Claude Fable 5 的 Prompting 要點: 該刪的比該加的多
Anthropic 上個月發布了 Claude Fable 5,第一個 Mythos 級模型,定位在 Opus 之上。比較少人注意到的是,官方同時出了一份專屬的 Prompting Claude Fable 5 指南,整份文件講的就是 Fable 5 和 Opus 4.8 的行為差異,以及你的 prompt 該跟著改什麼。
小編消化了官方文件、Anthropic Claude Code 團隊成員 Thariq 的實戰長文,加上發布後這幾週社群摸索出來的共識,幫大家挑出「跟之前模型不一樣」的部分。至於 XML 標籤、few-shot 範例這些通用技巧,舊模型怎麼用、現在還是怎麼用,這篇就不重複了。
先快速交代規格,方便理解後面的建議:
- 定價: 每百萬 token 輸入 $10、輸出 $50,約是 Opus 4.8 的兩倍
- context window 有 1M token。難的任務單一請求可以跑數分鐘,自主執行可以連續數小時
- thinking 永遠開啟、只有 adaptive 模式,推理深度由
effort參數控制(low/medium/high/xhigh/max) - 內建安全分類器: 網安和生物相關請求會被拒絕,可設定自動 fallback 到 Opus 4.8。同一個底層模型、拿掉分類器的版本叫 Claude Mythos 5,只開放給核准的組織
1. 為舊模型寫的細節指令,現在會扣分
整份指南最重要的一句話,官方原文直翻: 「為先前模型開發的 skills,對 Claude Fable 5 來說往往過於規範(too prescriptive),可能降低輸出品質。」
過去官方教大家把 Claude 當成聰明但不熟悉你環境的新員工,每個步驟都要鉅細靡遺地交代。Fable 5 的指南方向不同了: 你負責講清楚目標、理由、邊界和驗收標準,步驟讓它自己規劃。那些當年為了補救舊模型規劃能力而寫的步驟清單,現在反而變成一種限制: 模型明知不適合,還是會照著做。官方還提到一個相關特性: Fable 5 很會在任務中根據學到的東西即時更新 skill 內容,寫得太死的 skill 反而妨礙這種自我修正。
Claude Code 的作者 Boris Cherny 發布當天的心得(一萬讚)正好是這件事的註腳。他說第一次意識到 Fable 不一樣,是請它 debug 的時候: 「它是我用過第一個如此有條理又精確的模型: 先量測、加 log,驗證真的修好了才宣告完成。Claude Code 的 prompt 裡沒有任何指令教模型這麼做,這就是它內建的行為。」換句話說,很多你以前要寫進 prompt 的要求,現在已經是預設值。
指令跟隨能力變強,還帶來一個紅利: 一句原則就能取代逐條列舉。官方自己的範例是,與其把每一種囉嗦的輸出模式列出來一一禁止,不如給一小段原則:
Lead with the outcome. Your first sentence after finishing should answer “what happened” or “what did you find”: the thing the user would ask for if they said “just give me the TLDR.” Supporting detail and reasoning come after.
中譯: 用成果來引導。你完成後的第一句話,就要回答「發生了什麼」或「你發現了什麼」: 也就是使用者說「直接給我重點摘要」時想要的那句話。支撐的細節和推理放在後面。
反過來說,以前那種「CRITICAL: 你必須⋯⋯」「ALWAYS/NEVER」的加重語氣,現在會造成過度觸發(overtrigger): 模型變得太聽話,你越喊,它做得越過頭。官方建議改回平常語氣,大寫強調只留給真正無例外的規則。
實務上要從哪裡開始刪? Pawel Huryn 的指南提供了一個好做法: 先讓 Fable 5 稽核你既有的 prompt 和 skills,請它找出互相矛盾的指令,以及那些為了舊模型缺陷而存在的過時規則,列出建議刪除的清單和理由,最後由你決定刪什麼。
編按: 「為舊模型調校的指令會拖累新模型」,跟之前駕馭工程系列講的 Model-Harness Fit 是同一個現象: prompt 和 harness 是針對特定模型的能力缺口設計的,模型換代之後,原本的補強就變成了限制。
2. 「Think step by step」不只沒用,還可能觸發 refusal
Fable 5 的 thinking 永遠開啟,adaptive thinking 是唯一模式: 想關掉會拿到 400 錯誤,budget_tokens 也不再支援,思考深度一律由 effort 控制。延續 4.6 世代的變更,assistant prefill(預填模型回應開頭)也不支援了,要控制輸出格式改用 structured outputs。而且不管怎麼設定,原始的思考過程(raw chain of thought)都不會回傳,只能拿到摘要版的 thinking blocks(這些 API 行為詳見官方模型介紹)。
