給 Agent 開發者的駕馭工程 (6): 回饋時機四: 外層 Loop, Ralph、Symphony 與 Cron

上一篇談時機③,在「每一輪結束」這個邊界上,把「做完了沒」交給一個夠獨立的判斷。但它有個結構性的上限: 不管哪一種實作,都在同一個 session、同一份 (或續跑的) context 裡進行。當任務大到一個 context window 根本裝不下 (要跑幾百步、跨好幾天),光靠單輪驗收收斂不了,失敗的推理還會在 context 裡越積越多,污染後面的判斷。
這一篇進到時機④: 外層 Loop。四個時機由內而外,這是最外、也最貴的一層。
要先說清楚一件事: 這一層在社群討論得很熱,Peter Steinberger 那句「你不該再去提示 agent,你該設計提示 agent 的迴圈」被反覆討論了好幾個月,Boris Cherny、Andrej Karpathy 也都講過類似的話,還出現了 loop engineering、loopcraft 這些新詞。但這些講法指向的東西其實很具體,後面會一個一個拆開來談。
為什麼需要外層迴圈
先講清楚這層在解什麼。前面幾個時機都假設「一個 context 裝得下整個任務」,在這個前提內把迴圈閉合。一旦離開這個前提,有三種情況會讓你需要把迴圈往外推一層:
- context 塞滿: 工具輸出、中間推理把 context 佔滿,模型表現明顯變差
- 失敗推理污染: 前面出錯的推理留在 context 裡,持續影響後面的判斷
- Goal 跨不過 session: 時機③的驗收只在一個 session 內有效
這三種情況指向同一個東西: 一個在任何單一 context 之外、不會隨某一輪 agent 收掉就跟著消失的工程機制 (也就是外層 harness)。它負責決定什麼條件觸發、每件工作開哪一份乾淨 context、多條 agent 怎麼協調,以及最關鍵的,進度怎麼在一圈一圈之間傳下去。後面要談的三種實作剛好各自對應一種情況: Ralph 對著一個大任務一圈圈重跑 (①)、Symphony 同時管很多張 ticket、各配一個 agent (②)、Cron 靠排程或事件自動起跑 (③)。
這裡有個觀念要先確立,它貫穿後面三種實作: 外層迴圈最關鍵的設計,是把「進度」這件事從 context 搬到磁碟。 模型在每一圈結束後 context 就清空了,所以能撐過多圈的不是模型自己記得,而是那份留在外面的狀態。Geoffrey Huntley 講 Ralph 時講得很直白: agent 會忘,但 repo 不會。
那這份外層迴圈具體怎麼搭? 這裡挑三個有代表性的案例來分析。
/loop)。時間到就跑一輪,依 context 是否沿用再分兩種。Ralph: 最笨也最有名的 Loop
第一種是 Geoffrey Huntley 在 2025 年中提出的 Ralph,做法簡單到第一眼會以為是在開玩笑:
while :; do
cat PROMPT.md | claude-code
done
就是一個 bash 無窮迴圈,每一圈把同一份 prompt 檔交給 agent,跑完就再來一次。沒有花俏的編排,沒有狀態機。它真正的設計重點不在迴圈本身,而在「每一圈都是全新的 context」: 不讓對話一直長下去,而是每圈歸零,只從固定的幾份檔案重新讀起。靠這個做法,Huntley 用 Ralph 完成過一個完整的編譯器專案,也用大約 297 美元的 API 成本,做出一個原本報價 5 萬美元合約的 MVP。
那這個「無窮」迴圈怎麼停? 其實它是有完成條件的: 當 agent 認為 prd.json 上的任務都完成了,會輸出一個約定好的字串 <promise>COMPLETE</promise>,外層 bash 每一圈用 grep 比對這個字串,一比中就跳出迴圈、不再重跑;另外再配一個 max-iterations 上限 (snarktank 範本預設 10 圈) 當保底,避免卡住時一直跑下去。也就是說,完成與否是讓模型自己宣告、再靠字串比對來認定,這也是後面批評會談到的點: 它是模型自己說了算,不是獨立驗證過的 Goal。
跨圈記憶: 進度全靠外部狀態
