給 Agent 開發者的駕馭工程 (1): 基礎: Deep Agent 的六項內建能力

最近 Harness Engineering、Loop Engineering 這些詞愈來愈常出現,LangChain、OpenAI、Anthropic 幾家也都開始用「harness」這個說法。這個系列是 ihower 一場談 Harness Engineering 演講的書面展開版,由小編整理成文。
在開始之前,有個重要的但書要先講清楚,定位這整個系列:
要談 harness,得先弄清楚 agent 本身已經能做什麼。今天大家在用的 Claude Code、Codex 這類 Deep Agent,都內建了一組能力: 模型不只回覆文字,還能規劃工作、使用工具、保留外部狀態、讀寫檔案、呼叫子代理人,並在較長的任務中維持方向。這篇先把這些常見能力整理成六類,講清楚各自解決什麼問題、技術上怎麼辦到。但這些能力加總起來,仍然還不是 harness。先把這一層搞懂,後面幾篇才好接著談。
編按: 把 Deep Agent 拆成「六類」是本系列為了講解而做的分類,不是業界唯一講法。例如 LangChain 在 Deep Agents 一文就歸納成四個特徵: 詳細的 system prompt、規劃工具 (planning tool)、子代理 (subagents) 和檔案系統 (filesystem)。重點不在湊到剛好幾項,而在這組能力怎麼搭配。
呼應上面的定位再提醒一句: 下面會用 Claude Code、Codex 當例子,因為它們是目前最成熟、最好觀察的 Deep Agent。但這六項能力並不是 coding agent 的專利。當你自己開發 Text-to-SQL Agent、RAG 或訪談 agent 時,同樣要面對「需不需要這項能力、該怎麼配置它」的選擇。看懂這六項,就是看懂你之後要自己組裝的那組元件。
要補一個重點: 下面這六項,是一個「通用」coding agent (要能應付五花八門的軟體任務) 才需要的完整清單。自行開發特定用途的 agent 時,不一定全部都用得上,按任務需求取捨就好。任務相對單純、不太需要事先規劃,就不必上 Plan & Todos; 沒有編輯檔案、也沒有跨 session 記憶的需求,Filesystem 跟 sandbox 也可以省下來。把它當成一份可選配的能力清單,而不是每個 agent 都得全部裝上。
先回顧: Agent 就是 LLM 在迴圈裡使用工具
不管講得多複雜,今天所有 agent 的共同底層就一句話: 一個 LLM 根據目標決定步驟、呼叫工具、觀察結果,再決定下一步,這樣一圈一圈跑到任務完成。
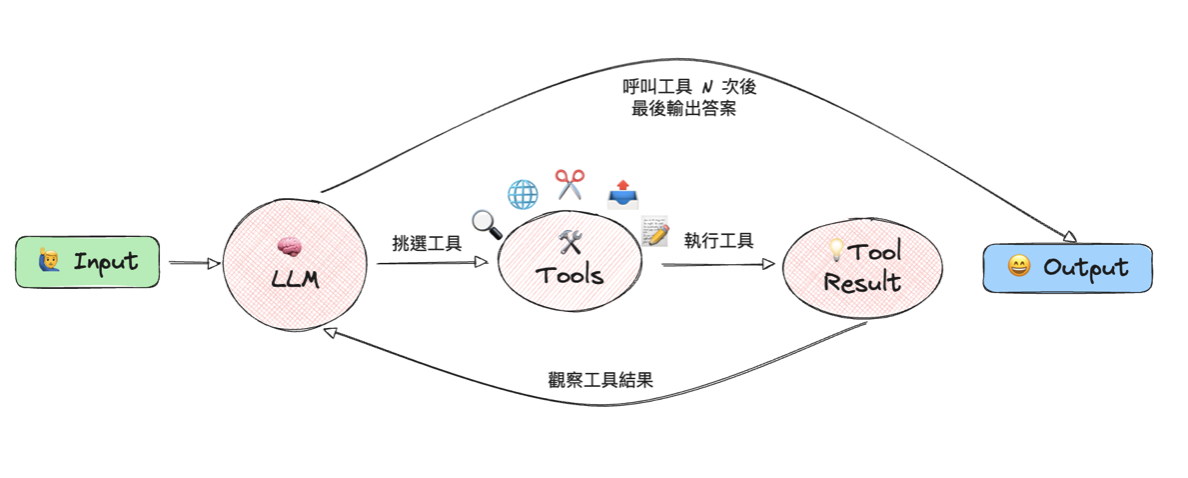
這個迴圈本身很簡單,Anthropic 自己也形容他們的 runtime 是一個「笨迴圈 (dumb loop)」: 智能全在模型裡,迴圈只負責管每一輪要做什麼。
過去一年大家熟悉的 agent 比較「淺」: 它能依據的就只有上下文視窗裡的內容,做 5 到 15 步的任務沒問題,但碰到要 500 步、要跨好幾天的任務就會失控,常見三種狀況: 工具輸出塞滿 context、把原本的指令擠出視窗;在一堆中間步驟的雜訊裡忘了原本要達成的目標;一旦走錯方向,也不會停下來回頭、換個做法重來,只能將錯就錯。Deep Agent (有人叫它 Agent 2.0) 的做法,就是把下面這六項能力直接內建進去,讓 agent 能應付更大更複雜的任務。技術上幾乎都是同一招: 用 Function Calling 定義一組工具丟給模型呼叫。一項一項看。
能力 ①: Plan & Todos,把大任務拆開、逐項打勾
淺 agent 是用 chain-of-thought 隱式地規劃 (像是「我先做 X、再做 Y」),但這些念頭混在一大堆中間步驟的雜訊裡,很容易就被忽略、忘掉。Deep Agent 改成用工具維護一份顯式的待辦清單,通常就是一份 markdown 格式的待辦清單。