所以「請一步一步思考」這類指令已經沒有意義,模型自己會決定何時思考、想多深。更要注意的是反效果: 要求模型「解釋你的內部推理」「展示你的思考過程」,可能觸發名為 reasoning_extraction 的拒絕分類器,整個請求會 fallback 到 Opus 4.8。官方明確建議,遷移時要逐一檢查舊的 prompt 和 skills,把這類 show-your-thinking 指令拿掉。麻煩的是,這種問題不會以錯誤的形式出現,而是表現成「fallback 比例莫名升高、輸出品質突然變差」,不容易察覺。
如果應用真的需要看到推理過程,正確做法有兩種: 讀取 thinking.display: "summarized" 回傳的摘要,或是給 agent 一個 send_to_user 工具,讓它在長任務中途,把必須原文呈現的訊息直接送到使用者面前(官方提醒,光定義這個工具還不夠,要在 system prompt 裡明確提示什麼時候用,Fable 5 才會主動去用它)。
當年 prompt engineering 就是靠「think step by step」這類技巧起家的。幾年後的今天,同一個寫法變成會觸發安全分類器,這大概是這次遷移最有時代感的一條。
3. 哪些主題會被拒絕? refusal 分類器與它的誤觸
上一節講的 reasoning_extraction 只是其中一個分類器。Fable 5 是 Mythos 級模型,能力強到 Anthropic 認為某些領域一旦被濫用風險很高,於是在模型外面加了一層安全分類器來把關。一旦請求被判定為高風險,API 會回傳 stop_reason: "refusal",並可以設定自動 fallback 到 Opus 4.8 來接手。要注意這個 refusal 是 HTTP 200 的正常回應、不是錯誤,所以程式要主動去檢查,不然它不會進到你的錯誤處理流程。
官方文件明列三類封鎖目標:
- 進攻型網路安全(offensive cybersecurity): 撰寫 exploit、惡意程式、攻擊工具這類「拿來攻破系統」的內容。相對的「防禦型」(defensive)工作,例如加固、偵測、修補漏洞,不在封鎖範圍。分界就在於這份產出是用來攻擊,還是用來防守
- 生物與生命科學: 實驗方法、分子機制這類內容
- 思考萃取(reasoning extraction): 想把模型的摘要思考掏出來,也就是上一節講的那種指令
除了這三類,Anthropic 在別的場合也提過化學和蒸餾(distillation,用大模型的輸出去訓練小模型,Anthropic 曾指控 DeepSeek 大規模這樣做)同樣在防範之列。官方講得很白: 這層防護「刻意保守」,寧可錯殺不可放過,所以正當的網安研究和有益的生命科學工作也常被掃到。他們自己給的數據是超過 95% 的 session 完全不會觸發 fallback。
麻煩的是剩下那不到 5%,而且這條界線一直在變。發布首週誤觸最誇張的是生物領域: The Verge 當時的實測發現 Fable 5 連高中程度的生物題都不肯答(「介紹一下細胞膜」「mRNA 疫苗怎麼運作」全被擋),Anthropic 也向 The Verge 證實這是刻意設定得過度保守; 做生物統計、生物資訊的研究者受害尤其無辜,Claude Code 的一個 GitHub issue 記錄到,光是 prompt 出現「spatial transcriptomics」(空間轉錄體學)或「組學」這種純學術名詞,即使整段都在講統計、沒碰任何實驗,也會被 Usage Policy 擋下(回報者還發現中文的觸發門檻更低)。官方說會持續調整、降低誤觸率,但實際邊界怎麼變、放寬了哪些,並沒有公開的對照,只能自己實測。
網安這條則有明確的收緊紀錄。7/1 Anthropic 公告在和美國政府談過後更新了網安防護,坦言「短期內新防護會比先前多擋掉一小部分無害的請求」,正在接下來幾週微調。
除了蒸餾,官方對於前研模型研究(frontier LLM development)也會封鎖,而這條發布時鬧出的風波最大。它跟網安、生物不一樣: 一開始是「隱形」的,不像其他類別會明白 fallback 到 Opus,而是默默改動或降級回應、不通知使用者。做模型評測和 AI 基礎設施的研究者最先發現不對: 答案被動了手腳卻毫無標示,等於整份 eval 的結果都不可信。挨批之後 Anthropic 公開道歉並在 6/11 改成可見的 fallback,公告原文承認「我們做了錯誤的取捨,很抱歉沒有拿捏好平衡」。據 Anthropic 自己的說法,這條分類器只在約 0.05% 的任務上觸發,主要打到的是前研規模的 LLM 資料管線、以及某些非標準晶片的 kernel 開發這類很窄的工作,一般人幾乎碰不到。這場風波的重點其實不在誤觸率,而在原則: 商用 API 如果會悄悄改變答案的內容,使用者至少該知道它被改過。
對開發者的實際意義有兩點。第一,只要工作會碰到生物、醫學、網安或前研模型研究,一定要先把 fallback 到 Opus 4.8 設定好,否則一個 refusal 就像一次沉默的失敗,你不會知道發生了什麼事。第二,如果哪天輸出品質突然變差,先懷疑是不是被 fallback 到 Opus 了,再去懷疑模型本身。官方持續在調分類器,任何「某個詞會不會被擋」的說法都有賞味期限,包括本文,實測最準。
