從 Code Act 到 Claude Code Dynamic Workflows 深度技術解析
Claude Code 上週發表 dynamic workflows (官方文件),大家第一反應大多是「終於能一次跑幾百個 sub-agent 了」。這當然很猛,但小編覺得更值得講的,是它背後那條技術脈絡: 從 2024 年初的 Code Act 一路長出來的。
把這條線拉開來看,dynamic workflows 不是憑空冒出來的新玩意,而是「用程式碼當 agent 的行動」這個老想法,走到成熟、產品化的一步。技術上小編覺得設計得非常漂亮,這篇就來把這條路從頭走一遍。
1. Code Act 的核心洞見: 用程式碼當行動空間
故事從 “Executable Code Actions Elicit Better LLM Agents” (2024/2) 這篇講起。傳統 agent 的做法是 JSON function calling: 模型吐一個 JSON 物件,描述要呼叫哪個工具、帶哪些參數,再交給後端的處理常式執行,把結果塞回去。
CodeAct 提出的轉向是: 不要用預先定義好的 JSON 格式當行動空間,而是直接讓 LLM 寫一段「可執行的 Python」當作它的行動,把規劃跟工具呼叫合併進同一份程式碼裡一起跑。
為什麼程式碼會比 JSON 好? 兩個關鍵理由:
🔹 模型本來就很會寫程式碼。 LLM 在訓練時看過幾百萬個開源專案的真實程式碼,但工具呼叫用的那些特殊 token,是靠合成資料硬訓出來的,模型在真實世界裡根本沒見過。
🔹 程式碼天生支援組合。 迴圈、條件判斷、變數傳遞、把好幾個工具的輸出串起來,這些在 JSON schema 裡很難表達,在 Python 裡卻幾乎不費力。
論文 Figure 1 那個例子舉得很漂亮。任務是在美國、日本、德國、印度裡,找出買「CodeAct」這支手機最划算的國家。每個國家都得查匯率、稅率、當地售價、運費,再算出最終美元價格。用到的工具有 lookup_rate、lookup_phone_price、convert_and_tax、lookup_shipping_cost、estimate_final_price。
兩種做法的差異:
左邊每呼叫一個工具,結果都得塞回模型,模型再決定下一步,一路來回。右邊一個 for 迴圈跑完四國,lookup_rate 的輸出直接傳給 convert_and_tax (資料流),最後用 Python 內建的 min() 挑出最便宜的。模型只需要產生這一段程式碼、看一次最終答案。
CodeAct 的一個具體實作是 Hugging Face 的 smolagents,裡面的 CodeAgent 就是讓模型寫 Python 來呼叫工具,而不是走 JSON function calling。
這裡有個容易混淆的點: CodeAct 跟 Code Interpreter 不一樣。Code Interpreter 只是把「跑程式碼」當成眾多工具裡的「一個工具」來用,程式碼本身碰不到 agent 的其他工具。
CodeAct 則是把整個決策過程,連同函式呼叫,都寫進同一份程式碼裡一起執行。少了中間來回,效率自然好。
2. 同一招用到 MCP 上: Cloudflare 自家的 Code Mode
時間快轉到 MCP 生態爆炸之後,出現一個很現實的問題: 工具太多了。每個操作都註冊成一個工具,幾千個工具定義直接塞爆上下文。
Cloudflare 的 Code Mode 參考了 CodeAct 的思路: 與其把每個操作描述成獨立的工具,不如把 MCP 工具轉成一份有型別的 TypeScript SDK,叫模型寫程式碼去呼叫。他們新的 Cloudflare MCP server 涵蓋整個 Cloudflare API (數千個端點),只定義兩個 agent 工具: search() 跟 execute()。
這樣大約只吃 1000 個 token,同樣的東西若用傳統「每個端點一個工具」的做法,要 117 萬 token,直接超過大多數模型的 context window。search() 讓模型去查 OpenAPI 規格、把幾千個端點收斂到需要的那幾個,execute() 在沙箱裡跑實際呼叫。
這裡有個概念叫「composition tax」(組合稅): 每一次工具呼叫的結果,都得先塞回模型的神經網路,再被原封不動抄到下一個呼叫的輸入,白白浪費 token 跟延遲,還多出一次推理。動作越多,這個稅越重。寫成程式碼就能在執行環境裡直接串接,跳過這道稅。
3. 程式碼可呼叫 agent tools: PTC
接著是 Claude API 這邊的 Programmatic Tool Calling (PTC),它建在 code_execution 工具之上 (這就是 Claude 的 Code Interpreter)。作法很單純: 你照常定義自訂工具,只要在工具定義裡加一個 allowed_callers: ["code_execution_20260120"],Claude 就不會一個一個直接呼叫它們,而是寫一段 Python,把這些工具當成函式,在程式碼執行容器裡組合、執行。
一句話抓住定位: PTC 就是「一段在容器裡執行的程式碼,而且這段程式碼能呼叫你原本要給 agent 的那些工具」。對照前面: Code Interpreter 的程式碼只能在沙箱裡自己算,碰不到 agent 的工具; CodeAct 在研究層面做到了讓程式碼呼叫 agent 工具。PTC 的升級是把這件事變成正式上線的 API,附帶的好處是: 工具的執行留在你那邊,工具結果不進 Claude 的上下文。