它的好處有兩面: 對 agent 來說,每做完一步就回頭更新清單、把項目標成進行中或完成,就不會忘記還有什麼沒做;對使用者來說,進度完全透明,隨時看得到 agent 做到哪。如果某一步失敗了,它也不是盲目重試,而是更新清單、把這次失敗納入考量。
TaskCreate/TaskGet/TaskUpdate/TaskList 幾個工具。有意思的是,LangChain 在《Deep Agents》一文指出: Claude Code 的 Todo 工具其實是個 no-op (沒有實際作用的空操作),它什麼事都沒做,純粹是一種 context engineering 手段,用待辦清單讓 agent 不偏離當前任務。能力 ②: Filesystem & Bash,讓 agent 真的動手做事
光會思考沒用,要能操作真實環境。Filesystem 讓 agent 讀檔、寫檔、改檔; Bash 讓它執行任意 shell 指令。有了這兩樣,agent 就能真的動手: 編譯程式、跑測試、操作 git、安裝套件、處理檔案。這裡有個常被忽略的重點: AI 不需要 GUI 視覺介面,只要有 CLI 就能把事情做完。
Filesystem 可以說是最基礎的一塊。它一次解鎖了好幾件事: 給 agent 一個工作區去讀資料和程式碼; 把塞不進 context 的東西先寫到檔案、需要時再讀回來; 把工作持久化,撐過單一 session; 多個 agent 之間還能透過共享檔案協作。再加上 git,就多了版本控制,能追蹤進度、回滾錯誤、開分支做實驗。
Bash 則是那個「通用工具」。預先配置好的工具只能覆蓋設計者想到的情況,但你不可能為每個動作都先寫好工具。給了 bash 跟程式執行能力,模型就能自己寫 code 當成臨時工具,遇到缺什麼能力就補什麼,不會被固定的工具集限制住。
run_bash 的工具執行 CLI 指令,read_file/write_file/edit_file 讀寫檔案,glob/grep 搜尋檔案。實務上這些動作通常跑在 sandbox 裡,隔離執行、可以限縮可用指令和網路權限。編按: sandbox 怎麼設計、有哪些隔離方式,本身就是一個大題目,可以參考 Agent Sandbox 沙箱架構: 論兩種設計模式與七種隔離方式。
能力 ③: Sub-Agent,把耗 token 的工作交給子代理人
複雜任務需要分工。淺 agent 在一個 prompt 裡什麼都自己來; Deep Agent 則用 Orchestrator → Sub-Agent 的模式。主 agent 把研究、查找、驗證這類耗 token 的工作派給子代理人,每個子代理人帶著自己獨立的 context 去跑,跑完只把整理好的結論回報主 agent。
這樣設計的關鍵價值在「context 隔離」。子代理人在自己的迴圈裡搜尋、出錯、重試,可能耗掉好幾萬個 token,但它最後只回傳一兩千 token 的精簡摘要,主線的 context 不會被那些中間過程塞滿。而且多個子代理人可以同時平行工作,加快整體進度。
spawn_agent 的工具,工具內部就是去呼叫另一個 agent 執行,跑完再把結論回傳。從主迴圈的視角看,這跟呼叫任何一個普通工具沒兩樣。編按: 什麼時候該拆多代理人、什麼時候反而是反模式,業界已經有一些收斂的共識,可以參考 Multi-Agent 架構再探: 三省六部反模式和業界收斂共識。
能力 ④: Memory,跨 session 記得你和你的專案
模型本身只記得權重裡的東西,加上當前 context 視窗裡的內容。session 一結束,這次對話就忘光了。Memory 要解的就是這個: 分析對話、把重要資訊存起來,下次再開 agent 它還記得你。最常見的形式就是 Claude Code 的 CLAUDE.md、Codex 的 AGENTS.md 這類專案記憶檔。
在不能改模型權重的前提下,「加知識」唯一的辦法就是把內容注入 context。所以做法是: agent 一啟動就預設載入 memory 檔; agent 後續更新了這個檔,harness 再把新版載進來。要講清楚的是,這是一種運作在 context 這一層、而不是模型權重那一層的外部記憶: 把專案規則、使用者偏好、過去決策、工具說明寫在檔案或資料庫裡,讓 agent 在需要時重新讀回。它不是模型權重的即時更新,而是一套把重要資訊記錄、壓縮、再重新注入上下文的機制。