4. effort 變成控制思考深度的唯一手段
effort 參數(low/medium/high/xhigh/max 五級)本身不是新東西,Opus 4.6 世代就有了。但在 Fable 5 上它的角色變重: 因為 thinking 關不掉、budget_tokens 也不再支援,effort 變成控制思考深度的唯一手段,負責智能、延遲、成本三者的取捨。想靠「請再仔細檢查」「think harder」這類字眼加壓的空間也變小了,模型會自己依 effort 和題目難度決定想多深。
官方的校準建議跟直覺相反: 預設用 high 就好,就算你在 Opus 4.8 上是跑 xhigh 的工作,也先從 high 開始。xhigh 留給對能力最敏感的任務,日常工作用 medium 甚至 low。原因是 Fable 5 開低 effort 的表現,常常已經超過舊模型開 xhigh,習慣性開滿只是多花錢、多等待。mvanhorn 整理的發布首日社群觀察也有實測佐證: YouTuber Web Dev Cody 發現 Fable 5 開 medium 就勝過 Opus 4.8 開 high 和 max,而且用的 token 更少。
不過高 effort 有個副作用要用 prompt 管理: 模型會蒐集超出任務所需的脈絡,或是做沒人要求的重構。官方給的範本:
Don’t add features, refactor, or introduce abstractions beyond what the task requires. A bug fix doesn’t need surrounding cleanup and a one-shot operation usually doesn’t need a helper. Don’t design for hypothetical future requirements: do the simplest thing that works well. Avoid premature abstraction and half-finished implementations. Don’t add error handling, fallbacks, or validation for scenarios that cannot happen. Trust internal code and framework guarantees. Only validate at system boundaries (user input, external APIs). Don’t use feature flags or backwards-compatibility shims when you can just change the code.
中譯: 不要加功能、不要重構、不要引入超出任務需求的抽象。修 bug 不需要順手清理周邊的程式碼,一次性的操作通常也不需要另寫輔助函式。不要為假設性的未來需求做設計: 做能把事情做好的最簡單方案。避免過早抽象和半成品的實作。不要為不可能發生的情境加錯誤處理、備援機制或驗證。信任內部程式碼和框架的保證,只在系統邊界(使用者輸入、外部 API)做驗證。能直接改程式碼,就不要用功能開關或向後相容的墊片。
5. 把最難的任務給它,並附上理由
官方遷移建議的第一條就是「先拿你手上最難的任務來試」(start at the top of your difficulty range): 挑一個以前不會考慮交給模型的難題,讓它先界定範圍、問清楚問題、再動手。官方觀察到,成效最好的團隊都是把 Fable 5 用在手上最難的未解問題,只拿簡單任務來測,會低估它的能力範圍。Thariq 在發布當天的推文也是同一個訊息: 「Fable 是模型的一次跳級(step-change),我希望它改變你和 Claude 工作的方式。重點一句話: 是時候更有企圖心了。」
Anthropic 的 Alex Albert 發布當天給新手的四點建議,可以當成本文到這裡的濃縮版:
- 給它比先前模型能處理的更大、更有企圖心的任務
- 預設用 xhigh/high effort 拿最好的表現,互動式的工作用 medium 比較快
- 重寫你的 skills 和 CLAUDE.md: 為舊模型寫的指令會把 Fable 拉回過時的模式,先讓它用自己的判斷
- 從「給任務」改成「給目標」: 描述完成長什麼樣、怎麼驗證,然後讓 Fable 自己找路(Claude Code 的
/loop和/goal就是為此設計的)
另一個新強調的原則是「給理由,不要只給請求」。當 Fable 5 知道你為什麼要做這件事,表現會明顯更好,因為它能把任務連結到相關的資訊,而不是自己猜測你的意圖。官方範本:
I’m working on [the larger task] for [who it’s for]. They need [what the output enables]. With that in mind: [request].