機制拆開來看是這樣:
- Claude 在 Anthropic 的容器裡寫一段程式碼,裡面可能有迴圈、條件判斷、好幾個工具呼叫。
- 程式碼跑到
result = await query_db(sql)時,容器暫停,API 把這個呼叫當成一個tool_use事件回傳給「你」。 - 工具還是跑在你那邊: 你的伺服器執行它、把結果回傳,Anthropic 的容器只負責跑那段編排程式碼。
- 結果回到「正在執行的那段程式碼」繼續往下,這些中間結果完全不進 Claude 的 context window (也不計入 token)。
- 整段程式碼跑完,Claude 只收到最後印出來的 stdout。
編按: 這正好補上 composition tax 的另一半。Code Mode 解決了「工具定義」塞爆上下文,PTC 解決的是「工具結果」塞爆上下文。例如一次搜尋回傳 50 筆原始結果,程式碼可以在容器裡直接解析、過濾、交叉比對,只留下相關的幾筆,而不是把 50 筆全倒進 Claude 腦袋裡讓它自己讀。
所以 PTC 做到的是: Claude 用程式碼組合多個工具呼叫 (迴圈、條件、串接輸出),但工具還是跑在你那邊,你可以檢查、拒絕、記 log、排進人工審核佇列。
但官方也講得很白,PTC 不是萬靈丹。嚴格循序、每一步都要 Claude 看完上一步才能決定下一步的工作,PTC 幫不上忙 (那種情況本來就省不掉來回),一次只呼叫一兩個工具的場景甚至會小貴一點。它真正發威的是「大量平行分流」或「結果很大、可以先在程式碼裡過濾」的任務。
(另外有個常見誤會: MCP connector 提供的工具,目前不能被 PTC 程式化呼叫。)
4. 開源實作: LangChain Deep Agents 的 Interpreter 與 Interpreter Skills
LangChain 的 Deep Agents 做的 interpreter,跟剛剛的 PTC 骨子裡是同一套做法,只是搬到了不同的層。PTC 是 Anthropic 在 API 供應商這一層做的 (Anthropic 管容器,工具在你那邊執行); Deep Agents Interpreter 則是 LangChain 在 harness 層做的中介層 (middleware),跟模型無關,連開源模型都能用。LangChain 自己也說 PTC、Code Mode、interpreter、RLM 殊途同歸。
具體來說,它給 agent 一個內嵌的小型執行環境,agent 可以在裡面寫程式碼、存變數、定義輔助函式、跨呼叫保留狀態,像有了一個 Python 或 Node REPL。實作上它是掛一個 eval 工具,但別被「工具」兩個字誤導: 它背後是一個有狀態、會跨呼叫存活的執行環境,不是那種呼叫一次就結束的普通工具。
小編初看時覺得這跟 sandbox 功能有什麼差別? 其實差在兩個地方:
🔸 預設能力的方向相反。 沙箱是「先給一台電腦,再往下收」: agent 一開始就拿到完整的作業系統、檔案系統、網路、shell,你再去限制。interpreter 剛好倒過來,「先什麼都沒有,要什麼再明確給」: 預設只有一個語言執行環境,沒有檔案系統、沒有網路、沒有 shell,連讀檔、抓網頁、開子代理人(spawn sub-agent) 都得一個一個透過 allowlist 橋接進來。
🔸 隔離在不同的層。 這也回答一個常見疑問: 「interpreter 不也是在沙箱裡跑程式碼嗎?」其實不一定。interpreter 底層是像 QuickJS 這種內嵌的小引擎,跟 harness 跑在同一個行程裡,它的「隔離」是語言層的: 執行環境預設沒綁任何主機 API,所以裡面的程式碼根本沒有東西可以濫用。真正的沙箱 (gVisor、microVM 那種) 則是作業系統或硬體層的隔離,目的是擋住 agent 自己生成、可能亂來的程式碼「逃逸」。一句話: 能力控管 (capability scoping) 防的是「能碰到什麼」,VM 隔離防的是「會不會逃出去」,是兩回事。跑不可信的程式碼時,你還是可以把整個 interpreter 再包進一個沙箱,那是多加的一層防禦,不是 interpreter 自帶的機制。
PTC 跟 Deep Agents Interpreter 共同做到的關鍵動作是: 一旦把 Task 或 agent 工具也橋接進來,程式碼就能開子代理人。程式碼從「呼叫工具」升級成「呼叫 agent」,正式參與了 agent loop。
LangChain 後來進一步做了 interpreter skills: 開發者事先把一段「已知有效的固定流程」寫成 TypeScript 模組,註冊成一個 skill。模型在對話中判斷「現在該用哪個 skill、傳什麼輸入」,但 skill 內部的步驟是寫死的程式碼,不是模型即時決定的。
拿他們的 GitHub repo triage 範例來看,一個 interpreter skill 由 SKILL.md (告訴模型什麼時候該用) 和 index.ts (實際的流程程式碼) 組成。當使用者說「幫我整理這個 repo 的 issue」,模型判斷該用這個 skill,在 interpreter 裡呼叫它:
// skills/github-triage/SKILL.md 告訴模型: "Use this skill when a user asks for repository triage."
