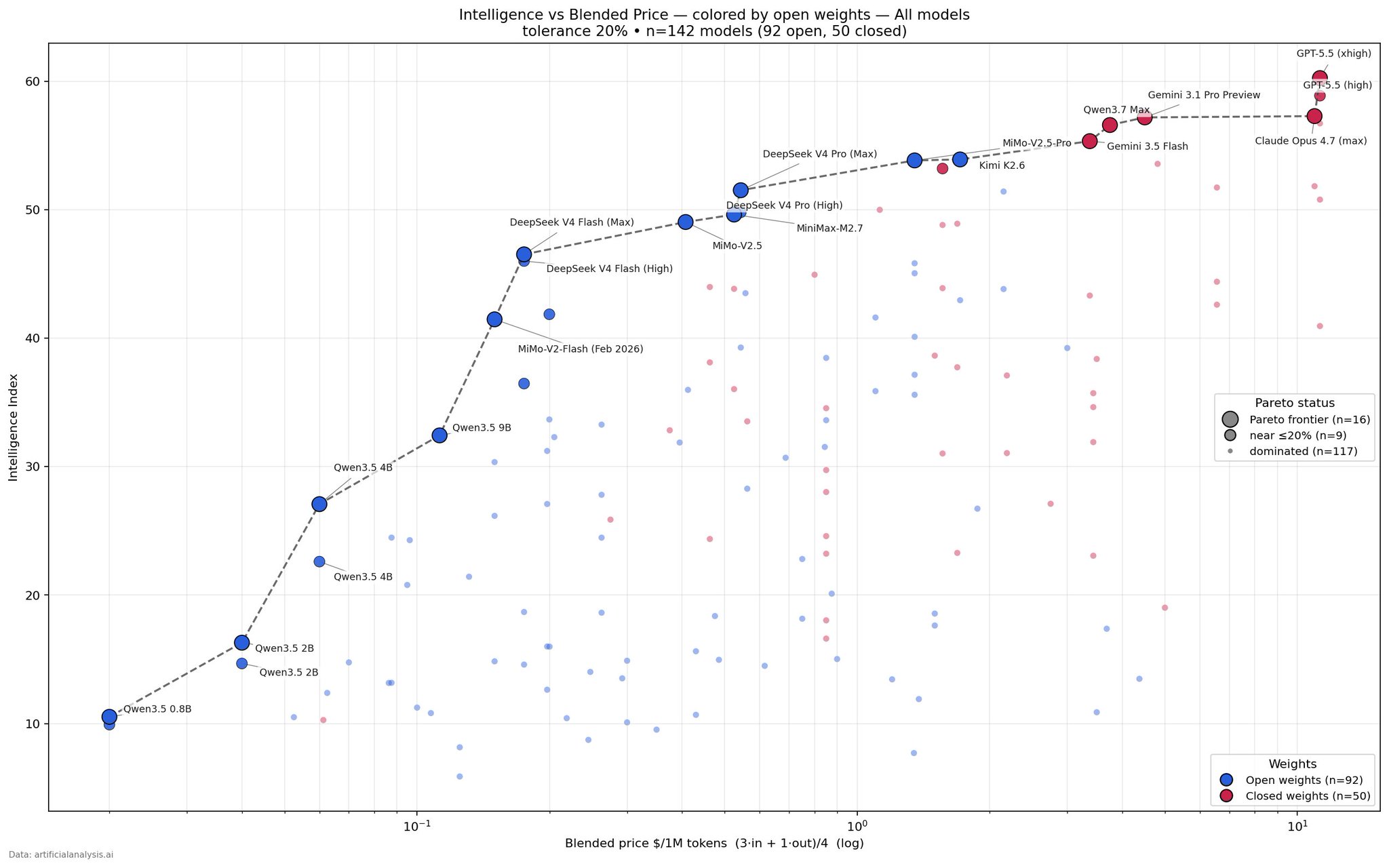
swyx 的 Latent Space 從 2024 年就開始追蹤這條前緣隨時間推移的速度,而且它移動得非常快: 根據 Epoch AI 的統計,達到固定表現水準的推論成本大約每兩個月就砍半。也就是說,今天落在前緣上的模型,幾個月後就可能被更便宜的新模型蓋過,「哪個模型最划算」的結論有效期很短,需要定期重新檢視。
拉齊預算後,推理技巧的優勢會縮水
EMNLP 2024 的 Reasoning in Token Economies 把各種推理策略放在相同的推論預算下重新評估,發現 Multi-Agent Debate、Reflexion 這些方法的優勢大幅縮水,多數情況下反而輸給簡單的基準做法 self-consistency (對同一題多次取樣再投票)。很多「新方法帶來的進步」,其實只是用了更多預算。這對評估 prompt 技巧和 agent 架構是同樣的提醒: 沒有控制預算的 A/B 比較,結論可能是錯的。
看牌價選模型也會被誤導
OckBench 發現每 token 單價只有一半的 7B 模型,因為產出 3 倍的 token 數量,實際每次查詢的成本反而貴 57%,他們稱之為「過度思考稅」(overthinking tax)。另一篇研究系統性測了 8 個推理模型在 12 種任務上的表現,發現模型兩兩比較時,有 32% 的組合牌價排序跟實際總成本排序是相反的。
小結
Noam 自己也說,這篇文章對長期追蹤的人來說沒什麼新東西: 從 2024 年 9 月 o1 發布那天起,大家就知道推理模型的表現會隨推論算力擴展。但快兩年過去,前沿實驗室發布新模型還是只報告單一數字,安全機構還是會對「鷹架架構(scaffold)用 100 倍預算打出更高分」感到意外。
對做模型選型的工程師來說,這篇的實際意義很具體: 下次比較模型時,需要考慮「在我的預算下哪一個模型最強」,而不是「誰的分數最高」。同一條曲線上的不同點,其實是不同的產品。