中譯: 我正在為 [誰] 做 [更大的任務],他們需要 [這個輸出要拿來做什麼]。基於這個脈絡: [你的請求]。
社群把這個原則推到更完整的形式。發布後流傳最廣的是 @SpikeCalls 的這個 prompt: 把你的事業交給它,不要只給 demo:
Here is my business: [what you sell, who buys it, your stack, your team size, your current bottleneck, last quarter’s numbers].
You have my context. Don’t give me generic advice. Tell me the 8 highest-leverage jobs you would take off my plate this month, ordered by expected impact. For the top one, start now: tell me exactly what data or access you need from me.
中譯: 這是我的事業: [你賣什麼、誰買、技術架構、團隊規模、目前的瓶頸、上一季的數字]。你已經有我的完整脈絡,不要給我通用建議。告訴我這個月你會從我手上接走的 8 件影響最大的工作,按預期效益排序。排第一的那件現在就開始: 告訴我你需要我提供什麼資料或權限。
6. 長時程任務的防護指令
先講清楚適用場景: 這一節整節只標 🛠️ 開發者,因為下面的範本幾乎都是放進自主 agent 的 system prompt、給「沒人在旁邊盯著、要連續跑好幾個小時」的長時程執行用的,主要是給設計自主 agent 管線的開發者。
Fable 5 的定位就是長時程自主工作,官方指南有一半篇幅在講這件事的配套。最基本的是工程面: 單一請求會跑得比以前久很多,client timeout、streaming、進度顯示都要先調整好。harness 也建議改成非同步查看進度(例如用排程檢查),而不是同步等到底。
另外,任務越模糊,Fable 5 越可能過度規劃。官方建議用這段防止它想太多:
When you have enough information to act, act. Do not re-derive facts already established in the conversation, re-litigate a decision the user has already made, or narrate options you will not pursue in user-facing messages. If you are weighing a choice, give a recommendation, not an exhaustive survey. This does not apply to thinking blocks.
中譯: 資訊足夠行動時,就行動。不要重新推導對話中已經確立的事實,不要重啟使用者已經做過的決定,也不要在給使用者的訊息裡陳述你不會採用的選項。如果你在權衡選擇,給一個建議,而不是完整的選項調查。這不適用於思考區塊。
prompt 層面還有幾個重點,這些範本設計上是放進自主 agent 的 system prompt(其中「進度聲明要有證據」「劃清評估和動手的界線」這類,放進 Claude Code 的 CLAUDE.md 也適用):
🔹 進度聲明要有證據。 長時間自主執行,最怕模型回報「都做完了」但實際沒做。官方的解法是一條指令,在官方測試中幾乎完全消除了捏造的進度報告,連刻意設計來誘發假回報的任務都擋得住:
Before reporting progress, audit each claim against a tool result from this session. Only report work you can point to evidence for; if something is not yet verified, say so explicitly. Report outcomes faithfully: if tests fail, say so with the output; if a step was skipped, say that; when something is done and verified, state it plainly without hedging.
中譯: 回報進度之前,先把每一項聲明對照本次工作階段的工具執行結果。只回報你能指出證據的工作,還沒驗證的就明說。如實回報結果: 測試失敗就照實說並附上輸出,跳過了某個步驟就說跳過了,完成且驗證過的就直接陳述,不要模稜兩可。
🔹 劃清「評估」和「動手」的界線。 Fable 5 偶爾會做沒被要求的事,例如替你起草一封沒人要的 email,或自作主張建立備份分支。官方建議明確定義界線:
When the user is describing a problem, asking a question, or thinking out loud rather than requesting a change, the deliverable is your assessment. Report your findings and stop. Don’t apply a fix until they ask for one.
中譯: 當使用者只是在描述問題、提問或思考,而不是要求修改時,你要交付的是你的評估。回報發現就停下來,對方開口才動手修。
🔹 告訴它什麼時候該停下來問你。 長時程工作需要檢查點(checkpoint),但不需要列舉每一種情況,一句原則就夠:
Pause for the user only when the work genuinely requires them: a destructive or irreversible action, a real scope change, or input that only they can provide. If you hit one of these, ask and end the turn, rather than ending on a promise.
中譯: 只有在工作真正需要使用者時才停下來: 破壞性或不可逆的動作、真正的範圍變更、或只有他們能提供的資訊。碰到這些情況就發問並結束這一輪,而不是以一句承諾作結。
🔹 防止長 session 後期提前結束。 官方提到一個少見但存在的行為: 在很長的 session 深處,Fable 5 偶爾會留下一句「我接下來會執行 X」就結束回合,沒有真的呼叫工具,或是明明資訊足夠還停下來問你要不要繼續。人在旁邊時回一句「continue」就好,自主執行的管線則建議加上這段系統提醒:
You are operating autonomously. The user is not watching in real time and cannot answer questions mid-task, so asking “Want me to…?” or “Shall I…?” will block the work. For reversible actions that follow from the original request, proceed without asking. Offering follow-ups after the task is done is fine; asking permission after already discussing with the user before doing the work is not. Before ending your turn, check your last paragraph. If it is a plan, an analysis, a question, a list of next steps, or a promise about work you have not done (“I’ll…”, “let me know when…”), do that work now with tool calls. End your turn only when the task is complete or you are blocked on input only the user can provide.