// skills/github-triage/index.ts 匯出 triage() 函式,內部流程是寫死的:
// 抓所有 open items → 開子代理人做摘要 → 逐一分群歸類
const { triage } = await import("@/skills/github-triage");
const result = await triage("langchain-ai/deepagents", {
issues: true, prs: true, discussions: true,
});
result.toMarkdown();
模型決定的是「要不要用、傳什麼參數、結果怎麼處理」; 但 triage() 內部怎麼抓資料、怎麼開子代理人、怎麼分群,全是寫死在 index.ts 裡的確定性程式碼。
這跟 Claude Code dynamic workflows 已經非常接近了,差別是 interpreter skills 由開發者事先寫好,而 dynamic workflows 是模型在接到任務時才即時生成那份編排腳本。
這套設計背後的理論支點: RLM
dynamic workflows 不只是工程上的巧思,它底下有一條清楚的研究脈絡撐著,叫 RLM (Recursive Language Models)。
這是 MIT 的 Alex Zhang、Tim Kraska、Omar Khattab 提出的框架 (2025 年 10 月先以部落格形式提出,年底發表論文)。核心想法是: 把整段 prompt 當成一個放在 REPL 裡的「外部物件」。主模型不把上下文一口氣吞進腦袋,而是寫程式碼去窺看它、拆解它,對其中的片段遞迴呼叫自己或子模型,中間結果留在 REPL 的變數裡,只有精簡過的結果才回到主模型。這樣就繞過了固定 context window 的天花板。
關鍵在於 RLM 長期主張、而 coding agent 一直缺的那個能力: 以程式化的方式呼叫 sub-agent,把它們的輸出在程式碼裡傳來傳去,而不經過主模型的上下文。 這正是 dynamic workflows 在做的事。
也因此,RLM 作者群直接認領了這個發表: Omar Khattab 說「Claude Code 終於是一個 RLM 了」; Alex Zhang 則認為 Opus 4.8 加上 dynamic workflows,大概是第一個被認真訓練成 RLM 的前沿模型實例。
Dynamic workflows 的設計跟 RLM 的主張高度吻合: 模型寫的那段 JS 裡,agent() 就是在遞迴開子代理人,而編排這層是決定性的。
5. Claude Code Dynamic Workflows
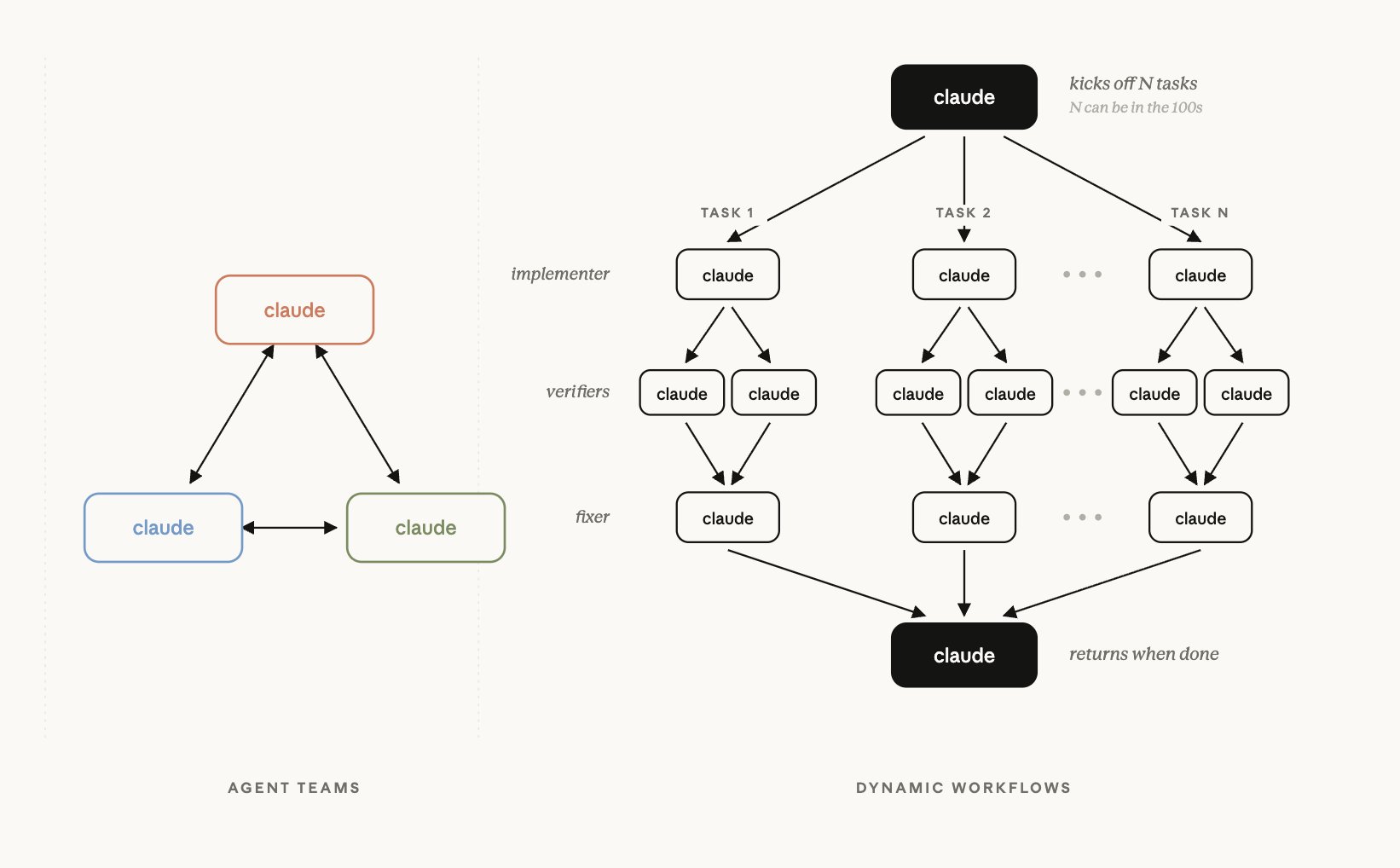
終於來講到本篇的主角 Claude Code dynamic workflows 了,一樣是讓模型寫程式碼去編排 sub-agent。模型即時寫出程式碼這件事,跟 PTC、Deep Agents Interpreter 並沒有不同。真正不一樣的,是把這套編排磨硬、做成產品: 編排腳本可以中斷後原地 resume,而且是決定性的 (第 8 節會講); 規模一次拉到上千個 sub-agent; 在背景獨立跑完才把結果交回對話; 還收斂成六種可互相組合的模式、能存檔重用。前面那幾種都沒有這層「可重播、可規模化」的保證。
實際操作時,你在 prompt 裡帶一個 workflow (或 ultracode),Claude 就會即時寫出一份 JavaScript 編排腳本,用 agent()、parallel()、pipeline()、phase() 這些函式 (官方文件),平行啟動一大批 sub-agent (同時最多 16 個,單次最多 1000 個),跑完再把結果交回來。
借用 Voxyz 那篇文章的講法: 計畫從對話的上下文搬進了可執行腳本。 以前用 Claude Code 跑大任務,所有步驟都擠在同一個對話上下文裡: 做完一步、等結果、決定下一步、再等結果。任務越複雜,上下文本身反而變成瓶頸,卡住的從來不是「誰來做」,而是「誰記得整個計畫」。dynamic workflows 把計畫從對話裡抽出來: 迴圈、分支、中間狀態、審查鏈、重試,全都在腳本裡跑,主對話只收到最後的摘要。
官方那篇 “A harness for every task” 非常推薦一讀,把「為什麼需要這個」講得很清楚。當 Claude 在單一 context window 裡又要規劃又要執行,跑久了會出現三種失敗模式:
1️⃣ Agentic laziness (偷懶): 複雜的多步任務做到一半就宣告完成,例如 50 項的安全檢查只做了 20 項就說好了。
2️⃣ Self-preferential bias (偏袒自己): Claude 傾向偏好自己產出的結果,叫它對照評分準則自我審查時,這個偏差特別明顯。
3️⃣ Goal drift (目標漂移): 多輪之後,尤其每次 compaction 都是有損壓縮,「不要做 X」這種邊界約束會慢慢被弄丟。
把任務拆給各自擁有獨立、乾淨上下文的多個 Claude,從結構上就避開這三個坑。
編按: 這三個失敗模式雖然是 Anthropic 自己歸納的,但跟學界的觀察高度吻合。Berkeley 那篇 《Why Do Multi-Agent LLM Systems Fail?》 (MAST) 分析了 1600 多份多 agent 系統的失敗軌跡,歸納出 14 種失敗模式,其中很大一塊正是「驗證不足」跟「提早收工」: 沒有獨立的把關者、任務沒做完就被宣告完成。dynamic workflows 用獨立上下文的 agent 配上對抗式驗證,剛好是針對這類失敗的結構性解法。