既然 context 每圈歸零,進度就得放在 context 之外。Ralph 把這件事拆成三個檔案,這也正好是前面那句「進度搬到磁碟」最具體的示範:
passes 狀態。每圈挑最高優先且還沒過的來做。snarktank/ralph 這個現成的範本把一圈的動作寫得很清楚: 讀 prd.json 和 progress.txt → 挑一個最高優先、passes: false 的 story → 只實作這一個 → 跑 typecheck 和測試 → 過了才 commit、把 passes 標成 true → 把這圈學到的東西追加進 progress.txt → 下一圈。它強調的成功要件,其實全是前幾篇講過的東西: story 要切小到一個 context 裝得下、要有 typecheck 和測試這種快速回饋、完成條件要寫清楚。換句話說,Ralph 的外層迴圈能不能跑得動,仍然取決於內層那兩個時機有沒有先做好。
ralph-wiggum Plugin: 名字一樣,機制不同
這裡要插一個容易混淆的點。Anthropic 官方在 Claude Code 出了一個叫 ralph-wiggum 的 plugin,名字明顯是在致敬 Ralph,但它的機制跟原版相反:
--max-iterations、--completion-promise 控制何時停。是個「不讓它結束、要它繼續做」的設計。一個換新 context,一個不讓它結束,context 處理剛好相反。這正好呼應系列第五篇那條教訓: 別只看名字,要看實作。 上一篇講 Codex 的 goal mode 時,看過有流量不錯的文章把它說成「用獨立小模型每回合評分」,翻原始碼才發現根本沒有第二個模型。這裡也一樣: 兩個都叫 Ralph,但你要是照原版的心智模型去用 plugin、以為它每圈會清掉 context,就會踩雷。harness 的細節,看名字、看標題都不準,得自己讀一次 code。
而把 code 讀完,會看到一個比「同 session」更有意思的點。plugin 每一圈送回去的,是你最初下的那段 prompt 原封不動 (存在 .claude/ralph-loop.local.md,官方明說「prompt 不會在迭代之間改變」),只多附一行系統訊息提醒這是第幾圈、以及「要停就輸出 <promise>DONE</promise>,但只有陳述為真才准、別為了結束就說謊」。它判斷完成的方式也很陽春: 去比對最後一則回覆裡有沒有那個寫死的 <promise> 字串。把「同一條 thread 一路長下去」加上「完成與否由主模型自己判定」這兩件事擺在一起,你會發現它的機制其實更靠近上一篇的 Codex /goal,而不是原版 Ralph: 原版每圈換一份乾淨 context,plugin 跟 Codex 都是同一份 context 一路跑、自己宣告做完。差別只在 Codex 送回去的是一份專門寫過、含完成審計程序的接續模板(continuation),宣告還得過 update_goal 那串嚴格條款; plugin 送的是原 prompt、停止只認一個字串相符,加一句口頭提醒,等於是這幾種做法裡最寬鬆的一種完成判定。所以「ralph-wiggum 是什麼」這題,光看名字會答成原版 Ralph,讀完 code 才知道它實際上更像 Codex /goal。
對 Ralph 的批評
Ralph 有名,但 OpenClaw 作者 Peter Steinberger 對它的批評也很直接,大致三點: 一是弱模型的權宜之計(workaround),模型不夠強,才需要在外層一直重跑來硬補; 二是靠耗掉大量 token 硬做,而不是聰明收斂; 三是把人從迴圈裡抽得太遠,產出沒人把關 (他用「slop in a loop」,迴圈裡的垃圾,來形容)。
但他反對的不是迴圈本身,是用蠻力迴圈取代思考。他自己照樣大量用 loop,只是配上有收斂條件的 /goal,以及自己寫的審查、驗證 skills,人仍然在把關架構決策。