中譯: 你正在自主運作。使用者沒有即時盯著,也無法在任務中回答問題,所以問「要不要我⋯?」會讓工作停擺。對於源自原始請求、可逆的動作,直接做,不用問。任務完成後提出後續建議沒問題,但先前已經和使用者討論過、動工前又再要一次許可就不行。結束回合之前,檢查你的最後一段: 如果那是一個計畫、一段分析、一個問題、一串下一步、或一句關於你還沒做的工作的承諾(「我會⋯」「等你確認⋯」),現在就用工具呼叫把它做掉。只有在任務完成、或卡在只有使用者能提供的資訊時,才結束回合。
🔹 最終總結要寫給沒看過程的人。 跑了幾百個工具呼叫之後,Fable 5 給使用者的訊息可能充滿工作過程累積的簡寫、箭頭鏈和只有它自己懂的代號。官方建議加一段溝通風格指令,核心是:
When you write the summary at the end, drop the working shorthand. Write complete sentences. Spell out terms. Don’t use arrow chains, hyphen-stacked compounds, or labels you made up earlier. When you mention files, commits, flags, or other identifiers, give each one its own plain-language clause. Open with the outcome: one sentence on what happened or what you found. Then the supporting detail. If you have to choose between short and clear, choose clear.
中譯: 寫最後的總結時,丟掉工作過程中的簡寫。寫完整的句子,把術語講清楚。不要用箭頭鏈、連字號堆出來的複合詞、或你先前自創的代號。提到檔案、commit、旗標或其他識別符時,各自用一句白話說明。開頭先講成果: 一句話說明發生了什麼或你發現了什麼,接著才是支撐的細節。如果必須在簡短和清楚之間選一個,選清楚。
Anthropic 的 Alex Albert 也分享過同樣的困擾: Fable 在長 agentic 對話裡的產出,「有時多到我跟不上它在跟我說什麼」,他的解法同樣是一段要求寫清楚、去掉行話的 prompt 片段。
🔹 別讓它看到 context 倒數。 在很長的 session 中,如果 harness 把剩餘 token 數顯示給模型看,它可能開始提前收尾、精簡自己的工作,或建議開新 session。能藏就藏,藏不了就加一句安撫:
You have ample context remaining. Do not stop, summarize, or suggest a new session on account of context limits. Continue the work.
中譯: 你還有充足的上下文空間。不要因為上下文的限制而停止、總結、或建議開新的工作階段。繼續工作。
🔹 給它一個記憶系統。 Fable 5 很擅長利用先前執行留下的筆記,簡單到一個 markdown 資料夾就有效。Anthropic 的 Lance Martin 實測過這件事的模型差距: 有效的記憶累積有五個階段(失敗記下來、調查原因、驗證成事實、提煉成通用規則、之後直接查閱),Sonnet 4.6 停在第一階段、只會堆失敗筆記,Opus 4.7 走到第三階段,Fable 5 常能走完全程,把教訓變成幫助後續任務的規則。官方的建議寫法:
Store one lesson per file with a one-line summary at the top. Record corrections and confirmed approaches alike, including why they mattered. Don’t save what the repo or chat history already records; update an existing note rather than creating a duplicate; delete notes that turn out to be wrong.
中譯: 一個教訓存一個檔案,開頭放一行摘要。更正和驗證過的做法都要記,包括它們為什麼重要。程式碼庫或對話紀錄已經有的就不要存,更新既有筆記而不是建立重複的,發現筆記是錯的就刪掉。
官方還建議這樣啟動記憶系統,把過去的對話變成第一批筆記:
Reflect on the previous sessions we’ve had together. Use subagents to identify core themes and lessons, and store them in [X]. Make sure you know to reference [X] for future use.
中譯: 回顧我們先前的幾次工作階段,用子代理人找出核心主題和教訓,存到 [X]。之後記得參考 [X]。
🔹 多用 subagent,驗證交給乾淨 context 的 subagent。 Fable 5 比先前模型更會主動派出並行的子代理人(subagent),官方建議多用,而且採用非同步的溝通方式:
Delegate independent subtasks to subagents and keep working while they run. Intervene if a subagent goes off track or is missing relevant context.