最有名的案例是 Bun 從 Zig 改寫成 Rust: 約 75 萬行 Rust、99.8% 既有測試通過、從第一個 commit 到 merge 只花 11 天,靠的就是把任務切成「map → generate → review → verify → fix loop → cleanup」的流水線。
從 Code Interpreter 到 Dynamic Workflows,雖然都是「讓 LLM 輸出程式碼來執行」,但真正分出差異的是: 那段生成的程式碼,被准許呼叫什麼、又被限制成什麼。
✏️ 小編製圖
Code Interpreter 什麼都能寫,但程式碼碰不到 agent 的工具,等於站在 agent loop 外面。CodeAct 的關鍵一步,是讓程式碼呼叫 agent 的工具,把程式碼拉進 loop 裡。之後每個階段的設計取捨不同: Code Mode 框在一套 SDK 裡; PTC 跟 Deep Agents Interpreter 用 allowlist 決定能碰哪些工具跟 agent; Dynamic Workflows 則把程式碼限制在「編排」這一件事,不能直接碰檔案、shell、網路 (那些都丟給 sub-agent),連時間跟亂數都被禁掉,換來的是 resume 跟決定性。
表格裡另一個值得注意的差異: 程式碼呼叫的是「死的函式」,還是「會自己推理的 sub-agent」。 原始 CodeAct 論文裡,程式碼呼叫的工具都是 lookup_rate 這種固定函式: 你可以用迴圈、條件去串它們的輸出,但函式本身不會思考。
不過嚴格講,CodeAct 這條線本身就能開子代理人,只要塞進去的那個「工具」其實是一個 agent 就行。Hugging Face 的 smolagents 早就做到了: 你給一個 agent 設好 name 跟 description,當成 managed_agents 交給一個 manager CodeAgent,manager 生成的 Python 就能把它當函式呼叫。官方範例裡,一個 manager 指揮底下的 web_search_agent 查資料,自己負責規劃跟計算。所以表格裡 CodeAct 那格的 ✗,與其說是「技術上做不到」,不如說是「原論文沒往這個方向想,生態也還沒把 sub-agent 編排當成主軸」。
PTC 跟 Deep Agents Interpreter 帶出的重點是「程式碼能呼叫 agent tools」,雖然 tool 裡面也可以包一個 sub-agent,但這不是它們強調的用法。程式碼可以用迴圈、條件去組合多個工具呼叫,中間結果留在程式碼裡不必繞回主模型的上下文,後一個工具的輸入還可以拿前一個的結果在程式碼裡算出來 (a = await tool(...); b = await tool(transform(a))),不必一開始就把所有參數寫死。
真正把 sub-agent 編排當成核心的,是 RLM 的研究和 Dynamic Workflows。RLM 一路主張的就是「以程式化的方式呼叫 sub-agent,把輸出在程式碼裡傳遞,而不經過主模型的上下文」。到了 Dynamic Workflows,開子代理人變成程式碼唯一在做的事,還補上了 resume、可重播、決定性這些硬保證。
表格裡那條 ✗✗✗✓✓ 的分界,標的不是「技術上能不能開子代理人」(CodeAct 透過 smolagents 也做得到),而是「有沒有把 sub-agent 編排當成一等公民,再用產品級保證撐住」。
PTC / Deep Agents Interpreter 跟 Dynamic Workflows 都能 spawn、也都能分階段,差別不在「能不能」,而在編排層被磨得多硬。Dynamic Workflows 多了 parallel/pipeline/phase 這些原語,可中斷後 resume,還有禁時間亂數換來的決定性; PTC / Deep Agents Interpreter 則更通用、也更鬆,少了這些硬保證。
Dynamic Workflows 把程式碼的角色限制在編排,再用六種固定模式把編排本身也標準化。限制換來的是能 resume、能重播、結果可預期。
六種可以互相組合的編排模式
“A harness for every task” 這篇把常見的編排手法整理成六種,實際用時常常會疊在一起:
1️⃣ 分類並執行 (classify-and-act): 先用一個分類 agent 判斷任務屬於哪一型,再依結果路由到不同的 agent 或行為。也可以反過來放在最後,用分類器決定要輸出什麼。
2️⃣ 分流並整合 (fan-out-and-synthesize): 把任務拆成很多小步,每步開一個 agent,最後再把結果整合起來。適合步驟很多、或每步都需要自己乾淨上下文以免互相干擾的情況。整合那一步是個同步點 (barrier): 它會等所有分流的 agent 都跑完,再把它們的結構化輸出併成一份結果。
3️⃣ 對抗式驗證 (adversarial verification): 每開一個 agent 產出結果,就另外開一個 agent,專門拿評分準則或標準去「反駁」它的輸出。
4️⃣ 生成並篩選 (generate-and-filter): 針對一個主題先生成一堆點子,再用評分準則或驗證去篩,去掉重複的,只留下品質最高、通過檢驗的那幾個。