用這個系列的說法來講: Ralph 只做了外層的「排程」(一直重跑),卻沒接好內層的「驗證」和「方向」。第二篇講過,只有回饋、沒有前饋,agent 常重跑好幾圈還是偏離目標。所以更精確的說法不是「Ralph 不好」,而是「外層迴圈不能取代內層的 harness,它是疊在上面、不是換掉它」。
OpenAI Symphony: 把看板變成控制平面
第二種實作來自 OpenAI 的 Symphony,它的出發點比 Ralph 高一階。
故事是這樣: OpenAI 有個團隊做過一件事,整個 repo 不准有人手寫程式碼,每一行都得由 Codex 生成 (這就是他們上一篇 harness engineering 文章的主題)。做成之後,下一個瓶頸就出現了,而且不是模型不夠強,是人的注意力不夠用: 一個工程師同時顧 3 到 5 個 Codex session 就到極限,再多就開始忘記哪個 session 在做什麼,得在終端機之間跳來跳去。他們等於是組了一隊很能幹的初級工程師,卻得把資深工程師全部拿去盯著這些 session 跑。
Symphony 的解法是換一個控制單位。不要再以「session」和「PR」為中心去管理,改以「任務」為中心: 把 Linear 這類專案管理看板當成 coding agent 的控制平面,每一張開啟中的 ticket 都保證有一個 agent 在自己的工作區裡跑,一直跑到進入下一個狀態為止。Agent 掛了就重啟,有新 ticket 就派工。OpenAI 說某些團隊導入後,三週內合併的 PR 增加了 500%。
看板就是狀態機
Symphony 的迴圈,核心是把看板的 ticket 狀態當成一台狀態機在驅動:
- 狀態機: Symphony 盯著看板,有 ticket 進到 Todo 就派 agent,移到 Rework 就讓 agent 帶著 review 意見重做,進到終態就收掉。
- 任務 DAG: 大型工作不是一張 ticket。先派一個 agent 讀 codebase、Slack、Notion 產出實作計畫,再展開成一棵帶依賴關係的任務樹,沒被 block 的任務自然平行跑。文章舉的例子是: React 升級被標成 block 在 Vite 遷移上,agent 就真的等遷移完才動 React。
- Agent 自己開 ticket: 實作或 review 中發現的效能問題、重構機會,agent 直接開一張新 ticket 排程,而不是塞進當前任務。
- 交付的是工作成果證明 (proof of work): agent 不只交 code,還附 CI 狀態、PR review 回饋、甚至一段操作示範影片。一句話總結這套設計的精神: agent 的目標不是「寫完 code」,而是「說服人類把這段程式碼合併」。
值得補一句的是,Symphony 的「任務」不必然是寫 code。OpenAI 自己就說,有些 ticket 是純粹的調查或分析,從頭到尾不碰 codebase; 你也可以開一張「分析這個資料、產一份報告」的 ticket 交給它。看板這層抽象一旦確立,它管的就是「要完成的工作」,而不是「要寫的 code」。從這個角度看,Symphony 比較像一套組織級的外層 harness。
編按: 跟外層 Loop 的主題稍微岔開,但 Symphony 有個細節值得一記: 它開源出來的核心是一份
SPEC.md,不是實作的程式碼。這份 spec 是從內部實作逆向整理出來的 (一開始只是 tmux 裡一個 Codex session 在輪詢 Linear),OpenAI 還為了讓這份 spec 更完整,讓 Codex 用 Elixir、TypeScript、Go、Rust、Java、Python 各實作一遍; 官方建議的用法第一條,就是把 spec 交給你自己的 agent、用你選的語言實作一個。當實作隨時能被 agent 重建,真正的資產就從 code 移到了那份定義「要解什麼問題、邊界在哪」的 spec。這個重點系列後面還會再談到。
Cron 排程和 Heartbeat
第三種實作最輕量、也最通用: 自動觸發。不靠你手動下指令,而是設一個觸發條件,條件一到就自動把一段 prompt 送出去跑一輪。它輕到不必另外建任何東西: Claude Code、Codex 這些 coding agent 都已經把它做成內建功能 (後面會講到的 /loop、Routines、Automations 就是),設一行排程就能用,這也是三種裡最容易上手的一種。