中譯: 把獨立的子任務分派給子代理人,在它們執行的同時繼續你的工作。如果某個子代理人偏離方向或缺少相關脈絡,就介入處理。
驗證工作尤其適合: 官方指出,用乾淨 context 的驗證者 subagent 對照規格檢查,效果傾向優於模型的自我檢查(模型批改自己的輸出有已知的弱點)。Lance Martin 也實測過這種「給目標和評分準則、讓模型自我修正、由獨立 subagent 驗證」的迴圈: 在一個 ML 工程挑戰上跑 8 小時,Fable 5 對訓練管線的改善幅度約是 Opus 4.7 的 6 倍,而且 Opus 幾乎只做「調一個常數、量測、有效就留下」的小步實驗,Fable 會做結構性的改動。長時程任務可以這樣寫:
Establish a method for checking your own work at an interval of [X] as you build. Run this every [X interval], verifying your work with subagents against the specification.
中譯: 建立一套在建置過程中每隔 [X] 檢查自己工作的方法。每 [X 間隔] 執行一次,用子代理人對照規格驗證你的工作。
社群摸索出的分工模式也類似: Fable 負責規劃和把關,建置交給 Sonnet,測試交給 Haiku,讓成本較低的模型消化大量的執行工作。
7. Thariq 的 Field Guide: 品質瓶頸變成「你的 unknowns」
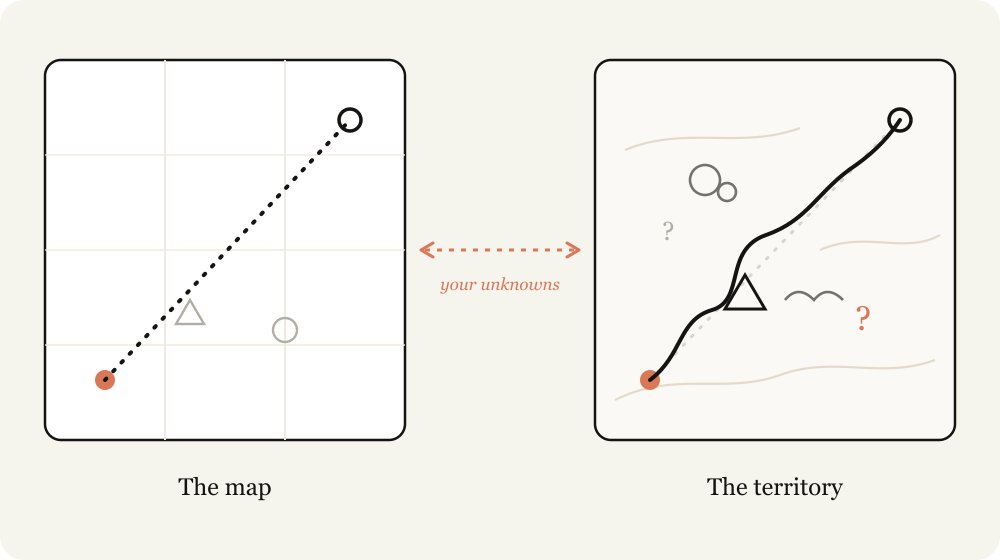
官方文件之外,最值得讀的是 Claude Code 團隊成員 Thariq 今天發表的 A Field Guide to Fable: Finding Your Unknowns。他用「地圖與疆域」開場(也就是本文的封面圖): prompt、skills、context 是你給 Claude 的地圖,codebase 和真實世界的限制才是實際的疆域,兩者之間的落差就是「unknowns」。模型碰到 unknown 時,只能根據「它猜你想要什麼」做決定,而做的工作越多,碰到的 unknowns 就越多。
他的核心觀察直翻是: 「Fable 是第一個讓我覺得,工作品質的瓶頸在於我能不能釐清它的 unknowns 的模型。」也就是說,模型能力不再是限制,限制在人這一端。
他也點出下指令的兩難,正好呼應第 1 節: 太具體,Claude 會在該轉向的時候仍照著你的指令走; 太模糊,它會用業界通用的做法來填空,不見得適合你的情境。所以最重要的是把你的起點交代清楚: 你在思考過程的哪個階段、對這個問題和這個程式碼庫的經驗多深,讓 Claude 像思考夥伴(thought partner)一樣跟你一起工作。他把 unknowns 拆成四類:

- Known knowns: 你寫進 prompt 的東西
- Known unknowns: 你知道自己還沒想清楚的部分
- Unknown knowns: 顯而易見到你不會特地寫下來,但看到成品就能認出對錯的標準
- Unknown unknowns: 你根本沒考慮過的事,包括「你不知道這件事可以做到多好」
對應的做法,他整理成實作前、中、後三組。共同精神是: 用很小的成本,把 unknowns 提前找出來。順帶一提,這些技巧的產出物(原型、計畫、報告),他幾乎都用 HTML artifact 呈現,這是他一貫的主張: 「HTML is the new markdown」,與其寫 markdown 文件,不如讓 Claude 直接生成可互動的 HTML 頁面。
實作前
Blindspot pass: 在不熟的領域開工前,直接用「blindspot pass」「unknown unknowns」這些字眼請 Claude 幫你補課。例如:
I’m working on adding a new auth provider but I know nothing about the auth modules in this codebase. Can you do a blindspot pass to help me figure out my relevant unknown unknowns and help me prompt you better.