5️⃣ 錦標賽 (tournament): 不是分工,而是讓 agent 互相競爭。開 N 個 agent 用不同方法各做同一件事,再用一個評審 agent 兩兩比較、淘汰,直到選出贏家。
6️⃣ 直到完成為止持續迴圈 (loop until done): 對「工作量未知」的任務,不要設固定回合數,而是一直開 agent 直到觸發停止條件 (沒有新發現、或 log 裡不再有錯誤) 為止。
6. 更多精彩用法: 它不只拿來寫程式
官方那篇文章裡,小編覺得最有啟發的反而是作者一句話: workflows 用在「非寫程式」的任務上,往往更有威力。挑幾個他給的實際 prompt 範例 (已翻成中文),順手標出背後用到的模式:
🔹 抓 1/50 機率的 flaky test: 「這個測試大概每 50 次會失敗 1 次。開一個 workflow 重現它,提出幾個假設、在各自的 worktree 裡對抗式地驗證,/goal 設定: 不到有一個假設成立不准停。」(loop-until-done + 對抗式驗證 + 根本原因調查)
🔹 從自己的歷史紀錄煉出規則: 「用 workflow 翻過我最近 50 個 session,挖出我一再重複糾正的地方,把常出現的那幾類變成 CLAUDE.md 規則。」(分流並整合 + 記憶與規則遵循)
🔹 挖出 Slack 裡沒人追的問題: 「用 workflow 翻過去半年的 #incidents 頻道,找出反覆出現、卻從來沒人開單追蹤的根本原因。」(大規模分流)
🔹 多視角壓力測試商業計畫: 「拿我的商業計畫,跑一個 workflow,讓不同 agent 分別站在投資人、客戶、競爭對手的角度,逐點挑毛病。」(對抗式驗證用在非技術任務)
🔹 80 份履歷排序: 「這裡有 80 份履歷,用 workflow 依後端職缺排序,再仔細複查前十名。先用 AskUserQuestion 工具問我評分標準。」(排序 + 生成並篩選)
🔹 命名錦標賽: 「我要幫這個 CLI 工具取名。用 workflow 腦力激盪一堆選項,再跑一場錦標賽選出前三名。」(tournament)
🔹 驗證部落格草稿的每個技術宣稱: 「翻過我這篇部落格草稿,用 workflow 對照 codebase 驗證裡面每一個技術宣稱,我不想出包。」(深度驗證)
這些任務的關鍵不是「大」,而是「有很多獨立的小判斷、需要互相把關、而且最好別全擠在同一個上下文裡」。官方還把適用情境整理成一份清單: 遷移重構、深度研究、深度驗證、上千筆排序、記憶與規則遵循、根本原因調查、大規模分流、探索與品味、評估、模型與智慧路由。反過來作者也提醒: 一般的寫程式任務通常不需要五個審查者的陣仗,別為了用而用。
7. 看一份真的 workflow: deep-research 長怎樣
上面那些模式講起來還是抽象,剛好 Claude Code 內建的 /deep-research 就是用 dynamic workflows 寫的。以下都是直接讀它實際生成的那份 JS 腳本 (數字、門檻都照腳本,不是憑空猜的)。
它的 meta 先宣告整條流水線分成五個 phase:
phases: [
{ title: "Scope", detail: "把問題拆成 5 個搜尋角度" },
{ title: "Search", detail: "5 個平行 WebSearch agent,一個角度一個" },
{ title: "Fetch", detail: "URL 去重,抓前 15 個來源,抽出可查證的主張" },
{ title: "Verify", detail: "每個主張 3 票對抗式驗證,2/3 票反駁就淘汰" },
{ title: "Synthesize", detail: "合併語意重複、依信心排序、附上出處" },
]
這就是 Claude 為「深度研究」這個任務即時寫出來的 harness,整條流水線長這樣:
agent()),中間的連接線 = 寫死的 JavaScript 編排。判斷交給模型,串接交給程式。✏️ 小編製圖
逐段拆:
Scope (1 個 agent): 把使用者的問題交給一個 agent,要它拆成 5 個互補的搜尋角度 (廣度、學術、近期新聞、反方、實作面),並用 schema 強制回傳結構化 JSON,不准自由發揮。
Search → Fetch (用 pipeline,不等齊): pipeline() 跟 parallel() 的差別是「要不要等所有人都跑完才往下」(後者是同步點/barrier)。pipeline 不等,所以角度 A 搜完、去重、開始抓網頁的同時,角度 B 可能還在搜,不必等齊。每個角度: 一個 search agent 找 4-6 個結果 → 一段「純 JavaScript」做 URL 正規化、去重、抓取額度控制 → 再對每個沒看過的 URL 平行開一個 fetch agent 抽出主張。
去重、配額這些事完全不是 agent 在做,是普通的 JS:
const novel = sorted.filter(r => {
const key = normURL(r.url)
if (seen.has(key)) { dupes.push(...); return false } // 看過了,丟掉
if (fetchSlots <= 0 && relRank[r.relevance] >= 1) { // 額度用完,低相關的丟掉
budgetDropped.push(...); return false