觸發的節奏分兩種。一種是定時: cron 排程,時間到就跑; 這種通常還會避免重疊,上一輪還在跑就跳過這次、不疊著開。另一種是讓 agent 自己決定下一次何時跑: 沒事就把間隔拉長、有狀況就縮短。(也可以不看時間、改綁事件: webhook、新郵件、CI 失敗就觸發。)
而這層真正的設計重點在另一條軸: 「每次觸發要不要沿用上一次的 context」。這條分界把自動觸發分成差很大的兩種:
這條「每次獨立、還是沿用 context」的分界,Codex 的 Automations 乾脆直接做成兩種類型。一種是 standalone automation: 照排程 (可填 cron 語法) 起一個全新的 run,結果進一個叫 Triage 的收件匣,有發現才進來、沒發現就自動封存 (這個「沒東西就封存」跟前面 Symphony 沒發現就歸檔是同個設計)。另一種是 thread automation,官方原話就是「heartbeat 式的定時喚醒,綁在當前這條 thread 上」: 定時回到同一段對話、保留 context,適合盯著一個長命令跑完、或定時回來推進一個 review 迴圈。同一個產品,把「要不要沿用 context」這個設定直接做成兩個選項。它還多給一個獨立的選擇: 在 git repo 裡,automation 可以跑在你的本地 checkout,也可以開一個獨立 worktree 隔離,免得動到你手上還沒寫完的東西。
Claude Code 則把這兩種拆在不同地方。heartbeat 式的是 session 內的 /loop: 它綁在單一 session、只在空檔執行,錯過的觸發不會補跑 (no catch-up),適合「定時看一眼、有事才處理」的輕量定時檢查,不適合非得準時、不能漏的硬排程。
/loop 5m 檢查 deploy 狀態, 失敗就修 ← 固定間隔
/loop 盯著 CI, 紅了就處理 ← 動態間隔: 模型自己決定下次何時跑
/loop 剛好上面兩種節奏都給你: 給間隔 (5m) 就定時跑,不給就交給模型自己決定下次何時跑。要每次一份乾淨 context 的那種,則要跳出 session,改用跑在 Anthropic 雲端、每次一份全新 clone 的 Routines (用 /schedule 建)。對自建 agent 來說,選哪一種是你得自己決定的設計取捨: 每次給乾淨 context 的那種,進度全靠外部狀態; 長駐 session 則記憶連續、但 context 一直變長。
要強調的是,排程這層只管「什麼時候跑」,它完全不判斷「做到什麼程度才算完」。 一個 cron 就是時間到了把 prompt 送出去,至於這一輪該不該停、夠不夠好,排程一概不管。這就帶到外層 Loop 一個很重要、卻常被混為一談的觀念。
Goal 和 Loop 可以一起用
社群常把 /goal 和 /loop 混著講,好像是兩個競爭的東西。其實它們管的是兩件不同的事,彼此不衝突,可以分開用,也可以組合起來用:
| 管什麼 | 回答的問題 | |
|---|---|---|
| Loop (Ralph/Symphony/cron) | scheduling 排程 | 什麼時候跑、多久跑一次 |
| Goal (上一篇) | termination 終止 | 做到什麼程度才算完、才能停 |
看懂這個分工,就有兩種組合用法。第一種是疊起來: 這一篇講的三種外層 loop,每一個都可以掛上一個上一篇講的可驗證 Goal。Ralph 的每一圈、Symphony 的每張 ticket、cron 的每次觸發,都能配一個停止條件,變成「時間到就啟動、做到驗證過才停」的工作 (run-to-completion job)。loop 是外圈 (管排程),goal 是內圈 (管終止)。
第二種是串接: loop 偵測到事件、把工作推進某個 queue 就結束,另外派一個帶 goal 的任務去把它做完。前者管「發現工作、何時啟動」,後者管「把這件事做到通過驗證」。