中譯: 我要加一個新的身分驗證供應商,但我對這個程式碼庫的身分驗證模組一無所知。幫我做一次盲點掃描,找出那些我該知道、卻不知道自己不知道的事,讓我能把 prompt 下得更好。
腦力激盪: Thariq 幾乎每個 coding session 都從探索或腦力激盪開始,幫助界定專案範圍,Claude 常會找到他沒想到的高價值做法:
Here’s my rough problem: users churn after onboarding. Search the codebase and brainstorm 10 places we could intervene, from cheapest to most ambitious. I’ll tell you which ones resonate.
中譯: 我的問題大致是: 使用者在新手引導之後流失。搜尋程式碼庫,腦力激盪出 10 個我們可以介入的地方,從成本最低排到最有企圖心。我會告訴你哪些方向讓我有感。
原型: 針對「看到才知道要不要」的 unknown knowns,先要 HTML 原型,不要直接完整實作。在原型階段發現要改,比在實作深處發現便宜太多:
Before wiring anything up, make a single HTML file mocking the new editor toolbar with fake data. I want to react to the layout before you touch the real app.
中譯: 先不要接任何後端,做一個單一 HTML 檔,用假資料模擬新的編輯器工具列。我想先對版面配置有反應,你再去動真正的應用程式。
視覺設計這種難以言傳的需求,可以一次要多個方向:
I want a dashboard for this data but I have no visual taste and don’t know what’s possible. Make me an HTML page with 4 wildly different design directions so I can react to them.
中譯: 我想為這些資料做一個儀表板,但我沒有視覺品味,也不知道有哪些可能性。做一個 HTML 頁面,放上 4 個截然不同的設計方向,讓我可以看了表達意見。
訪談: 腦力激盪完還有 unknowns 的話,換 Claude 來問你:
Interview me one question at a time about anything ambiguous, prioritize questions where my answer would change the architecture.
中譯: 一次問我一個問題,針對模糊的地方訪談我,優先問那些我的答案會改變架構的問題。
參考資料給原始碼: 講不清楚要什麼的時候,最好的參考資料是程式碼本身,跨語言也沒關係:
This Rust crate in vendor/rate-limiter implements the exact backoff behavior I want. Read it and reimplement the same semantics in our TypeScript API client.
中譯: vendor/rate-limiter 這個 Rust 套件實作了我要的退避(backoff)行為。讀懂它,然後在我們的 TypeScript API 客戶端重新實作同樣的語意。
實作計畫把「你最可能改的」放前面: 讓 Claude 把你最需要看的決策排在計畫的最前面,機械性的部分沉到最後:
Write an implementation plan in HTML, but lead with the decisions I’m most likely to tweak: data model changes, new type interfaces, and anything user-facing. Bury the mechanical refactoring at the bottom, I trust you on that part.
中譯: 寫一份實作計畫(用 HTML),把我最可能調整的決策放最前面: 資料模型的變更、新的型別介面、使用者看得到的部分。機械性的重構放最後,那部分我信任你。
實作中
再完整的計畫,實作途中還是會碰到新的 unknowns。Thariq 的做法是請 Claude 邊做邊記錄,這些紀錄會成為下一次規劃的輸入:
Keep an implementation-notes.md file. If you hit an edge case that forces you to deviate from the plan, pick the conservative option, log it under ‘Deviations’, and keep going.
中譯: 維護一份 implementation-notes.md。遇到迫使你偏離計畫的邊角情況,就選保守的做法,記錄在「Deviations」(偏離)段落底下,然後繼續前進。
這個做法他五月就分享過更完整的版本(9,700+ 讚):
implement
<SPEC>and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren’t in the spec, things you had to change, tradeoffs you had to make or anything else I should know中譯: 實作
<SPEC>,過程中持續維護一份 implementation-notes.html(或 markdown),記錄規格裡沒寫、但你必須做的決定,你不得不改的東西,你做的取捨,以及任何其他我該知道的事。
實作後
打包成給別人看的說明文件: 出貨前常要爭取關係人的理解和核准。審核者一開始的 unknowns 跟你當初一樣多,一份好的說明文件能加速理解,也讓專家看到你考慮過他們會問的問題:
Package the prototype, the spec, and the implementation notes into a single doc I can drop in Slack to get buy-in. Lead with the demo GIF.