}
seen.set(key, ...); fetchSlots--; return true
})
Verify (用 parallel,這裡刻意要同步等齊): 對排序後的前 25 個主張,每個都平行開「3 個」對抗式驗證 agent。它們的 prompt 開門見山就是「要懷疑、想辦法反駁這個主張」,而且「不確定就預設 refuted=true」。3 票有 2 票反駁,這個主張就淘汰。這正是前面講的對抗式驗證加上生成並篩選,而 self-preferential bias 在這裡被結構性擋掉了: 驗證的不是寫出主張的那個 agent,是另外三個被叫來找碴的 agent。
parallel(Array.from({ length: 3 }, (_, v) => () =>
agent(VERIFY_PROMPT(claim, v), { schema: VERDICT_SCHEMA })
)).then(verdicts => {
const refuted = verdicts.filter(v => v.refuted).length
return { ...claim, survives: refuted < 2 } // 2 票反駁就淘汰
})
Synthesize (1 個 agent): 把存活下來的主張交給一個 agent,合併語意重複、分組成一條條 finding、依信心高低排序、附上出處,產出一份有引用的報告。
看完這份腳本就會發現,所有「需要判斷」的事 (拆角度、搜尋、抽主張、反駁、整合) 都包在 agent() 裡; 而所有「不該讓模型亂猜」的事 (串接、去重、計票、排序、淘汰) 全是寫死的 JavaScript。一個 agent 偷懶或看走眼,只會壞掉它自己那一格,不會污染整條流水線。
8. 模型生成腳本,但腳本本身是決定性的
這裡有個觀念要分清楚,也是整套設計最巧妙的地方: 寫 workflow 的是模型,但 workflow 一旦寫好,執行就是決定性的。
模型的判斷只發生在兩個地方: 一是「寫出這份腳本」的當下,二是每個 agent() 呼叫的內部。中間的迴圈、分支、去重、計票、合併,全是寫死的 JavaScript,跑幾次結果都一樣。所謂的「dynamic」,動的是「腳本被生出來」這一刻; 一旦生出來,它就是一份規規矩矩、可重播的程式。
Yi Ding 的觀察蠻精準的: 這東西本質上就是一個 (相當詳細的) prompt,教模型用 JavaScript 寫出一段像圖結構的編排描述。那段「教模型寫 workflow」的 prompt 大致在教這些 (示意,非逐字):
你可以寫一支 JavaScript 編排腳本,開頭必須是:
export const meta = { name, description, phases } // 純字面值,不能放變數或運算
腳本裡可以用這些函式:
agent(prompt, { schema, label }) // 開一個 sub-agent;給 schema 就強制它回傳結構化 JSON
pipeline(items, stage1, stage2) // 每個項目獨立流過各階段,不等齊 ← 預設首選
parallel(thunks) // 一次跑多個、等全部完成才往下 (barrier) ← 真的需要才用
phase(title) / log(msg) // 分組與進度回報
規則:
- 預設用 pipeline,只有「下一階段真的需要上一階段全部結果」時才用 parallel
- 想更可信就用對抗式驗證: 每個發現另外開 N 個 agent 試著反駁它
- 不准用 Date.now()、Math.random()、無參數的 new Date()
最後那條規則小編覺得最特別。一個正常的 JavaScript 環境怎麼可能不給你取時間跟亂數? 但 workflow 偏偏把這幾個函式做成會直接報錯。原因藏在 resume 機制裡: workflow 會把每一個 agent() 呼叫的結果寫進一份執行日誌,這樣中斷的執行才能原地接續 (已經跑完的 agent 直接從日誌裡回傳快取結果,只有沒跑完的才重跑)。一旦腳本裡摻了時間或亂數這種非決定性的東西,重跑時就會跟上一次對不起來,日誌裡的快取立刻失效。所以要時間戳記,就從 args 傳進來; 要讓每個 agent 長得不一樣,就用索引 (index) 去變化它的 prompt 或 label。
這個特別的限制也說明了整套設計的核心: 編排層必須是純粹、可重播的,模型的不確定性被嚴格關在 agent() 這個盒子裡。外面是一份能 resume、能重跑、能存檔重用的程式; 裡面才是會思考、會判斷、偶爾也會犯錯的模型。
也有幾個現實邊界值得先知道:
- 成本: 一次跑幾十上百個 agent,token 成本明顯比一般對話高,官方建議先拿小範圍試水溫
- 不能中途插手: 執行中不能插入使用者輸入,需要人工核准的地方,得拆成兩個 workflow、中間留一個核准空檔
- 檔案修改自動核准: sub-agent 預設跑在 acceptEdits 模式,所以真正該把關的是腳本本身與 workflow 邊界
- resume 有限制: 只保證在同一個 Claude Code session 內有效,關掉重開就是從頭跑
收束: 這一切其實很符合 Bitter Lesson