關鍵是別把兩者混為一談。一個只有 loop 沒有 goal 的迴圈,就是前面講的 Ralph 那種問題 (一直重跑到圈數上限才停); 一個只有 goal 沒有 loop 的任務,則被綁在單一 session 裡,跨不過 context 的上限。兩個各自獨立的設定,可以分開調,也可以一起調。
把自己移出迴圈
三種實作講完,回到開頭那句廣為流傳的話。Peter Steinberger 說的是:
「這是你每月一次的提醒: 你不應該再去提示寫程式的代理人了。你應該要設計『讓你的代理人被提示』的迴圈。」
Boris Cherny 講得更具體,說他現在的工作就是寫 loop: 不再自己提示 Claude,而是讓跑著的 loop 去提示 Claude、去決定要做什麼。他甚至給過數字: 過去 30 天他對 Claude Code 的貢獻,100% 是 Claude Code 自己寫的,合併了 259 個 PR (這些說法和數字,Matt Van Horn 在 WTF Is a Loop 裡整理得很完整)。他把這套做法濃縮成幾句: 把 loop 寫一次,給它可呼叫的 skills 和能自我檢查的回饋,設好上限讓它會停,然後放上 cron 跑。一個能直接照抄的起步範例長這樣:
/loop 幫我代管所有 PR。自動修 build 問題,
等有留言進來時,用 worktree agent 來修正它們。
實例: 一個 Maintainer Orchestrator
把這套講得最完整的實例,是 Steinberger 開源的 maintainer-orchestrator skill。他在推文上的描述是: 告訴 codex 維護你的 repos,每 5 分鐘醒來,把工作派到各個 thread; 配上 triage、autoreview、computer use 幾個 skill,部分工作可以全自動合併。
拆開看,它正好把這篇三種實作疊在一起用:
- 它是個 cron + orchestrator: orchestrator 本身只當控制平面,每 5 分鐘 heartbeat 醒來讀各 worker 現況,只負責定時檢查、派工、監控、需要時問人決策。實作全部交給平行跑的 worker thread,而且 worker 不准再往下委派。
- 先過一道 triage: 另一個 github-project-triage skill 把進來的 queue 分三類: 可重現、有界、可驗證的歸 Autonomous 直接派工; 需要產品決策、牽涉安全、或缺權限的歸 Needs owner; 過期、重複的歸 Defer/close,附證據處置。
這套之所以可以讓「部分工作全自動合併」,不是因為大膽,而是靠 harness 設計。它用四道關卡限制自動合併:
注意這四道關卡,沒有一個是這篇外層 Loop 才發明的: live proof 是時機③的獨立驗收 (上一篇 Outcome 那種「裁判真的去操作 artifact」),權限分層和 decision-ready 是把「什麼能自動、什麼要回報」寫成前饋規則 (第二篇),跨 session 記憶是 Ralph 那個進度搬到磁碟的做法。外層 Loop 真正的工作,是把前面幾篇拆過的這些設計,組成一個人不在現場也能安全跑的迴圈。
外層 Loop 不只用在寫程式
前面這些例子,從 Ralph、Symphony、cron 到剛剛的 maintainer orchestrator,清一色都是建在 coding agent 上,因為那是工具生態最成熟的場景。但外層 Loop 的核心跟 coding 無關,而且它的變形非常多: 同樣是定時醒來的 agent,有人拿來整理收件匣、有人拿來監控競品、有人拿來每天產一份情報簡報、有人拿來跑一個全天候執行的主動助理。場景差很遠,做出來的樣子也差很遠,Ralph 的 bash 迴圈、Symphony 的看板、cron 排程都只是其中幾種。
但不管哪一種,核心其實就三個問題,你自建任何一個外層 Loop 都得回答:
- 怎麼被觸發: 固定 cron、動態間隔、還是事件 (webhook、新郵件、CI 失敗、看板上多一張 ticket)?