這裡有個容易被忽略、但很關鍵的設計原則: agent 要把自己的記憶當成「提示 (hint)」,而不是事實。行動之前,要對照真實狀態再驗證一次。例如 Claude Code 的記憶其實分三層: 一個一律載入的輕量索引、需要時才拉進來的主題檔、以及只能透過搜尋存取的原始逐字記錄,避免一股腦把所有記憶塞進 context。
AGENTS.md,使用者也可以要求它更新這個檔。你還可以自行設計記憶行為: 要記什麼、存在哪些目錄檔案、什麼時候回憶哪些內容。編按: 這個 memory 檔到底該寫什麼、不該寫什麼,可以參考 AGENTS.md / CLAUDE.md 該寫什麼、不該寫什麼?。另外很多人以為做 agent 記憶一定要上向量資料庫,其實多數情況用不到,這點在 Agent Memory 實作: 大多數記憶功能不需要用到向量檢索 有完整討論。
能力 ⑤: Skills,按需動態載入的技能 prompt
一個 skill 是為特定任務準備的一包東西: prompt、工具配置、甚至程式碼。例如翻譯 skill、寫部落格 skill、處理 PDF 的 skill。重點在「按需載入」: 不把所有技能一次全塞進 context,而是用到哪個才載入哪個。要新增一個技能,寫一個 markdown 檔就行。
為什麼要這樣設計? 因為工具或 MCP server 一多,光是啟動時把它們的說明全部載入 context,就會在 agent 還沒開始做事前先拉低表現 (這也是後面系列會談到的 context rot 問題)。Skills 用的是「漸進式揭露 (progressive disclosure)」: 平常只讓模型看到一份精簡的技能列表,真正需要時才展開完整內容。
編按: skill 跟 MCP 是什麼關係、會不會取代 MCP,可以參考 後 MCP 時代: Skill 取代 MCP 嗎?。想實際動手寫一個 skill,則可以看 Claude Skill Creator 新版解析: 用 AI 幫你寫 Skill、測 Skill、改 Skill。
能力 ⑥: 更多工具,接上更大的世界
前面五項大多在 agent 自己的工作區內運作,第六項是往外接。這類嚴格說不算 Deep Agent 的必要條件,比較像常見 Deep Agent harness 會接上的工具介面,讓它從「會處理檔案」進一步變成「能跟外部世界互動的系統」。三個代表:
- MCP (Model Context Protocol): 標準化的工具協議,讓 agent 能接上 Slack、Gmail、Notion,或你自建的 API。把「怎麼接外部服務」標準化,工具生態就能共用。
- Browser: 瀏覽網頁、填表單、點按鈕,讓 agent 能上網做事、或用網頁來驗證自己的產出。
- Computer Use: 更進一步,直接操作桌面 GUI,看螢幕截圖、移動滑鼠、敲鍵盤。
編按: 想看這六項能力更完整的拆解,可以參考 Philipp Schmid 的 Agents 2.0: From Shallow Loops to Deep Agents 和 LangChain 的 Deep Agents。
光有這些能力,還不夠
六項講完,退一步看全貌。它們解決的其實是同一件事: 「能不能做」。能操作檔案、能執行程式、能拆任務、能記得事情、能接上更大的世界。這是必要的基礎能力,是 agent 動手做事的前提。
但「有能力」不等於「會用能力把事情做好」。到這裡為止,我們其實都還沒談到真正困難的那一半: 該怎麼運用這些能力,讓 agent 穩定地跑完一個動輒幾十、上百步的複雜任務。能力給了你前半,後半還空著:
要把右邊這半補起來,光堆能力沒用。缺的不是更多工具,而是把這些能力接成一個可驗收、可修正、可持續運行的回饋系統: 每一步的產出有沒有被檢查、整個任務有沒有對著明確的完成條件驗收、走錯了能不能修正後再繼續跑。這套工程,就是這個系列要談的 harness。
下一篇進入正題: harness 到底是什麼?