ihower 之前在這個部落格寫過一篇 Bitter Lesson 與 agent harness,裡面點名一個「workflow trap」: 視覺化的 workflow builder 把任務拆解鎖死在一張固定的圖上,模型之後變強了,這張圖也不會自動受益,反而變成包袱。照 Bitter Lesson 的邏輯,把可靠性押在人工手刻的鷹架程式碼 (scaffold) 上,是把複雜度搬錯方向。
dynamic workflows 巧妙地閃過了這個陷阱。差別在於: 拆解 workflow 的不是人,是模型,而且每個任務都重新寫一份客製的。 官方那句話講得最到位: Claude 現在可以「為手上的任務即時寫出自己的 harness」。你拿到了確定性編排帶來的可靠性 (避開偷懶、偏袒、漂移),卻不必付出人工設計鷹架的代價,而那種鷹架正是模型一變強就第一個被淘汰的東西。所以這個設計是順著 Bitter Lesson 的: 連「編排」這件事本身,也交還給模型。
ihower 那篇的結論是: 原本覺得需要人工編排的 workflow 任務,幾乎都能丟給模型即時生成的 harness,不必再事先設計流程。dynamic workflows 基本上就是這個方向的具體實現。
小編看法
最後小編補幾個比較主觀的想法。
需要 GUI 支援
如果它就停在 CLI 這個形態,小編覺得採用門檻會偏高。原因是這套概念其實偏抽象: 計畫從上下文搬進腳本、決定性編排、對抗式驗證,這些好處都要想一層才懂,不容易一眼看懂。對多數使用者來說,體感上最直接的反而是「token 怎麼燒這麼兇」,那個爽點 (省下的上下文、避開的偷懶與漂移) 卻是隱形的,藏在你看不到的地方。
但如果把它做成 GUI,讓那份編排腳本變成一張動態的節點與連線圖,agent 怎麼分流、在哪裡匯合、哪一條審查鏈正在跑、哪個節點卡住了,全部即時長在眼前,採用率會高很多。因為「看見流程怎麼跑」這件事太有感了,它把隱形的價值變成你盯著看的畫面。
希望同時支援事先生成和動態生成
目前 Claude Code 是靠 ultracode 自動判斷這個任務要不要動用 workflow,而且每次都是當場重新編排一份。你雖然可以把喜歡的那份存下來、下次重用,但小編實測後發現,存下來的腳本常常把這一次執行的具體場景 (檔名、數量、路徑那些) 寫死進去,重用性其實沒那麼完美。更可惜的是,你沒辦法「先讓它把 workflow 的 JavaScript 生出來、自己檢查過、確認沒問題,再真正執行」,生成跟執行是綁在一起的。
其實這就是前面講的 LangChain interpreter skills 在做的事: 事先寫好一份確定性的編排腳本,存起來重用。小編希望 Claude Code 能兩種都支援: 對重複性高的任務,可以事先生成、檢視、微調一份 workflow 腳本再拿去跑; 對一次性的任務,維持現在每次動態生成的做法。
不過還是得說一下這兩種做法的優缺點:
- 事先生成: 可檢視、可測試、可微調,對重複性任務更可控。但缺點是一旦把編排凍結下來,模型下一版變強了,這份腳本也不會自動受益,反而可能變包袱,這正是前面講的 Bitter Lesson 的風險。
- 動態生成: 每次針對當下任務量身定做,模型變強就自動受益,不會被舊腳本綁住。但缺點是你沒辦法事先檢查,生成跟執行綁在一起,而且存下來的腳本容易把場景寫死。
或是有一種中間解: 執行前能把生成的腳本叫出來瞄一眼、改幾筆 (要不要看是你的自由,不強制),存檔時多一步「幫我把這次的檔名、數量、路徑抽成參數」,讓重用的是「編排骨架」而不是「那一次的場景」。這樣既保住動態生成的彈性,又補掉現在重用會寫死的痛點。
OpenAI 的缺席
小編覺得比較可惜的是,整條脈絡最起點的 Code Interpreter,當年其實是 OpenAI 在 ChatGPT 上帶火的 (一度叫 Advanced Data Analysis),是它先讓大家看到「讓模型寫程式碼、跑程式碼」有多好用。但後來把「程式碼當行動空間」一路往 agent 編排推的,反而是 Cloudflare、Anthropic、LangChain 跟學界。OpenAI 在 Codex 產品層有做 subagents (平行 spawn 多個 agent),但在 API 層、SDK、產品上一直沒有走「程式碼當行動空間」這個方向,沒有 PTC 等級的東西,Code Interpreter 裡的程式碼到現在還是碰不到 agent 的工具。
補充比較: 那 agent teams 呢? 小編沒那麼看好
跟 dynamic workflows 幾乎同期,Claude Code 還推了另一個平行化功能 agent teams (目前還是 experimental、預設關閉)。
一句話講清楚差別: dynamic workflows 是「模型寫一份決定性腳本,編排一群各自獨立的 sub-agent」; agent teams 則是「開一個 team lead,底下生出好幾個完整的 Claude Code 實例當隊友,隊友各有自己的上下文、能互相點對點傳訊、搶同一張 task list 的工作」。subagent 只會把結果回報給主 agent,彼此不講話; agent teams 的隊友則能互相討論、互相挑戰,你甚至可以分別對每個隊友下指令。
 圖片來源: Cat Wu (@_catwu)
圖片來源: Cat Wu (@_catwu)
小編在 《Multi-Agent 反模式與推薦模式》 那篇整理過一個核心判斷: multi-agent 的價值是「並行覆蓋」,不是「分工」。 而 agent teams 的賣點剛好踩在這條線上,看你怎麼用,很容易滑到錯的那邊:
1️⃣ 「角色分工」很容易滑進三省六部的幻覺。 官方範例那種「一個管 UX、一個管架構、一個當魔鬼代言人」「一個查安全、一個查效能、一個查測試」,如果是唯讀的審查或研究,那是健康的並行覆蓋,沒問題。但只要任務變成「每個隊友各認領一個模組去寫 code」,就掉進那篇點名的反模式: LLM 沒有人類的注意力上限,貼上「架構師」「QA」的角色標籤不會讓它更強,只會多出人為的推諉跟一層層的傳話漂移。
2️⃣ 並行寫入的老問題它沒解,只是叫你自己閃。 官方文件自己就寫: 「兩個隊友改同一個檔案會互相覆蓋,請把工作切開、讓每個隊友各自負責不同的檔案。」避免衝突的責任,被原封不動丟回給你手動切。Devin、Cognition 的工程經驗早就講白了: 平行寫入到現在還是行不通,可靠的做法是「單線寫入、其他 agent 只負責判斷」。
3️⃣ 點對點通訊 = 通訊開銷 + 傳話遊戲。 隊友彼此直接傳訊 (官方範例還鼓勵它們「像科學辯論一樣互相反駁」),agent 一多,訊息就多、漂移就多、也更難觀測。對照之下,orchestrator-worker (subagent、dynamic workflows 走的就是這條) 把溝通收斂到中心,反而更穩、也更好整合。那篇也提過,大廠 (Anthropic、OpenAI、Google) 實際用的都是 orchestrator-worker,不是角色扮演的流水線。
4️⃣ 成本跟可靠性都還沒到位。 每個隊友是一個完整的 Claude Code 實例 (不是輕量 subagent),token 隨人數線性往上疊。multi-agent 普遍燒 3-10 倍,Anthropic 自家 research 系統甚至約 15 倍。而且三個 90% 正確率的 agent 串起來,整體正確率掉到 72.9%。目前它還掛著一排 experimental 限制: 不能 resume、task 狀態會 lag、關機很慢、一次只能帶一個 team、不能巢狀、lead 還不能換人。學界也才剛出一篇 CooperBench,直接以「為什麼 coding agent 還當不了你的隊友」為題,點出它們缺的正是找共識、協調這種社會性能力。
另外一個觀察: agent teams 到現在還是 experimental、預設關閉,你得自己去設一個 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS 環境變數才打得開。相比之下 dynamic workflows 直接上線、ultracode 隨叫隨用,兩者的成熟度差距從預設值就看得出來。
小編認為 agent teams 相對 dynamic workflows 的優勢並不明確。官方推薦的入門場景是唯讀的並行探索 (PR 審查、競爭假設除錯、查資料),但 dynamic workflows 用決定性編排加上對抗式驗證,一樣能做這些事,而且更便宜、更可重播。agent teams 真正不同的地方是「你可以在執行中途跟個別隊友對話、調整方向」,這是 workflow (背景跑完才回來) 做不到的,但這個互動性是否值得額外的成本和複雜度,目前沒有明確的證據。一旦想拿它來「分工寫 code」,就撞進那篇反模式的失敗區。
✏️ 小編製圖
這兩者真正的差異在前面講的那些: 決定性與可重播、成本結構、通訊模型 (中心化 vs. 點對點)、以及並行寫入的可靠性。從這些維度看,dynamic workflows 目前成熟度明顯領先,而 agent teams 還在找它真正不可替代的場景。
參考連結
- Executable Code Actions Elicit Better LLM Agents (CodeAct 論文)
- smolagents (Hugging Face CodeAct 實作)
- OpenAI Code Interpreter
- Cloudflare Code Mode
- Cloudflare Code Mode MCP Server
- Claude Programmatic Tool Calling (PTC)
- LangChain Deep Agents Interpreter
- LangChain Interpreter Skills
- RLM 論文 (Recursive Language Models)
- Claude Code Dynamic Workflows 官方 Blog
- Claude Code Dynamic Workflows 官方文件
- “A harness for every task” by trq212
- Voxyz: 計畫從上下文搬進腳本
- Yi Ding: workflow prompt 分析
- alexop.dev: 決定性編排與 resume 機制
- Omar Khattab: Claude Code 終於是一個 RLM
- Alex Zhang: 第一個被認真訓練成 RLM 的前沿模型
- Cat Wu: Agent Teams vs Dynamic Workflows
- Claude Code Agent Teams 文件
- Why Do Multi-Agent LLM Systems Fail? (MAST)
- CooperBench: 為什麼 coding agent 還當不了你的隊友
- smolagents Multi-Agent 範例
- Bitter Lesson 與 agent harness (愛好 AI Blog)
- Multi-Agent 反模式與推薦模式 (愛好 AI Blog)