- 醒來看什麼: 它一醒來,要讀哪些 context 之外的狀態,才知道進度到哪、有沒有新工作? (Ralph 讀 git 和 progress.txt,Symphony 讀看板,主動助理讀 inbox。)
- 做完把結果送去哪: 開一個 PR、寄一封簡報、送進 triage 收件匣,還是沒事就直接歸檔?
把這三個問題對著你的場景回答一遍,就有一個外層 Loop 了,不管它做的是 Text-to-SQL 報表、知識庫監控,還是寫 code。這也是為什麼說它是更廣義的工程: 換掉場景,核心不變。
收尾: loopcraft 的五層迴圈
把這個系列走過的迴圈疊起來看,swyx 在 loopcraft: the art of stacking loops 用一張圖概括了「堆疊迴圈」這件事。由內到外疊了五層,每一層的跳出條件和時間尺度都不一樣:
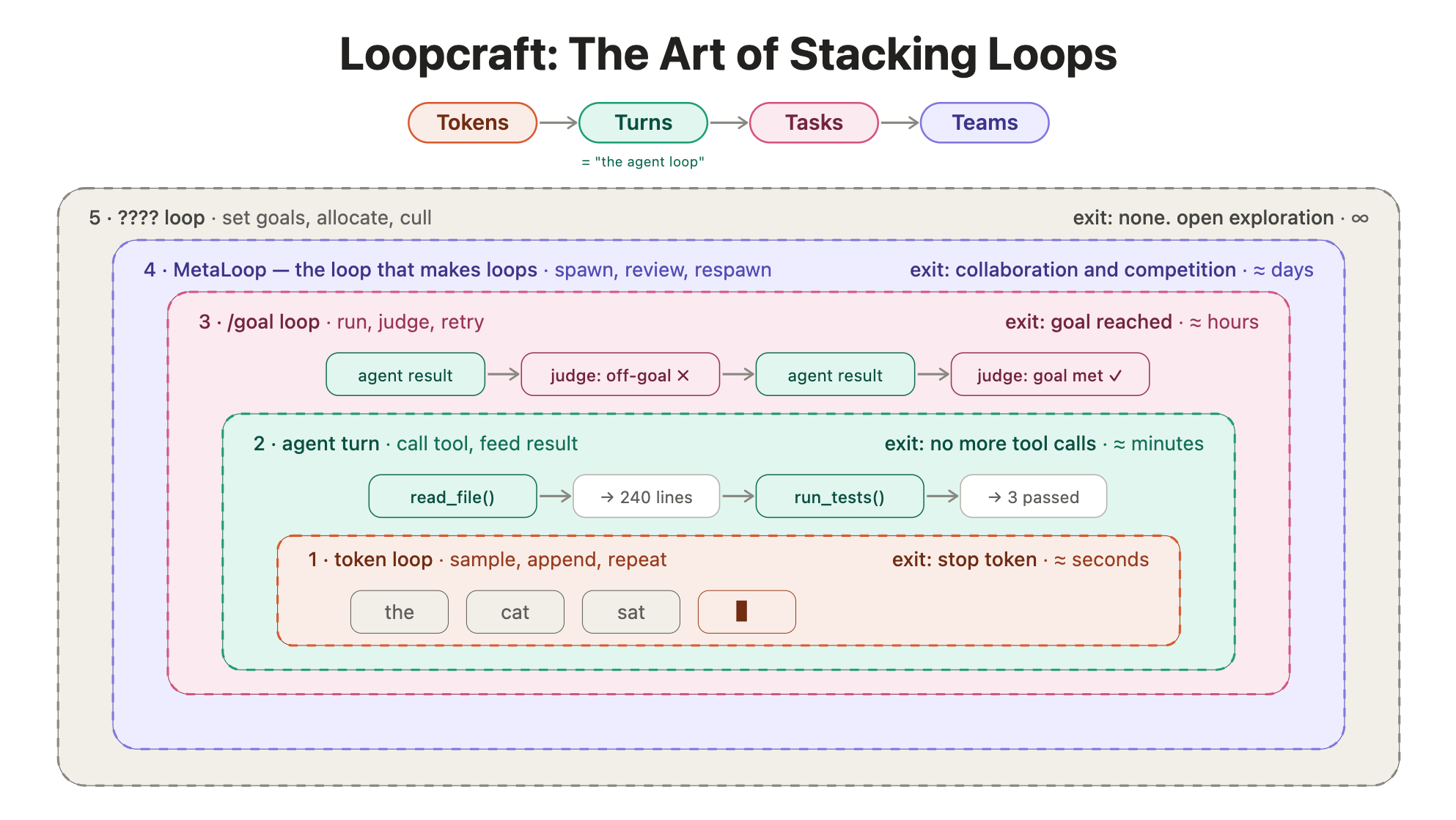
- ① token loop (秒): 模型逐 token 取樣、接上、再取樣,出現 stop token 就停。這層在 harness 底下,是模型自己的解碼。
- ② agent turn (分): 呼叫工具、把結果讀回來,直到沒有工具要呼叫。就是第一篇講的那個「笨迴圈」,時機①的工具層回饋就發生在這一圈裡。
- ③ /goal loop (時): 跑、評、重試,直到判定目標達成。就是第五篇的時機③。
- ④ MetaLoop (天): swyx 給它的副標是「生迴圈的迴圈」,動作是開子代理、審查、汰除。這就是這一篇的時機④,Ralph、Symphony、cron、maintainer orchestrator 全都在這一層。
- ⑤ ???? loop (∞): 定目標、分配資源、汰除方向,沒有跳出條件,開放探索。swyx 自己都還沒給它名字。