中譯: 把原型、規格和實作筆記打包成一份文件,讓我可以直接貼到 Slack 爭取支持。開頭放展示用的 GIF 動圖。
請 Claude 出題考你: 只讀 diff 只能看懂表面,很多行為藏在既有的程式路徑裡:
I want to make sure I understand everything that’s happened in this change. Give me a HTML report on the changes for me to read and understand with context, intuition, what was done, etc. and a quiz at the bottom on the changes that I must pass.
中譯: 我想確認自己完全理解這次變更發生了什麼。給我一份這次變更的 HTML 報告,附上脈絡、背後的直覺、做了什麼等等,最後放一份關於這次變更、我必須通過的測驗。
Thariq 的標準是測驗全對才 merge。
文章最後他舉了自己的例子: Fable 5 的發布影片就是他用 Claude Code 剪的,而影片剪輯對他是全新領域(他有拍一支影片說明整個過程: Claude 寫程式呼叫轉錄服務、ffmpeg、Figma MCP,用 Remotion 做動態字卡再算圖,他全程沒開過剪輯軟體)。碰到畫面色調偏灰,他知道問題出在調色(color grading),但不懂那是什麼。第一反應是讓 Claude 做幾個版本來挑,後來發現自己連「好的調色長什麼樣」都不知道,於是改請 Claude 先教他,把 unknown 變成 known 之後才動工:
I don’t know what color grading is but I need to grade this video. Can you teach me to understand my unknown unknowns about color grading, so that I can prompt better?
中譯: 我不知道調色是什麼,但我需要為這部影片調色。你能教我理解自己在調色上「不知道自己不知道」的部分,讓我能下更好的 prompt 嗎?
小結
把這些放在一起看: Fable 5 的 prompt 本身變短了,但要做的事沒有變少,只是內容變了。從控制模型的每一步,變成定義目標、理由、邊界和驗證方式,設計能自我修正的迴圈,再加上 Thariq 說的,持續釐清你自己的 unknowns。官方指南裡的那些範本與其照抄,不如拿你自己流量最大的 prompt 和 skills 做 A/B 對照,親自驗證「刪掉之後有沒有變好」。
下一個專案開工前,可以先試試 Thariq 的建議: 請 Claude 幫你找出「你不知道自己不知道」的事。
參考資料
官方文件:
- Claude Fable 5 and Claude Mythos 5 發布公告 (Anthropic, 2026/6/9)
- Prompting Claude Fable 5 (官方 prompting 指南,本文的主要依據)
- Claude prompting best practices (跨模型通用的 prompting 建議)
- Introducing Claude Fable 5 and Claude Mythos 5 (API 變更、定價與可用性)
Anthropic 成員的分享:
- A Field Guide to Fable: Finding Your Unknowns (Thariq, 2026/7/4)
- 用 Claude Code 剪輯 Fable 5 發布影片的過程說明 (Thariq, 2026/6/10)
- implementation-notes 的原始 prompt (Thariq, 2026/5/18)
- HTML is the new markdown (Thariq, 2026/5/8)
- Fable 發布日推文: 是時候更有企圖心了 (Thariq, 2026/6/9)
- Designing loops with Fable 5 (Lance Martin, 2026/6/9)
- Fable 5 發布心得: 從 coding agent 變成思考與設計夥伴 (Boris Cherny, 2026/6/9)
- 使用 Fable 的四點建議 (Alex Albert, 2026/6/9)
- 讓 Fable 長對話輸出保持清楚的 prompt 片段 (Alex Albert, 2026/6/12)
關於 refusal 分類器與誤觸:
- Claude Fable won’t answer basic biology questions (The Verge, 2026/6/10,記錄發布首週的生物誤觸)
- Fable 5 bio classifier blocks innocuous academic statistics terms (Claude Code GitHub issue)
- Anthropic 為前研模型研究的隱形防護道歉、改成可見 fallback (@ClaudeDevs, 2026/6/11)
- Anthropic 公告在和美國政府談過後收緊網安防護 (@claudeai, 2026/7/1)
社群:
- /Last1Day of Fable 5: Best Practices and the Funniest Things People Are Saying (mvanhorn, 2026/6/11)
- 描述你的事業、請 Fable 找出高效益工作的 prompt (@SpikeCalls, 2026/6/10)
- Claude Fable 5: The Ultimate Guide for PMs (Pawel Huryn, 2026/6/11)