五層裡,①②是模型本身就給你的,③成熟的 coding agent 也幫你包好了。ihower 認為,loop engineering 這個詞最想強調的重點方向,就是第④層 MetaLoop,也就是這一篇講的外層 harness: 任務怎麼被觸發、跨 session 的進度怎麼傳、什麼時候算整件事做完,這些都得你自己設計。當然,如果你用的是 coding agent,要做這層最簡單的做法,就是善用它內建的 loop 排程和 goal 功能 (前面講過的 /loop、Routines、Automations 配上 /goal),把排程和終止條件接起來,就不需要自己做了。
編按: LangChain 的 Sydney Runkle 在 The Art of Loop Engineering 給了一個不同的版本 (Agent loop、Verification loop、Event loop、Hill climbing loop),前三層大致對應這個系列的四個時機,而她的第四層 Hill climbing (把生產環境的 trace 送回去修改 harness 本身的設定),正好是下一篇要談的東西。
編按: 寫這篇時本來想把 Claude Code 的 dynamic workflows 也一起講 (它一樣是開子代理、平行分流、審查、汰除這類外層編排)。一方面它自成一個大題目,小編之前也單獨寫過一篇了; 另外就是,站在「自行開發特定場景的 Agent」的角度,ihower 認為 dynamic workflows 不實用: 它那套讓模型即時生成編排腳本、決定性 resume 的機制,是為了當「服務任何任務的通用 harness」才需要的,而自建垂直場景的 agent (vertical agent,例如 Text-to-SQL、訪談、RAG) 時,你本來就知道自己的場景,直接針對它手寫一套確定性的編排就好 (像本文 Symphony 那種貼合場景設計的控制流程),不必靠模型每次即時生成,既便宜可靠又省 token。所以這篇就沒再展開,有興趣的可以看那篇: 從 Code Act 到 Claude Code Dynamic Workflows。